1. 引言
随着大数据时代的到来,来自社交网络、金融数据管理、网络监控等各种实时系统的流数据 [1] [2] 处理需求越来越多,XML流数据得到了广泛的应用,XML数据量也呈爆炸式增长。对于如何高性能的从持续到来的XML流数据中提取出重要的信息也成为了研究热点之一。
XPath是从XML文档当中提取信息的重要的查询语言,许多研究工作的注意力都集中在了如何高效的支持XPath语言对于XML流数据的处理。树模式匹配是XML查询的核心操作,用于从XML文档树当中提取出所有出现的满足树模式的片段的查询,涵盖了XPath语言的主要功能。目前也有许多XML流数据查询算法(TwigM [3] 、LQ [4] 系列算法等),但均不支持多返回结点的情形。
树模式查询算法TwigList [5] 是一种高效的XML查询算法,虽然支持多返回节点的查询,但其针对非流式XML数据,并且空间消耗大。对于流式XML数据,该算法并不适用。本研究基于传统算法TwigList进行了改造,在功能上支持对于PC、AD轴和多返回节点的查询,减少了时空开销,得到高效的XML流数据匹配算法。
论文组织如下:第2节介绍背景知识;第3节介绍了针对XML流数据的树模式匹配算法的设计思路;第4节介绍本文的实验部分;随后介绍了相关工作和总结。
2. 相关工作
关于半结构化数据的Twig查询算法和已经得到深入研究。本文仅介绍与本文关系密切的若干算法。
2007年,Lu Qin等人提出了一种TwigList [2] 算法,该算法针对非流式XML数据,按照后序遍历的顺序处理XML文档。由于TwigList使用了简单的数据结构,能够高效的处理XML查询。但其对与查询结点对应的XML文档结点都建立List元素,使得时空消耗很大。本文是在TwigList的基础上,针对其空间开销大的问题,通过边缘结点放弃建立List,直接到其边缘元素流中找满足查询树的节点,达到节省空间需求的目的。
关于XML流数据的处理,采用自动机是常见的方法,Yfilter [6] 和XPush Machine [7] 通过同时支持多个查询提高了查询效率,但是仅支持简单的XPath查询。Hakuta S.等人提出将XQuery的子集MinXQuery [8] 翻译成森林自动机,研究了基于宏森林自动机的XML流数据处理技术,使得查询执行效率均比之前的算法有较大改善,但不支持多返回节点。相比之下,本文提出的XML流数据匹配算法具有执行效率高、空间开销小的特点,模式匹配算法中采用了新型的数据模型和实现算法。
3. 背景知识
3.1. XML文档树
XML 是一种树型结构的自描述的标记语言,通过定义元素、属性和文本等进行数据信息的说明。一个简单的XML 文档示例如图1所示。
为了描述方便,一个XML文档可以看作是一棵有根、有序、节点带标记的树,树中的节点表示文
档中的素、属性、文本节点等,节点间的边表示元素之间或者元素与文本之间的嵌套关系,兄弟元素间的顺序由树的先序遍历得到。图2(b)所示的文档树与图1所示的XML文档相对应。
定义1:树模式是一种树型的模式,表示为五元组Q = (Node, Lab, tag, axis, var)。其中:
Node是查询节点的集合。
Lab是XML标签集。
tag:NodeàLab函数指定了查询节点的标签。
axis:Nodeà(NodeX{PC, AD})函数定义给定查询节点的双亲或祖先,PC表示双亲子女关系,AD表示祖先后代关系。
var:NodeàVar函数指定了查询节点上绑定的变量。这些变量用于引用树模式匹配的结果。树模式可以采用图形化表示。例如,树模式A->$A[//B->$B][//C/D]可以表示为图2(a);其中,文字符号表示查询节点及其XML标签;圆圈表示返回节点,也就是具有绑定变量的节点;节点之间的单线表示PC关系、双线表示AD关系。于是,该模式规定A、B是返回节点,A节点须有子孙节点B、C,C节点必须有D孩子。见表1。
3.2. 树模式的匹配
