1. 研究背景及意义
本文从以下五个方面进行分析及研究,第一部分:课题研究的背景及意义,研究方法和思路还有近年的就业数据。第二部分:全国高校就业及贵州高校就业情况的分析,用相关数据图表分析全国的就业情况,用R作出贵州就业的相关图像最后得出ARIMA模型分析贵州高校就业情况,最后把全国和贵州的就业情况作出直方图来对比。第三部分:对中国热门职业、地域、行业的分析,用聚类的方法,聚出词频和权数,词频和权数最高的即为热门。第四部分:就业难的原因分析,就业难的原因有政治、经济、家庭等因素。第四部分:解决贵州高校就业难的对策及建议,本论文根据贵州省的具体情况,从教育、高校毕业生本身等几个方面提供了促进贵州高校毕业生就业的对策及建议。
自20世纪90年代以来,就业难问题日益严峻,根据2004年发布的“全球就业趋势”报告指出2003年全球青年失业率达8800万人,比1993年增长了26.8%。根据发布的白皮书显示,到2003年年底,中国城镇失业率为4.3%,失业人数高达800万;其中35岁以下的青年占70%。2015年据我国统计局统计,该年1~2月全国31个大城市城镇调查失业率继续稳定在5.1%左右。
贵州的就业情况也不容乐观。为解决这个问题,从2012年起,贵州省实施7个项目,即是:1) 选聘高校毕业生到村任职计划;2) “一村一名大学生工程”;3) “大学生志愿服务西部计划”;4) “三支一扶”计划;5) “高校毕业生就业见习计划”;6) “教师特设岗位计划”;7) “选调生工作计划”。我省将逐年递增选调高校毕业生,到基层党政领导机关工作。
目前,我国正处于稳定发展的关键时期,一切的稳定都将是促进社会进步的基石。因此,高校毕业生就业问题已成为学生,家长,社会以及整个国家关注的焦点。
2. 全国高校就业及贵州高校就业情况的分析
(一) 研究全国高校的就业情况
由表1可看出全国毕业人数在逐年的上升,说明高校在扩招,有的高校降低了录取分数线,导致了

Table 1. Employment list of graduates of colleges and universities in China in 2001-2015
表1. 2001~2015年全国高校毕业生就业情况一览表 [1]
毕业生的质量有所下降。就业人数有起伏呈现出不稳定的状态,2012年就业人数达到最高438万人,2001年达到最低82.8万人。未就业人数的变化是无规律的,2001年未就业人数最少,因为那时人才的需求量还挺多的,所以未就业人数相比之下较少;2015年未就业人数最多达到了375万人,因为此时,人才供大于求了,所以导致了该情况。就业率也是有波动的,2006年就业率达到最高78%,因为2006年中国废除了粮食税;2014年就业率达到最低49%。
由图1可以看出全国毕业生人数在逐年上升,因为全国人口在逐渐增加,还有高校在扩招,人们的教育意识在加强。就业人数在2001~2012年呈上升的趋势,但在2013~2015年基本保持不变。未就业人数在2012年到2013年上升得最快,在2013~2015年基本持平。
