Abstract:
Using multi-source of monthly precipitation data on the basis of preliminary integration and quality control, monthly precipitation time series covering 1913-2014 at Baoding station are interpolated by both two approaches of standardized method and multivariate linear regression. The interpolation results analyzed by cross validation are that the method of multivariate linear regression is more right for precipitation data. Then, the better interpolated time series are homogenized by the penalized maximal F test (PMF), and results indicate that those monthly hundred- term precipitation data are relatively continuous. Moreover, we compare the data here with the homogenized monthly precipitation data during 1913-2014 at Beijing and Tianjin stations from some aspects of trend change, showing that the data we constructed in this paper are relatively logical and errorless.
1. 引言
长时间连续的气候时间序列是进行气候分析和气候变化研究的基础。近年来,我国学者对中国区域或局地气候变化做了大量的研究工作,但分析的数据主要起始于20世纪50年代以来,这对于深入系统地研究我国气候变化特点及预测未来的气候变化趋势是缺乏可靠观测依据的。由于特殊的历史原因,我国建国前的历史气候序列缺测较多,同时,由于观测台站迁移、仪器变更、观测场周边环境改变等原因不可避免地造成了长期观测资料中存在着非均一性问题。因此,如何能够建立完整连续的长时间气候序列一直是气候变化研究工作中首先需要解决的问题。
华北平原地处气候脆弱带,气候变化敏感,该地区的气候资源对我国农业生产影响重大 [1] [2] 。但是,目前华北平原气候变化定量分析缺乏百年序列气候资料,其结果很可能会造成研究结论的片面性和极端性。保定气象站是华北平原地区保留着百年历史气候资料的典型台站之一,其气候资料对华北区域气候变化规律的研究起到重要的支撑作用,降水量变化无疑是其中最重要的因子之一 [3] - [8] 。但由于该站解放前资料存在不连续、缺乏均一性,使得该站的长时间序列资料没有得到很好的应用。本文拟通过对保定气象站现有1913~2014年资料中缺测数据的插补及插补后数据的均一性分析,来建立保定站百年逐月降水量序列,并通过与探测环境一致的周边站降水量序列的综合对比,对其合理性进行评估,从而,为华北平原地区气候分析和研究提供可靠的百年基础数据。
2. 资料和方法
2.1. 资料来源
1951年以前的数据,保定站主要来自中国科学院地球物理研究所1954年编印的《中国降水资料》以及国家水利部水文局1954年刊印的《华北区水文资料海河流域大清河水系降水量(1913~1949)》(简称《华北降水量》);邻近站主要来自国家气象信息中心2002年建立的《中国长年代降水数据集》及2009年建立的《全国60个重点城市长时间序列降水数据集》。1951年以后的数据,均来自中国气象局2014年建立的经过严格质量控制的《中国地面气象要素月值数据集》。研究中选取1913~2014年逐月降水量资料进行分析。
2.2. 资料插补
保定站的降水量资料来源有三类:《中国降水资料》、《华北降水量》及《中国长年代降水数据集》,经分析《中国长年代降水数据集》数据来源相对稳定,质量较好,这里将其月值资料作为保定站1951年以前的基础数据建立新的降水序列,其他两类数据源作为该基础数据缺测年份的补充。
如表1所示,基于上述初步整合后的保定站数据缺测量较大,降水量连续缺测的年份主要集中在1949~1954年,缺测率达11.2%。因此,为了恢复时间序列的完整性,研究中拟采用两种插补方法,同时对保定站1913~2014年连续缺测年份的逐月降水资料进行插补,通过比较分析两种插补结果,选取相对合理的插补序列,来建立该站完整的百年降水原始序列。两种方法分别为:一是标准化序列法 [9] ,二是多元线性回归法 [10] ,二者均是利用周边邻近站观测值对待插补站进行插补的方法,并且两种方法已在全国和区域长年代缺测数据的插补试验中得到了较好的应用 [3] [11] [12] [13] 。计算过程中,均假设保定站某年第 月月值降水量数据缺测,利用邻近站月值资料对其进行估计。