树模式匹配就是从XML数据流中检索出满足树模式的文档片段。为了直观的显示树模式作用于XML数据流的匹配结果,这里把XML数据流建模为一颗有根的、有序的、有节点标记的文档树。设置一个虚拟的根节点作为树根,为每个XML数据流中的每个数据项建立一个子树,作为虚根的孩子。树节点代表XML元素,节点的内容代表XML元素标签,连接两个XML元素的边表示这两个XML元素是父子关系。
对于给定的XML文档树D和树模式P,同时满足以下条件的XML节点就是匹配的结果:
对于P中的任何查询节点,在D都可以找标签相同的XML节点。
对于P中的节点x,若axis(x) = (y,PC),则D中对应的XML节点满足双亲子女关系,若axis(x) = (y,AD),则D中对应的XML节点满足祖先后代关系。
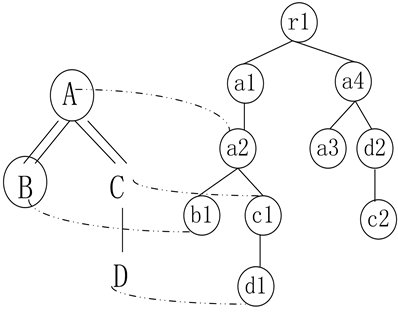 (a) 树模式 (b) XML文档树
(a) 树模式 (b) XML文档树
Figure 2. Tree pattern and XML tree
图2. 树模式和XML文档树

Table 1. The grammar of tree pattern
表1. 树模式的文法
同时,树模式的定义为外部程序访问匹配结果提供了返回节点,也就是处于函数var定义域的节点。外部程序可以通过这些变量,获得匹配结果中不同的XML片段。本文将匹配结果叫做实例树。
图2(b)所示的XML文档树中,节点的数字角标是为了区分同名节点。该文档树与图2(a)所示正规树模式进行匹配将获得2个结果。其中,a1及其子树满足树模式约束,因为a1存在子孙b1、c1,c1存在d1孩子。a2及其子树也满足正规树模式约束,因为a2存在后代b1、c1,并且c1存在d1孩子。
3.3. 查询节点的类型定义
为了算法描述的方便,正规树模式中的节点可以分为四类:
1) 叶子节点:不存在子节点的节点。
2) 单枝节点:子节点的数量为1的节点。
3) 分枝节点:子节点的数量大于1的节点。
此外,查询节点可以分为返回节点和非返回节点,或者边缘节点和非边缘节点。存在绑定变量的节点叫做返回节点。边缘节点包括不带绑定变量的叶结点,以及从这种叶结点到最近的返回节点、最近的分枝节点之间的所有节点。
4. 树模式匹配算法
本节以XML数据流处理为例,介绍XML数据流的树模式匹配方法。
4.1. 流数据处理流程
如图3所示,XML数据流的树模式匹配流程由三个阶段组成。在预处理阶段,系统根据给定的树模式分析输入的XML数据流,过滤掉与树模式无关的XML元素;然后通过边缘节点的开始结束标签驱动边缘分枝匹配算法,其中,startElem()针对边缘分枝节点的开始标签进行处理,endElem()针对边缘分枝节点的结束标签进行处理。这两个函数共同确定存在边缘分枝的非边缘实例树节点是否满足边缘分枝并为其做标记,为模式匹配阶段的筛选做准备,并且将非边缘节点的开始标签和结束标签交给模式匹配阶段处理。在模式匹配阶段,调用toStack()函数处理非边缘节点的开始标签,toList()函数处理非边缘节点的结束标签。他们共同完成树模式的模式匹配,采用实例树保存匹配结果。在第三阶段,系统从实例树中逐个枚举出检测出的每个查询结果。
4.2. 边缘分枝数据模型
每条边缘分枝由边缘节点和边缘节点的最近非边缘祖先节点组成。对于边缘分枝上的每个节点K,设置一个stackK。
如果K是边缘节点,则stackK中的元素是一个三元组enode=(level,point,flagB)。其中,level保存了该元素所在层次,point是指向父亲查询节点V的栈stackV中满足轴约束关系的最近祖先节点的指针,flagB标识该节点是否满足该节点所在的边缘分枝。B是K所在边缘分枝上距离K最远的边缘节点,标识该边缘分枝。
如果K是边缘节点的最近非边缘祖先节点,则stackK中的元素是一个一元组enode = (flags)。其中,flags是n(n是边缘分枝的个数)元索引数组。对于子节点Ki(0 < I < n + 1),若Ki是边缘节点,则数组元素flagKi标识该元素是否满足以Ki为最近边缘后代的边缘分枝。
4.3. 实例树数据模型
本节介绍保存树模式匹配结果的实例树模型。实例树模型采用与树模式相同的树结构。对于每个非边缘节点K,设置一个实例树节点列表LK,这里假设K有n个非边缘子节点。