其中,S为供给量,D为需求量 [2] 。
由图2可知,在均衡点B处,供求关系达到饱和状态,此时,供与求相等。在 B阶段需求量大于供给量,供小于求,人才需求量不够。在B点之后供大于求,此时,人才过剩,就像2015年那样未就业人数还有很多。
如图3所示,由于高校毕业生人数大量的增加,供给曲线由S移到了 。虽然社会的需求也有所增加,但是幅度十分有限,在该情况之下,需求曲线由D移到 。供给曲线和需求曲线在 处达到新的平衡点。与原均衡点B相比,均衡的价格有所下降,由原来的O 变为O 。
(二) 研究贵州高校的就业情况
由贵州教育网及贵州人才招聘网贵州教育网等整理得到贵州2002~2015年的高校毕业人数、就业人数等如表2所示。
由表2可以画出不同年份的毕业人数及就业率的折线图如下。
由图4可知,毕业人数在2002~2008年和2010~2015年呈逐渐上升的趋势,但在2008~2010年出现
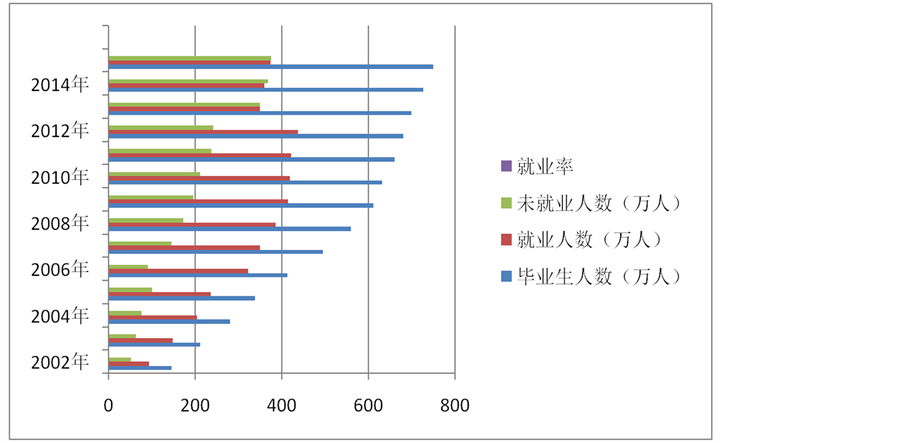
Figure 1. 2001~2015 related situation of national employment
图1. 2001~2015年全国就业相关情况
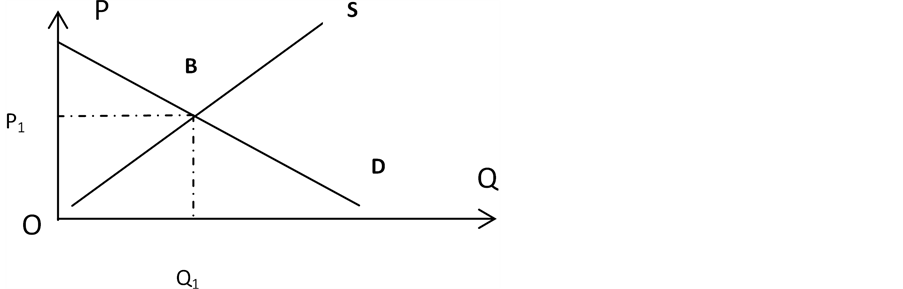
Figure 2. The supply and demand curve of the basic saturation of college graduates
图2. 高校毕业基本饱和时的供求曲线
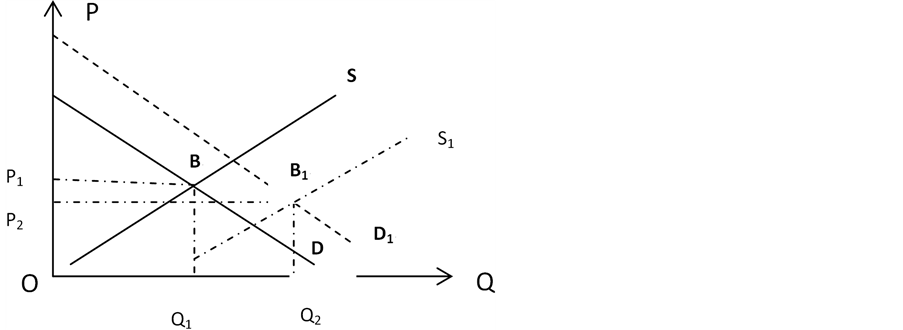
Figure 3. Supply and demand curves of the university graduates after a significant increase
图3. 高校人数大量增加后的供求曲线
Table 2. Guizhou university graduation and employment rates from 2002 to 2015 [3]
表2. 贵州2002年到2015年的高校毕业人数及就业率 [3]
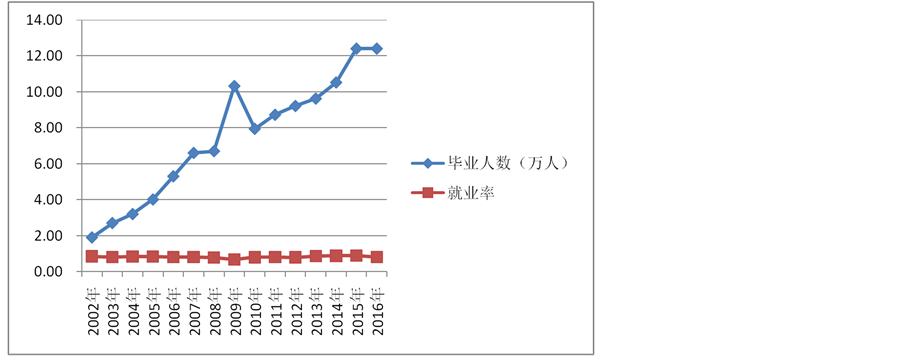
Figure 4. The line chart of the number of graduates and the employment rate of Guizhou during 2002-2016
图4. 2002~2016年贵州毕业人数及就业率的折线图
了很大的拐点,因为2009年出现了金融危机,所以它的前后年均受到一定的影响。就业率基本保持一个稳定的趋势,在2009年的就业率达到最低,因为有金融危机。
由图5可看出2002~2016年贵州高校就业率的时序图具有趋势性,有上升的趋势和下降的趋势,由此可知该序列是非平稳的。所以对该序列进行差分就可以得到平稳的序列。
由图6知该序列还是非平稳的,因为该序列还具有趋势性,所以还得继续差分,直到得到平稳的序列为此。