月月值降水量数据缺测,利用邻近站月值资料对其进行估计。
2.2.1
. 标准化序列法
标准化序列法 [9] 是假设对于在同一气候区域内的所有站点,某一时间点的气象要素值与该时间点多年平均值的距平都是相似的。该方法可以表示为:
 (1)
(1)
 (2)
(2)
 (3)
(3)
其中, 表示标准化序列,
表示标准化序列, 表示邻近站平均的标准化序列,
表示邻近站平均的标准化序列, 代表第
代表第 个邻近站,
个邻近站, 为第
为第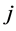 个邻近站第
个邻近站第 月月值降水量,
月月值降水量, 和
和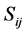 分别为第
分别为第 个邻近站第
个邻近站第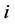 月月值降水量多年平均值和标准差,
月月值降水量多年平均值和标准差,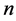 表示邻近站站数。
表示邻近站站数。 为保定站第
为保定站第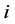 月待插补月值降水量,
月待插补月值降水量, 和
和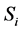 分别为保定站第
分别为保定站第 月月值降水量多年平均值和标准差。这里选取1961~1990年为多年气候标准值。
月月值降水量多年平均值和标准差。这里选取1961~1990年为多年气候标准值。
2.2.2. 多元线性回归法
多元线性回归法 [10] 是通过建立邻近站( )与待插补站时间序列定量的线性统计关系,来对待插补站序列
)与待插补站时间序列定量的线性统计关系,来对待插补站序列 进行插补,表达的关系式如下:
进行插补,表达的关系式如下:

Table 1. Records of missing percentages of precipitation data at Baoding station and its neighbors from their starting dates to 2014
表1. 保定站与邻近站建站至2014年降水量资料完整性信息。
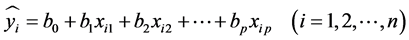 (4)
(4)
其中, 回归系数根据公式(5)求解:
回归系数根据公式(5)求解:
 (5)
(5)
与标准化序列法一样,保定站与邻近站定量统计关系的建立同样利用1961~1990年多年历史降水序列进行估计。公式(4)、(5)中 为邻近站站数,
为邻近站站数, 为时间序列长度30年,
为时间序列长度30年,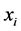 为邻近站某月月值降水量,
为邻近站某月月值降水量, 为保定站某月月值降水量。
为保定站某月月值降水量。
对于建立的保定站与邻近站的定量统计式(公式(4))是否确有线性关系,需要通过回归方程的显著性检验进行验证,检验统计量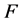 如式(6)所示:
如式(6)所示:
 (6)
(6)
在显著性水平 下,若
下,若 ,则认为回归方程显著,线性关系成立。其中,
,则认为回归方程显著,线性关系成立。其中,
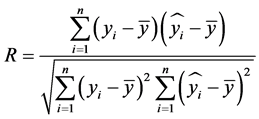 ,
, 、
、 和
和 分别为保定站某月月值降水量的插补值、实际观测值和实际
分别为保定站某月月值降水量的插补值、实际观测值和实际
观测值的30年平均值。
2.2.3
. 邻近站的选取
邻近站主要以保定站为中心选取水平距离300 km以内的时间序列起始年份至少在1913年以前,完整性较好,探测环境相对一致的,并且海拔高度应满足以下条件 [12] [13] :
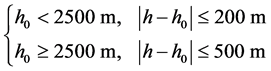 (7)
(7)
式(7)中 分别为邻近站和保定站的海拔高度。根据以上条件,最终确定了天津站和北京站作为邻近站,台站信息如表1所示。
分别为邻近站和保定站的海拔高度。根据以上条件,最终确定了天津站和北京站作为邻近站,台站信息如表1所示。
在数据插补前,对选定两个邻近站的逐月降水量资料进行了初步的质量控制,即分别检验月降水量
是否有超出范围 的极值,其中,
的极值,其中, 为某月降水量的多年平均值(这里取对应要素的全序列长度),
为某月降水量的多年平均值(这里取对应要素的全序列长度),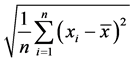 为某月降水量的标准差,研究中取