LK的表元素是四元组node=(elem,starts,ends,brother),表示一个实例树节点qq。其中,elem是标记为K的XML元素,starts、ends都是n元索引数组。对于节点Ki (0 i) = (K,AD),则列表Lki中从starts[i]到ends[i]所指向的每个LKi表元素包含了elem的所有Ki子孙元素;若axis(Ki) = (K,PC),则从starts[i]到ends[i]分别指向的Ki表元素按照brother指针组成一个兄弟链表,包含了elem的所有Ki子元素。
图4是XML流数据处理引擎针对图2(b)所示的XML文档树执行图2(a)所示的树模式查询得到的实例树。A、C、D节点均为边缘分枝上的节点,故分别为其建立栈SA、SC、SD。LA、LB分别是A、B查询节点对应的List。List中存放的元素均满足以该元素为根的树模式子树。LA中每个元素指向LD的startsD,endsD指针之间的B元素均为其后代。LB中a2指向LB的startsB,endsB指针之间的元素均为a2的后代。
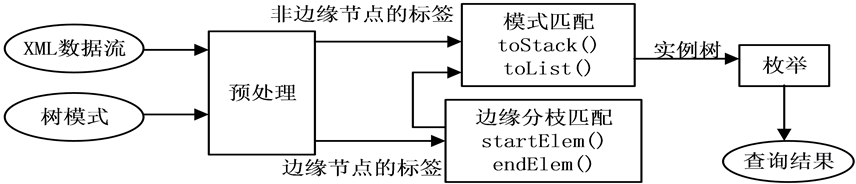
Figure 3. XML stream processing flow based on tree pattern
图3. 基于树模式的XML流数据处理流程
4.4. 边缘分枝过滤算法
在预处理阶段,边缘分枝过滤算法的输入是边缘节点的XML标签和其所在层次。使用到的数据结构是边缘分枝上的节点对应的栈Stack。算法如下:
算法1:startElem(label,level)
1. w的树模式节点->W
2. W的父亲查询节点->V
3. W所在分枝上距离W最远的边缘节点->B
4. if SV.empty()或者SV.top.flagB=true
5. return;
6. if axis(W)=(PC,V)并且(SV.top().level+1)!=level
7. return;
8. 建立节点w,
9. level->w.level,SV.top()->w.point,false->w.flagB;
10. SW.push(w);
11. if W 是叶子节点 then
12. setEdgeFlag(w,W)
算法2:setEdgeFlag(w,W)
输入:边缘分枝上的节点w和节点类型W
1. if W是边缘节点 then
2. W的父查询节点->V;
3. w指向SV中的元素w.point->cur;
4. if axis(W)=(V,AD)
5. while cur存在并且cur.flagB=false do
6. true->cur.flagB;
7. setEdgeFlag(cur,V);
8. SV中cur的下一个节点->cur;
9. else
10. true ->cur.FlagB;
11. setEdgeFlag(cur,V);
算法3:endEBranch(label,level)
1. label的树模式节点->W
2. if SW不空&&SW.top().level=level
3. SW.pop();
算法1用于响应边缘节点开始标签的处理,当w的开始标签到来的时候,如果w与其对应的查询节点W的父亲节点V的栈顶元素stackV.top()满足轴约束关系,并且stackV.top()还不满足边缘分枝时,则执行入栈操作。同时,如果w是叶子节点,会递归调用setEdgeFlag()函数为此分枝上的满足边缘分枝的所有元素设置标识这些元素满足边缘分枝的布尔值。算法3用来响应边缘节点的结束标签。
4.5. 模式匹配算法
如上所述,树模式的模式匹配的输入是非边缘节点的XML标签,输出是保存匹配结果的实例树模型。模式匹配过程中使用了几个数据结构:正规树模式Q、栈STK、存在边缘子节点的非边缘节点对应的Stack以及非边缘节点对应的List。两个核心算法如下:
算法4:toStack(label)
1. 为label构造实例树节点v;
2. v对应的查询节点àV;
3. 构造标识边缘分枝的栈元素->flags
