1. 引言
根据360发布的《2015年中国手机安全状况报告》 [1] 显示:
2015全年,360互联网安全中心累计截获Android平台新增恶意程序样本1874.0万个。分别是2013年,2014年的27.9倍、5.7倍。平均每天截获新增恶意程序样本也高达51,342个。
2015全年,360互联网安全中心累计监测到Android用户感染恶意程序3.7亿人次,分别是2013年、2014年的3.8倍和1.1倍;平均每天感染量达到了100.6万人次。
在所有手机恶意程序中,资费消耗类恶意程序的感染量仍然保持最多,占比高达73.6%;其次为恶意扣费(21.5%)和隐私窃取(4.1%)。
恶意应用的开发者们不断的开发着新的恶意代码,新的木马病毒样本不断被发现。从恶意扣费、窃取隐私、隐式安装恶意软件、窃取网银密码等到远程控制操作用户的手机。Android智能手机不仅仅给用户带来了方便也导致了Android安全问题越来越严重。Android手机上恶意应用的检测越来越被人们所重视。
机器学习算法可应用于Android平台上恶意代码检测,例如朴素贝叶斯算法(Native Bayes NB算法)。但朴素贝叶斯算法存在着较高误判率的缺陷 [2] ,本文提出了应用改进的朴素贝叶斯算法进行机器学习,对Android软件进行字节码级别的静态分析后,提取出软件的特征值信息作为样本特征。本文基于该原理实现了对Android应用进行恶意应用检测的框架,对Android软件进行特征码扫描后,通过基于改进的朴素贝叶斯算法分类器的判定区分是否是恶意应用,从而有效提高了恶意代码检测的精确度,降低了误判率。
2. Android恶意应用检测技术
Android恶意代码的检测一般分为静态检测和动态检测,在此基础上一般采用特征值检测技术和基于启发式的检测技术这两种方式 [3] 。
2.1. 特征值匹配技术
特征值检测是目前大多数反病毒产品普遍使用的检测技术。该技术的主要工作原理是根据特定的规则对目标文件进行扫描,并提取出特征值,与病毒库中已有的特征按照某种匹配算法进行完全匹配或者计算出相似度,若得到完全匹配或者相似度超过规定的阈值,则表示检测为病毒文件 [4] 。所以特征值匹配需要分析大量的样本,并且不断的更新特征库,特征值匹配技术原理比较简单,而且在一定情况下具有容易实现,准确率高等众多优点。但是这种技术过分依赖于对特征值提取的精确程度,具有一定的不稳定性,而且对新出现的恶意代码的检测效果不理想。
2.2. 基于启发式的检测技术
启发式的检测技术包含动态和静态启发检测,静态启发是指对Android apk文件进行反编译生成smile代码和java代码,通过对文件外部静态信息分类,模拟跟踪代码执行流程来判断是否为恶意软件 [5] 。动态启发是指在系统中设置若干的特征点来监控软件行为,通过软件的恶意行为来判断是否是恶意软件。常用的启发式检测技术基于机器学习算法例如神经网络、朴素贝叶斯算法、决策树等。
3. 朴素贝叶斯算法分析与改进
3.1. 基本原理
朴素贝叶斯算法是目前公认的最简单而且有效的概率分类方法 [6] 。它是一种假定各个因素之间不存在任何联系,即完全独立得到的一种简化的贝叶斯算法。可以将朴素贝叶斯分类器应用于恶意代码的过滤,利用这种方法可以根据结果集自动学习,因此需要一定的恶意代码库来提取恶意代码的特征值来训练过滤器。
朴素贝叶斯方法是基于最小错误概率规则,尽量降低分类犯错误的概率。朴素贝叶斯方法通过在程序中的恶意代码的特征信息来计算程序中包含恶意代码的可能性。当判断某段代码是否是恶意代码的时候,利用提取出的特征集合A。定义B代表所有类别的一个随机取值,B代表的是恶意样本或者普通代码,进行机器学习的目的就是计算P(B|A)来判断B是恶意代码还是普通代码。由贝叶斯公式可得,
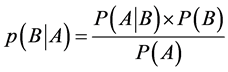 公式2.1
公式2.1
由于贝叶斯公式的条件是特征集合A中的各个特征值相互独立,如果软件样本包含多种属性A1,A2,A3…An