为某月降水量的标准差,研究中取 。经人工核实如出现上述不合理
。经人工核实如出现上述不合理
的数值,均做缺省处理。
2.3. 插补数据的误差检验
与研究 [11] [12] 类似,这里同样采用交叉检验法 [14] 对上述两种插补模型得到的保定站缺测记录的插补结果进行比较分析,通过对比插补值与实际观测值的误差大小来评估插补效果,其中误差的评判标准分别为:标准均方误( ) [4] ,标准误(
) [4] ,标准误( ) [15] ,插补值与实际观测值差值在±25 mm范围内的样本比例(
) [15] ,插补值与实际观测值差值在±25 mm范围内的样本比例(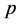 ),如公式(8)~(10)所示:
),如公式(8)~(10)所示:
 (8)
(8)
式中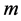 为样本容量,
为样本容量, 为插补值,
为插补值, 为实际观测值,
为实际观测值, 为1961~1990年30年样本标准差。
为1961~1990年30年样本标准差。
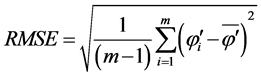 (9)
(9)
式中 ,
, ,其中
,其中 。
。
 (10)
(10)
2.4. 均一性检验
由于一些特殊的历史原因使得我国1951年以前的台站观测资料来源复杂,时间序列的一致性和完整性较差,这在一定程度上增加了建立能够代表待检序列所在环境真实气候变化的参考序列的难度。如果利用本身就存在非均一性问题的序列作为参考序列,则会大大降低均一性检验的正确性。查阅台站历史沿革信息发现,我国详尽系统的元数据资料基本始于20世纪50年代初期,这对于1951年以前非均一性检验结果合理性的判断和断点订正位置的确定均缺乏可靠的参考依据。
RHtestsV4软件包提供的惩罚最大F检验(PMF) [16] 适用于无参考序列的检验过程,能够有效避免非均一的参考序列及缺乏详尽元数据信息带来的检验误差,并且该方法在前人的工作中已经得到了较好的研究成果 [15] [17] [18] [19] 。另外,对于降水量这类时空分布不均匀、局地性较强的气象要素,在没有平行观测的条件下,很难找到合适的参考序列。因此,研究中基于插补效果较好的逐月降水量序列,采用惩罚最大F检验(PMF)对保定站1913~2014年降水月值序列进行均一性检验。需要说明的是,RHtestsV4软件包中的函数只针对具有高斯分布的气象要素,如气温等,而降水量数据具有非正态分布特点,所以在进行均一性分析之前将降水量资料进行对数转换,以达到一定程度上的正态化,即 ,其中
,其中 为原始数据,
为原始数据, 为转换后的数据。检验步骤如下:
为转换后的数据。检验步骤如下:
1) 调用函数FindU检验对数转换后的逐月降水序列(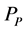 )中所有显著的间断点,这种间断点可以没有元数据支持,称之为“Type-1”断点。如果这一步没有显著间断点被检测出,那么可以认为该序列是相对均一的,不用进行以下检验。
)中所有显著的间断点,这种间断点可以没有元数据支持,称之为“Type-1”断点。如果这一步没有显著间断点被检测出,那么可以认为该序列是相对均一的,不用进行以下检验。
2) 调用函数FindUD检验 序列中所有显著的间断点,这种间断点需要有可靠的元数据支持,称之为“Type-0”断点。
序列中所有显著的间断点,这种间断点需要有可靠的元数据支持,称之为“Type-0”断点。
3) 查阅元数据,保留有确凿迁站、仪器变更等记录支持的“Type-0”断点以及统计显著的“Type-1”断点。
4) 调用函数StepSize评估在第3)步中被保留的“Type-1”和“Type-0”断点的显著性和突变幅度,筛选出显著的间断点。
5) 分析第4)步筛选出的间断点,去除突变幅度最小且不显著的间断点,然后,重新运行函数StepSize,直至每一个断点都被认为是统计显著的。
3. 插补结果分析
3.1. 误差检验
根据公式(8)~(10)计算了保定站1913~2014年逐月降水量序列插补值与实际观测值的误差,如图1所示。
从图1降水量的插补精度来看,利用多元线性回归模型插补得到的逐月降水量的标准均方误( ) (图1(a))和标准误(
) (图1(a))和标准误( ) (图1(b))基本小于标准化序列法得到的结果,并且插补误差±25 mm的比例(
) (图1(b))基本小于标准化序列法得到的结果,并且插补误差±25 mm的比例(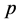 ) (图1(c))也基本大于标准化序列法。多元线性回归法的
) (图1(c))也基本大于标准化序列法。多元线性回归法的 、
、 、
、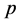 平均插补精度分别为7.2 mm、25.7 mm、81%。