由图7可看出,该序列始终在一个常数值附近随机波动,而且波动的范围有界的特点,还有该序列
不具有周期性和趋势性可知,该序列是平稳的,因此可以做接下来的分析。
利用R软件做出该序列2阶差分后的自相关图和偏自相关图(如图8和图9所示),是用于给模型定

Figure 5. The time sequence chart of the employment rate of colleges and universities in Guizhou from 2002 to 2016 [4]
图5. 2002~2016年贵州高校就业率的时序图 [4]
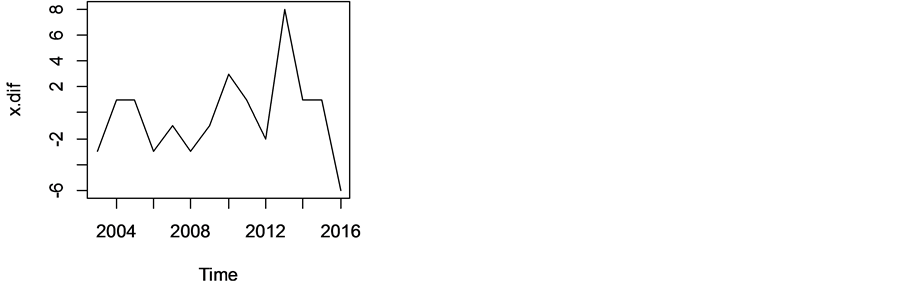
Figure 6. The time sequence chart of the employment rate of college students in Guizhou after the first order difference from 2002 to 2016
图6. 2002~2016年贵州高校就业率一阶差分后的时序图

Figure 7. The timing chart of Guizhou college employment rate of after two-order difference during 2002-2016
图7. 2002~2016年贵州高校就业率二阶差分后的时序图
阶,得出模型的初步形式,再对模型进行拟合(如图10所示),最后对模型进行残差白噪声检验(如图11所示),检验模型是否合理。
由图8可知,在0阶和1阶时值都比较大,0阶时超过了两倍标准差,1阶时接近两倍标准差,其他值都在两倍标准差之内,所以自相关图是1阶结尾的,则可判断它是AR(1)模型。
由图9可知,2阶差分后落在小于0的值比较多,而且都在2倍标准差之内,所以偏自相关是拖尾的。
综上所述,自相关为1阶结尾,偏自相关为拖尾,而且都是经过2阶差分后变为平稳序列的,所以贵州2002~2015年就业率的模型可初步为ARIMA (1, 2, 0)。
由图10可知, 的系数为−0.4838,均值为0,方差为16.37,
的系数为−0.4838,均值为0,方差为16.37, 的系数为1。
的系数为1。
由图11可知,P > 0.05,所以该序列为残差白噪声序列,即该序列中不携带任何有效信息了,信息提取完整,所以该模型是有效的。

Figure 8. The self-related diagram of employment rate in Guizhou after 2-order difference during 2002-2015
图8. 贵州2002~2015年就业率2阶差分后的自相关图

Figure 9. Partial correlation of Guizhou’s employment rate during 2002~2015 after 2-order difference
图9. 贵州2002~2015年就业率2阶差分后的偏相关图