4. for each child W of V do
5. if W 是边缘节点 then
6. flags.add(flagsW = false)
7. else
8. v.startsW = length(LW)+1;
9. if flags.size!=0then
10. SV.push(flags)
11. STK.push(v);
注释:v.startsW表示实例树节点v中starts数组中子节点W所对应的元素。
算法5:结束标签的处理算法toList(label)
1. v = STK.pop();
2. v对应的查询节点àV
3. if check(v, V)=false then
4. return;
5. 将v添加到列表Lv;
算法6:check(v,V)
输入:XML元素v、其对应的查询节点V
输出:布尔值
1. if V 存在边缘分枝
2. SV.pop->flags
3. if flags中存在值不等于true的元素
4. return false
5. for each child W of V do
6. if W是非边缘节点 then
7. v.endsW= length(LW);
8. if v.endsW
W then
9. return false;
10. if axis(W)=(V,PC) then
11. 在v.startsW和v.endsW之间构造兄弟链表;
12. if 兄弟链表为空then
13. returnfalse;
14. return true;
算法5所示的toList函数用于响应非边缘节点结束标签的处理;从栈中弹出当前标签对应的XML元素v后,得到对应的查询节点V,调用check检查以v为根的子树中是否存在以V为根的查询子树的查询结果。当节点v通过上述检查时,则作为中间结果保存到实例树节点列表LV中。
在check函数的处理过程中,对边缘节点和非边缘节点分别进行的检查。前者检查是否满足边缘分枝,后者则检查V子女的实例树节点列表是否存在相应的元素。
图5展示了图2(a)的树模式对图2(b)的XML文档树匹配过程的片段。图中的T、F分别表示true和false。初始时,STK初始化为空,SA、SC、SD、LA、LB也初始化为空。当a1的开始标签到来时,创建a1表元素,设置a1.startsB为length(LB)+1并将其入栈STK,同时,创建a1栈元素,设置a1.flagB = F并将其入栈SA。当a2的开始标签到来时,执行的操作与a1相同。当b1的开始标签到来时,创建b1表元素,并入栈STK。如图5(a)所示。当b1的结束标签到来的时候,b1出栈STK,并加入到LB。当c1的开始标签到来时,由于c1和SA的栈顶元素a1满足轴约束关系,故创建c1栈元素,设置c1.point指向a2,c1.level为c1的层次,flagC为F。当d1的开始标签到来时,同样设置d1.point指向c1,d1.flagC为F。由于d1是叶子节点,依次设置b1.flagC、c1.flagC、a2.flagC、a1.flagC为true。如图5(b)所示。当d1、c1的结束标签到来时,d1、c1分别从SD、SC出栈。当a2的结束标签到来时,设置a2.endsB为length(LB),由于a2.endsB >= a2.startsB并且栈元素a2.flagC = T,所以a2存在B类的后代,并且满足以C为最近后代的边缘分枝。故将a2加入LA的后代,由于streamB中的b1是a1的孩子,故a1满足树模式约束被加入到LA,如图5(c)所示。
4.6. 算法分析
在复杂事件检测方法的开销集涉及边缘分支的处理和非边缘节点的处理。
在时间复杂度方面,非边缘节点的check匹配算法,仅涉及XML子树的一遍扫描,且没有针对XML元素的循环处理,可以在线性时间内完成。边缘节点的匹配算法中,时间开销主要集中在setEdgeFlag,为O(d*n)。其中,d是分支个数,n是边缘分支的元素个数。因此计算复杂度与元素个数成正比。在最坏的情况下,对于XML文档D,树模式的时间复杂度可以达到O(m|D|),其中,m是最大分枝度数。因此,树模式匹配可以在线性时间内完成。