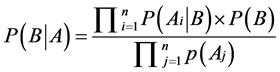 公式2.2
公式2.2
从中选取最大概率作为其分类。
3.2. 朴素贝叶斯算法的改进
在恶意代码的实际分类中,由于只有两类即是否是恶意代码,所以相应的会出现两种分类错误:1)将恶意代码判断成正常代码;2) 将正常代码判断成恶意代码;如果是将恶意代码判断成为正常代码,就会带来严重的后果,使用户信息丢失等等。在传统方法中一般当P(B0|A)>P(B1|A)时就判定是否是恶意代码,但是这种方法并不精确存在很高的误判率和漏判率所以直接应用时分类偏差会比较大。
为了更准确的识别恶意代码,减少误判,设当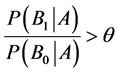 时 [7] ,即当恶意代码的概率是
时 [7] ,即当恶意代码的概率是
非恶意代码的θ倍时,将其判定为恶意代码。当θ越大,其为恶意代码的可能性就越大。由上述公式可以表示为,
 公式2.3
公式2.3
 公式2.4
公式2.4
也就是当P(B1|A) > h时可以判定此应用为恶意Android应用。
4. Android恶意代码静态检测系统的设计
4.1. 生成恶意代码检测分类器
通过对训练样本进行分析,得到样本的特征值集合,流程图如图1所示,首先收集Android的恶意软件的样本集,对样本集进行逆向分析,在分析出的信息中提取出分类器需要的信息特征,将这些特征作为分类器的样本输入,经过改进的朴素贝叶斯算法处理之后得到Android恶意软件的检测分类器 [8] 。
4.2. 应用分类器对Android应用进行检测
当测试是否是恶意应用时,需要先对测试的样本进行逆向分析,提取出特征信息,送入分类器进行检测。流程图如图2所示。

Figure 1. Malicious code detection classifier generation
图1. 恶意代码检测分类器的生成
4.3. Android应用的静态逆向分析
APK文件的反编译可以使用dex2jar把classes.dex文件反编译为java代码,反编译成功后的代码可以通过jd-gui进行阅读 [9] 。使转化后的java代码清晰易懂;或者把classes.dex文件反编译为smali代码,smali代码是一种面向对象的汇编代码,其可读性较强,修改后的smali代码还可以重新打包和签名生成新的APK文件 [6] 。反编译成smali代码常用的工具是apktool,此工具集合了解压缩XML、文件解析、smali正反编译、组装等各个功能。运用反编译工具可实现对apk文件的反编译,从而提取出所需要的特征信息,对其所申请的权限进行分析,运用字符串的比较算法比较签名等从而得到最终结果。
5. 试验与结果分析
通过网络收集到的软件样本600个,其中有恶意应用300个,合法应用300个。得出基于朴素贝叶斯算法的实验结果如表1所示。
由表1得知,应用朴素贝叶斯算法时,300个恶意应用中仍然有35.5个被判定为合法应用,300个合法应用中有37.7个被判定为恶意应用。实验数据说明了朴素贝叶斯算法存在着一定的缺陷。
由公式2.3和2.4可得h的范围是0~10,所以需要大量的实验来得到h值的大小。从中选取了部分h值实验结果如表2所示。可得当0 < h < 0.35时分类器的判断正确概率接近100%。

Table 1. Experiment based on naive Bayes algorithm
表1. 基于朴素贝叶斯算法的实验
Table 2. Experiment based on improved naive Bayes algorithm
表2. 基于改进朴素贝叶斯算法的实验
6. 结束语
本文对现有的恶意应用的检测技术进行了分析,在一种朴素贝叶斯算法的基础上提出了一种改进型的朴素贝叶斯算法,并设计了一个检测系统对该改进算法的优势进行了检测。提高了恶意应用的检测概率,但是也存在着将合法应用判定为恶意应用的误差,这是算法需要进一步改进的地方。