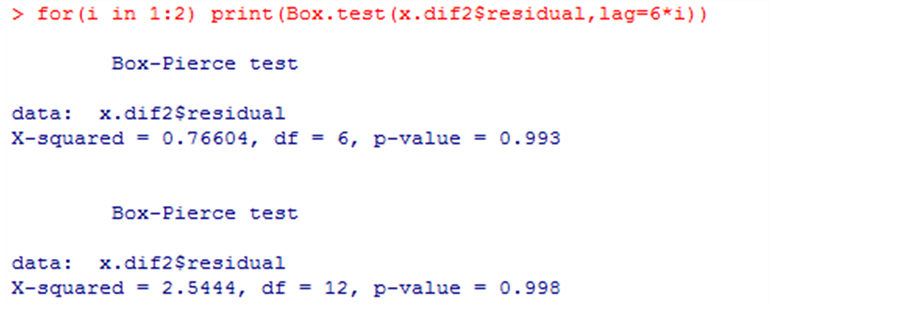
Figure 11. Residual white noise tests after 2-order difference
图11. 2阶差分后的残差白噪声检验
拟合后的模型为:
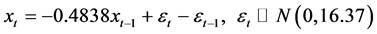
该模型中x为就业率,我们只要已知前一年的就业率,就可以计算出后一年的就业率,这样我们可以提前知道贵州的就业情况,这样我们可以适当的对高校招生人数做适当的调整。
我们把全国和贵州的就业情况作对比,可以得到下图。
由图12知,全国的就业率比贵州的就业率低,这是因为贵州是相对落后的地区,经济相对落后,目前的人才需求量相对于全国来说,还是比较好的。在2006年时全国的就业率达到最高,2013~2015年的就业率差不多,都是2002~2015年这个阶段的最低,因为此时人才的供大于求。贵州省的高校就业情况先降后升,因为近几年贵州才发展起来,但贵州的就业情况也不是很乐观。
3. 对中国热门行业、地域、职业的分析
(一) 人才需求的特点:
1、能与国际接轨型人才的需求,
2、当今社会需要运用能力强的技术人员,
3、需要创新型人才、领军型人才和综合型人才的需求量比较大,
4、像研发性的人员需要提高一定的层次,
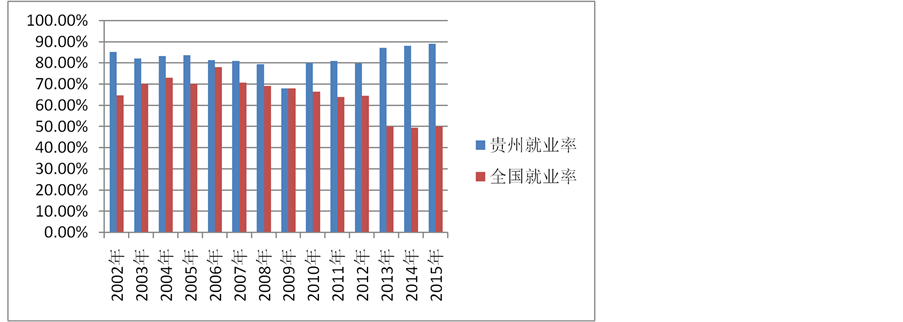
Figure 12. Column chart of the employment rate of Guizhou and the nation
图12. 贵州及全国的就业率的柱形图
5、普遍需要高技术人员和掌握前沿技术的人员。
(二) 当今社会所需人员名次:
1、增值服务业、通信方面,
2、互联网电子商务,
3、电子网络设备、通讯,
4、电子及微电子技术,
5、计算机行业(如软件、数据库、系统集成等),
6、商务、贸易、进出口方面,
7、科研院所、培训、教育,
8、能源、矿产业、电力,
9、媒体影视制作、新闻出版,
10、美容、医疗、卫生服务。
由当今社会所需人员名次知,IT行业人才需求量比较大,因为1、2、3、4、5都属于IT行业,由此可知,IT行业在当今社会还有很大的上升空间。
我们可以把职业分为职能、市场与营销、运营、设计、金融、技术、产品、其他八个职业类型;按专业领域可分为:职务、法务、高端职能职位、行政、人力资源、编辑、运营、客服、采购、公关、市场营销、投资、销售等。如图13所示。
由图13可以清晰的看出职业类型和专业领域的分类,这只是由网络招聘的一部分数据来进行分类的,因为数据太多太大,所以在此没有列出来。
用eclipse进行编程实现聚类分析。
聚类思想、框架和过程如下:
思想:聚类即是将数据的多个分组或者簇中具有共同特征的聚为一类。目标:在同一个簇中的对象之间具有较高相似度,不同的簇差别比较大。聚类的算法主要包括等级聚类和动态聚类,在本文中采用的是动态聚类法基本思路如图14所示。
聚类的步骤:
1) 确定聚类的个数K,选举K个文档作为聚类的中心,把每一个聚类中心文档制成一类;