在空间复杂度方面,边缘分枝栈中的元素所占内存空间为O(N1),其中N1是XML数据流中边缘分枝的深度,并且对于非边缘节点元素来说,占用内存空间为O(b*N2),其中b为分枝节点的个数,N2是XML数据流中非边缘节点元素的个数。因此,空间复杂度为O(N1 + b*N2)。鉴于分支节点的数量有限,流数据匹配过程中将随时释放已经枚举的结果,算法的空间开销主要取决于正规节点匹配结果的需求,
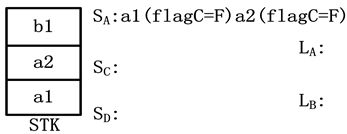 (a) b1开始标记的处理
(a) b1开始标记的处理 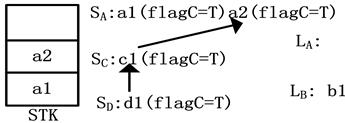 (b) d1开始标记的处
(b) d1开始标记的处 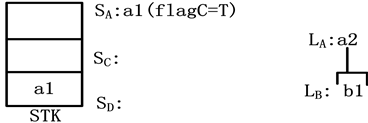 (c) a2结束标记的处理
(c) a2结束标记的处理
Figure 5. State change in matching process
图5. 匹配过程的状态变化
与匹配元素序列的长度和匹配结果的数量成正比。
5. 流数据匹配结果的获取
每当处理正规树模式的根节点的结束标签时,则调用算法Enum获得并输出匹配结果,通过Enum(x,v)可以获得实例树x中指定变量v的绑定值,具体算法如下:
算法7枚举算法Enum(x,v)
输入:实例树节点x, 绑定变量v
输出:匹配结果
1. if v与x的子女y绑定 then
2. return x中y对应的实例树节点列表
3. 建空集合s;
4. for each z in x的子女
5. 将Enum( z, v )添加到s;
return s;
6. 实验
本节对基于正规树模式匹配的复杂事件检验方法进行不同的对比实验,并对实验结果进行简要分析,说明本方法的正确性和高效性。案例见表2。
6.1. 实验环境
实验环境为一台配有Intel Core i7-2600 3.40GHz CPU,12G内存的Windows 7 PC,Java运行环境(JRE)版本1.6。实验数据采用的数据集是3个XML基准数据集,分别是两个真实数据集DBLP和TreeBank,以及一个根据参数人工生成的数据集Xmark (见表3所示)的流数据集。
表2. 树模式测试案例
Table 3. Three XML baseline data set
表3. 三个XML基准数据集
待测试的树模式查询用例是包含PC、AD轴和存在谓词的XPath查询。采用流式的TwigList算法和本论文提出的流数据匹配方法作对比。其中,流式的TwigList算法是本课题研究为了进行对比实验,对TwigList算法进行了改造,使TigList算法能够针对流数据进行查询处理。
6.2. 测试结果及分析
本测试以XML数据流的查询执行时间和内存消耗作为衡量算法高效性的依据。其中,有效执行时间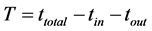 ,其中,ttotal为XML数据流处理的总时间,tin为从磁盘上读入XML文档并对其进行解析的时间,tout为从内存向磁盘中输出查询结果的时间。
,其中,ttotal为XML数据流处理的总时间,tin为从磁盘上读入XML文档并对其进行解析的时间,tout为从内存向磁盘中输出查询结果的时间。
图6、图7分别反映了针对Q1.1~Q3.5分别执行流数据匹配方法和流式TwigList算法的执行时间、内存消耗对比。从图中可以看出,流数据匹配方法的执行速度优于流式TwigList算法,并且内存消耗也小于TwigList算法。
7. 结论
针对大数据时代半结构化流数据处理中数据量巨大、价值密度低等特点,本文提出一种新型的XML
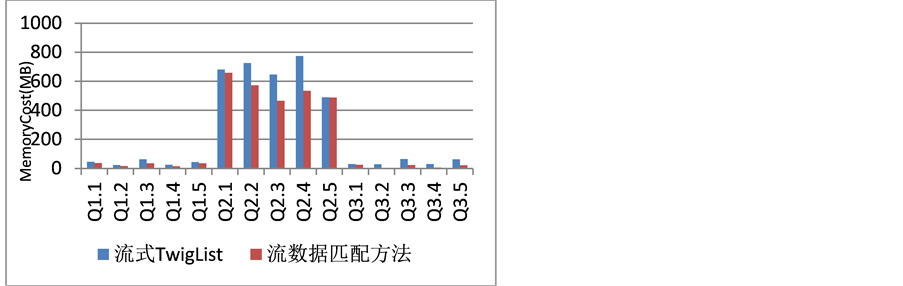
Figure 7. Memory consumption comparison chart
图7. 内存消耗对比图
流数据匹配算法,捕获XML数据流中指定树模式,满足了流数据处理的性能需求。实验表明,本方法在满足树模式查询空间开销小的同时,保证了查询的执行效率。