平均插补精度分别为7.2 mm、25.7 mm、81%。
3.2. 相关性检验
表2分别给出利用两种插补模型得到的降水量逐月估计值与实际观测值的相关系数。表2显示,多元线性回归模型得到的降水量插补结果与实际观测值间的相关程度较高,并且均通过 显著性检验,相关系数范围为0.538~0.855。
显著性检验,相关系数范围为0.538~0.855。
因此,综合上述分析结果,研究中将采用多元线性回归法插补得到的逐月降水量序列作为建立保定站1913~2014年百年降水月值序列的原始数据。
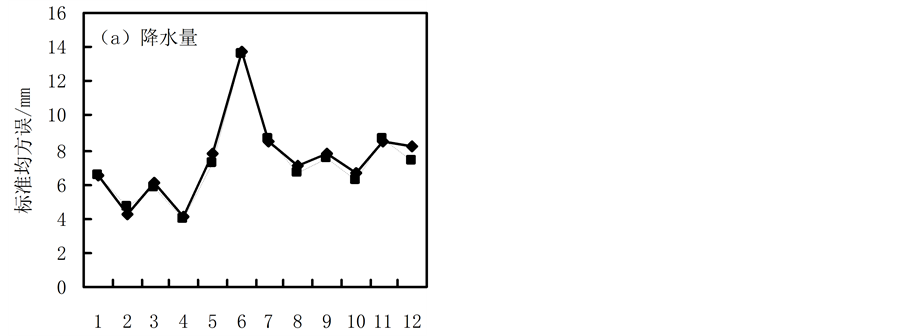

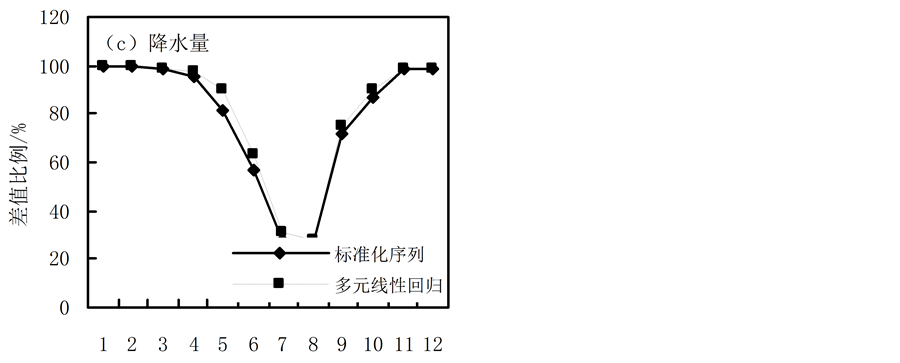
Figure 1. The interpolation effect indices of the mean square error (a) standard error (b) and error percentages of interpolated and observed values (c) for the monthly precipitation data
图1. 逐月降水量插补结果的标准均方误(a)、标准误(b)、差值比例(c)
4. 百年降水量月值序列的气候检验
研究中通过PMF法重点针对迁站、仪器变更等能够对降水序列造成非均一性影响的因子进行了检验 [20] [21] ,同时结合台站历史沿革信息并没有发现保定站月降水量序列存在显著的不连续现象。因此,研究认为插补后的1913~2014年月降水量序列是相对均一的。
气候检验分析中采用的对比序列来自国家气象信息中心2014年建立的《全球陆地月降水订正数据集(v1.1)》,该数据集是在13类国际国内已有的降水数据产品基础上,通过数据筛选、整理、融合、质量控制及均一性分析后形成的一套全球历史降水数据集。对于中国地区来说,由于存有时间序列较长且相对完整的降水数据的台站有限,所以研究中依旧选取了北京(54511)、天津(54527)两个气象站的降水资料作为对比序列。另外,降水要素是时空变率极大的非连续变量,局地性较强,所以,在这里我们仅通过趋势变化的对比分析,来评估本文建立的保定站百年降水月值序列的合理性。
从表3中给出的百年趋势值来看,保定站逐月降水量的趋势变化幅度和特点与北京站(54511)、天津站(54527)的基本一致,幅度变化较大的基本出现在暖季月份(6~10月),其中7、8月的百年降水量均呈明显的减少趋势。对于年序列变化来说,54602站与54527站的更为一致,百年趋势变化均不明显。而54511站由于7月降水减少幅度较为明显,一定程度上造成了该站年降水量趋势减少幅度相对较大。从趋势变化的显著性来看,表3显示,除了54511站12月降水量趋势通过显著性检验外,其他站年、月百年降水
Table 2. Correlation coefficients of monthly precipitation values between interpolated and observed by two approaches
表2. 两种方法得到的逐月降水量插补值与实际观测值的相关系数
注:表中数据均通过 显著性检验。
显著性检验。
Table 3. Trends of monthly hundred-term precipitation data between Baoding with Beijing and Tianjin (mm/ 100a )
表3. 保定站与北京及天津站百年月降水量的趋势变化(mm/100a)
注:表中加粗字体均表示通过 显著性检验。
显著性检验。
趋势均没有达到统计显著性水平。这也是与我国近百年来降水量的趋势变化特点一致 [6] 。因此,总的来看,本文建立的保定站百年降水月值序列是相对合理的。
5. 结论
基于多源的逐月降水量资料,通过数据整合、缺测值插补及均一性分析,建立了保定站1913~2014年百年降水月值序列,并通过与探测环境相对一致的气候序列对比,对该百年序列进行了评估,得到如下结论:
1) 研究中同时采用标准化序列法和多元线性回归法对经过整合并进行初步质量控制后的保定站降水量序列进行了插补。通过交叉检验法,利用插补值与实际观测值的标准均方误、标准误、差值比例3类指标及相关性对比分析得到,多元线性回归法插补的逐月降水量序列效果较好。
2) 利用PMF法对插补后的保定站1913~2014年降水量月值序列进行了均一性检验,得到插补后的百年月降水量序列是相对均一的。
3) 研究中通过与均一化的北京和天津两个邻近站百年气候序列趋势变化的对比分析显示,本文建立的保定站百年降水序列的趋势变化幅度和特点与之基本一致。一定程度上说明了该百年降水月值序列具有可用性,能够为我国华北平原地区气候分析和研究提供可靠的百年序列的基础数据。
资助项目
公益性行业(气象)科研专项(重大专项) (GYHY201506001-1)。
NOTES
*通讯作者。