2) 选举下一个文档按就近的原则,将剩下的N-K个文档逐个导入到最近凝聚点所代表的类中。没导入一篇文档,立刻计算该类的中心,并用该中心代替原来的凝聚点;
3) 把最后形成的每一个凝聚点代表一类,之后将全部N篇文章重新聚类。若文本集合被重新聚类后与原来的聚类结果不同,就重复步骤3,否则积累处理结束。
聚类的过程如图15所示。
本文聚类的过程当中本论文参考了 [5] K-Means算法的思想,具体过程如下:
1) 文本信息的预处理
文本聚类首先要处理的问题是如何将文本内容转换成数学上可分析处理的形式,即是建立文本特征,用一定的特征项来代表文本信息。建立文本信息,常用的方法是:文本信息预处理(词性标注、词义标注),统计词频,对文本词条切分,完成分词过程。中文的处理,Lucene中的中文分词组件je-analysis.jar可以对词条切分,它的分词方法主要有以下两种:
MMAnalyzer analyzer=new MMAnalyzer():
//采用最大匹配的中文分词算法,即分词粒度等于0
MMAnalyzer analyzer=new MMAnalyzer(intwordLength):
//参数为分词粒度:当字数等于或超过该参数,且能成词时,该词即被切分出来了
分词粒度即是词与词之间的相似度。
2) 文本信息特征的建立
文本信息特征模型有多种,如布尔逻辑型、向量空间型、概率型及混合型等等。向量空间型用得比较多,该模型的思想是:将每一个文档映射为由一组正交词条构成的向量空间的一个点。对于所有的文档类和未知的文档,都可以用此空间的词条向量(L1,W1,L2,W2,…….,Ln,Wn)来表示(其中,Li为特征向量词条;Wi为Li的权重)
3) 文本信息特征集的缩减
VSM将文本问题转换成了数学问题,但文本向量特征集的维数比较多。因此,在聚类之前需对文本向量特征集的维数进行缩减。把权重进行排序,选取预定数目的特征子集。
4) 文本聚类
对于给定的文件集合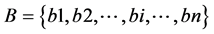 采用层次凝聚法进行聚类,聚类的过程如下:
采用层次凝聚法进行聚类,聚类的过程如下:
a) 将B中的文件Bi看成具有单个成员的簇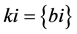 ,这些簇构成了B的一个聚类
,这些簇构成了B的一个聚类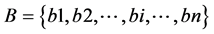 ;
;
b) 计算B中每对簇(bi, bj)的相似度 ;
;
c) 选取相似度最大的簇对(bi, bj)将bi和bj合并为一个新的簇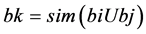 ,从而构成了B的一个新的聚类
,从而构成了B的一个新的聚类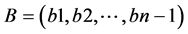 ;
;
d) 重复上述步骤,直至B中只剩下一个簇为止。该过程就构造出了一颗生成树,其中就包含了簇的层次信息和所有簇类及簇间间的相似度 [5] 。
聚类得到的结果如下:
由表3可知,在热门职位中最热门的是开发,因为开发出现的词频最多为160389次,所占的权重也最大为8.3076,所以说开发行业在已有的这些职位中最热门,其余的职位用同样的方法即可得。
表4显示,北京作为最热门的城市,因为北京招聘达到了85,888次,权重为7.8747,比二线城市如沈阳高出了85,637次。由表可以看出最热门的地域是北京,其次为上海,但与北京还是有一定的差距。
由表5知,技术行业为最热门的行业,因为技术词频为219514最大,权重也最大为8.5252,其次为销售,之后为市场,最后为运营。
对于贵州的热门职位和行业我们也可以用类似的方法来做。
Table 3. Analysis results of top job
表3. 热门职位的分析结果
Table 4. Top geographical analysis results
表4. 热门地域的分析结果
4. 就业难的原因分析
就业难的原因集中在社会经济环境、政治体制、毕业生家庭、毕业生自身和高校的培养质量等
(一) 社会经济环境
贵州省地处西部,属于典型的 [6] “欠发达,欠开发”,经济总量小,人均占有量更小,二三产业不发达,结构产业低,地区发展不平衡,存在的就业矛盾非常突出。
(二) 政治体制
毕业生就业难与政治体制也存在一定的关联, 政府部门应加强宏观管理、统筹、调控等服务功能,发挥其主导作用,而高校毕业生已经作为人力资源进入人才市场,但由于贵州经济落后,人才就业管理体制尚未理顺,在劳动人事、户籍、住房、医疗、保险等方面体制不完善,影响了毕业生就业范围的选择,造成了就业难的问题。
(三) 毕业生家庭
很多家庭对毕业生就业问题困难意识淡薄,总是相信就算找不到工作,也可以回家啃老。不鼓励他们创业,希望他们找份稳定的工作,安心养家就行,其次贵州经济条件差,就业难,这样许多毕业生就有理由呆在家里,整天无所事事,这些也是导致就业难的现象。
(四) 毕业生自身
由图16可知,有28%的高校毕业生对就业前景持一般的态度,有20%的人不清楚,乐观和不乐观各持26%,由这些数据可知高校毕业生得改变自己就业前景的态度,这样可能会收到意想不到的效果。
(五) 高校的培养质量
贵州的教学内容滞后于社会发展和市场需要,学科与专业结构不合理的现象一直不同程度的存在,而且专业设置、教学内容、教学方法、教学条件相对较差。而且就业思想教育不够完善,在教育上缺乏对毕业生的职业理念、人生价值观、就业观、成才观、创业观等的培养,就业思想上缺乏系统性、针对性、可接受性不强就会在总体上淡薄毕业生的就业观念,从而导致就业难。
5. 解决贵州高校就业难的对策及建议
从以上分析中,我们可以看出当前高校毕业生就业难的原因是多方面、多层次的。总的来说,就业难的原因集中在社会经济环境、政治体制、毕业生家庭、毕业生自身和高校的培养质量等。其中高等培养质量是引发学生就业难的直接原因,社会和家庭是学生就业难的客观原因,毕业生自身的不足是导致就业难的主观因素。因此,要解决毕业生就业难的问题的对策,仅单方面的努力是不够的,应做好以下几个方面的问题:
(一) 加强就业指导,树立就业观,完善就业指导内容。
Table 5. Top industry analysis results
表5. 热门行业的分析结果
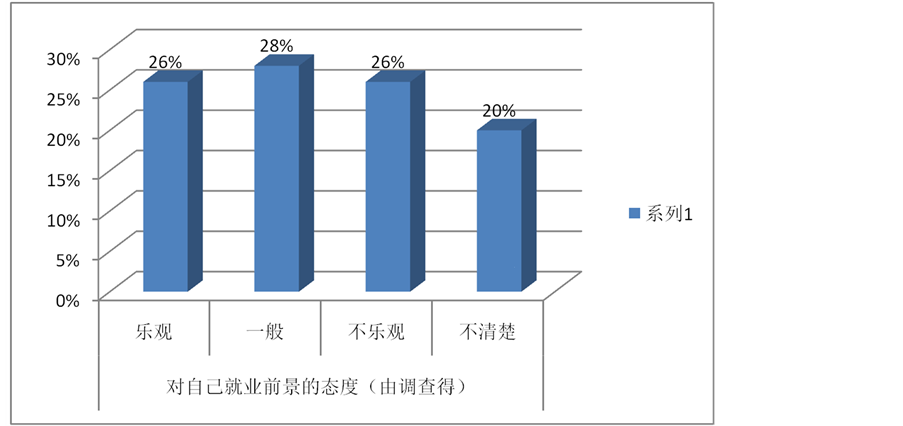
Figure 16. Attitudes to their employment prospects
图16. 对自己就业前景的态度
加强贵州省大学生就业指导是大学生就业稳定,充分就业的需要 ,贵州省一部分大学生没有岗位需求,一部分学生不愿外出流入到其他省市就业,一部分就业单位聘用不到毕业生。“有业不就”和 “无业可就”的现象并存。加强大学生就业指导,应从起点抓起。学校可以通过就业形势分析,就业讲座,就业报告等明确自己的人生定位树立努力的方向。
(二) 培养学生创业能力
学校应加强注重学生技能和学习方面的能力培养,做到理论与实践相结合。双面提升学生的学习能力和实践能力。学校可以通过校企合作,为学生实践能力培训创造良好的实习平台。
(三) 营造良好的社会氛围
家庭教育也是学生能力培养的一个关键部分。我省是一个教育水平相对落后的省份,大部分孩子的父母都未接受过教育。想让学生能够毕业后更快地融入到社会当中,就得让学生拥有一定的能力和技能。为了让学生能够得到更好的发展,应从小培养学生吃苦耐劳的能力,有了坚强的体魄和不怕吃苦的精神。这必将是学生以后发展道路上最可贵的财富。
(四) 毕业生要准确定位,提高自身素质
大学生要自我分析,为自身定位,通过对自身的各项能力的综合评定,找到最适合自己的发展方向,适应社会的发展。
(五) 加强大学生心理健康教育,提高大学生就业的心理素质
就业压力成为大学生就业压力的首要烦恼问题,在实际就业过程中,许多大学生因就业问题引起的心理障碍题和心理问题逐渐上升。虽然大部分大学生已近充分意识到过去传统保守的就业模式已经不适合现在的就业模式,只有敢于挑战自己才是当今社会发展的硬道理。
(六) 努力奋斗,培养自身就业能力
大学生要想在求职竞争中取胜除了有良好的心理素质,还得有过硬的知识和技能基础。要想踏出学校大门就能马上置身于工作当中去,首先在校期间应多多关注社会上对各种人才的需求,分析需要什么样的知识人才,结合自身情况,找出自己的不足和优点。有针对性的学习,不断地完善自我。把握住社会的就业形势,这才能让自己在就业竞争之中有一定的胜算。
6. 总结
通过以上的分析与概括,我们知道了导致贵州高校毕业生就业难的原因有哪些,为了有可比性,我们对全国高校毕业生的就业难情况也做了分析。此外,还用了聚类的方法分析出了中国的热门行业、地域、职业。由本文的分析可知,ARIMA模型是显著的,所以用来分析贵州高校的就业率是有效的。今后知道怎样去调整高校毕业生就业难的情况,使高校的就业率达到更高的水平。
基金项目
贵州师范学院自主研究项目(项目编号:2016DXS095);贵州省2014年省级本科教学工程项目“计算机科学与技术”专业综合改革(项目编号:黔教高发[2014]378号);卓越工程师教育培养计划项目(黔教高发[2013]446号)。