1. 引言
“交叉销售”一词最早在1965年被国外银行业普遍使用 [1] ,35年以后,交叉销售的理论和实践也得到了大规模的研究。Nash (1993) [2] 和Deighton等学者(1994) [3] 指出,交叉销售是指“鼓励一个已经购买了某公司A产品的顾客购买其B产品”。郭国庆(2003) [4] 认为交叉销售的实质是:充分利用一切资源,服务市场、开展营销、赢得用户。其后,赵华、宋顺林(2007) [5] 基于ERMSW算法,对已有的客户购买序列进行有维度约束,探究客户的消费趋势,预测匹配度满足一定条件的客户可能的购买行为。Li Chunqing等(2010) [6] 针对我国银行的实际情况,对NPTB模型的变量进行修正,并通过实证分析,论证了神经网络模型在交叉销售预测中的优越性。
目前国内外对交叉销售实证方面的研究,主要以识别交叉销售机会的方法为主,已有的方法有:潜在特质模型、获得模式、市场细分法和NPTB模型等,但是这些方法仅仅从各自的模型和理论出发,识别交叉销售机会,因此众说纷纭。特别是对于大数据,缺少相应的交叉销售实例研究。
本文以美国某知名保险公司(下记A公司)一个保险项目为例,交叉销售数据来自2012年12月到2013年10月共约1.2亿记录、230个变量。将其分为加利福尼亚州(下记CA)和非加利福尼亚州(下记NCA)两个区域销售数据,分别建立交叉销售模型,从而在已成功购买车险的人群中预测客户购买两种不同家庭险的概率,一种是面向房屋拥有者的保险,一种是面向租客的保险,并对比两种方法优劣 [7] 。
该数据集为月数据,每个都有230个变量,约1200万条记录,其中性别、年龄、收入、住房所有权、居住类型、婚姻状况、教育水平、种族、子女等变量属于人口统计学数据;购买类型、客户服务获得、付款日期与数量、保险索赔或破产行为等变量属于行为数据;对风险的态度等属于心理数据 [8] ,详细数据说明参见王雪莲(2015) [7] 。该数据集中的行为数据一般比其他类型数据在预测未来行为时效果好,但获取价格比较昂贵;人口统计学数据容易获取且比较稳定,可用于特征分析或预测;心理数据能提高模型的预测能力,但不易获取 [8] 。由于美国保险行业中CA区域保单政策明显不同于其它州,故本文模型中也将数据分为CA和NCA两个大区域分别建模。
本例中交叉销售成功是指已经购买车险的客户满60天后再次购买家庭险,其它情况则不属于交叉销售成功。以60天作为临界值来界定该保单是否属于交叉销售成功,主要有以下原因:(1) 经验值60选出的客户群购买行为最稳定;(2) 一份保单满60天后换到别家保险公司,能获得更多优惠政策。
建立交叉销售模型的预期目的为:(1) 建模过程首先对数据进行变量筛选,尽可能了解数据的来源与质量,有利于指导A公司获取数据的方向;(2) 有效探究易购买目标产品的潜在客户特征,便于对潜在客户进行相应的商业营销,进而提高销售利润、客户满意度和忠诚度等。
2. Logistic模型介绍
在社会科学诸如人口学、心理学、社会学、经济学以及公共卫生学当中,大量的观测因变量是属性变量。Logistic模型是研究二分类变量与其他影响因素之间关系的一种统计分析方法。
假设某一事件发生的概率为
,其中
,自变量与
之间的关系可用下式表示:
将自变量与概率P之间的关系通过对数变换转为线性函数进行估计,因此可以使用线性回归的方法进行估计。当自变量个数为
时,上式可扩展为
(一) 多重Logistic模型
当因变量有
个类别(
),此时多重Logistic模型第
组样本因变量
取第
个类别的概率为:
易知,上式中各回归系数同时加减一个常数后,
数值保持不变。不失一般性,我们把分母的第一项
中的系数取为0,称为参照系数,得到新的回归函数的表达式:
若有
个因变量,取其中一类作基本类(组),其它
类与该类分别建
个Logistic模型,通过变量系数及其符号等指标来评判模型结果的优劣。
(二) 两阶段Logistic模型
首先将因变量的类别区分成两个大类进行Logistic建模,然后把模型结果中目标类数据细分成2个小类别再进行一次Logistic建模,最终得到两阶段Logistic模型。在本文中两阶段Logistic模型的第一阶段,以交叉销售家庭险的人群为目标变量,销售成功记为1,其它为0,即可建立第一个Logistic模型;第二阶段,定义购买房屋拥有者险的人群为记为1,购买租客险的人群记为0,由此得到第二个Logistic模型。
3. 模型的建立与结果分析
(一) 建模要求
建模的过程也是变量筛选的过程。根据一般要求,入选的变量模型响应率应大于5%。其次,根据变量实际意义及保险行业模型要求不断调试模型:对意思相近变量,模型里只保留一个;与因变量相关性特别强也需要删掉;贡献率越大表示该变量越能将购买人群区分出来,贡献率太大也不好,通常最终会选入7~20个变量进行建模。对于变量选择更详细的要求参见文献王雪莲(2015) [7] 。
(二) 评价模型的指标
对于模型的评价指标主要有基尼系数、C值和整个模型分组得分,主要目的是筛选出更有可能购买交叉保险的客户群。
(1) 基尼系数
经济学上,基尼系数越大,表示潜在客户特征差距越大,重点对收入更高或经济实力更强的客户发营销广告,响应的人也会越多,这样更容易地找出更有可能购买保单的客户。因此,模型的基尼系数越大越好。
根据对整个模型打分结果画出相应的洛伦茨曲线。其中,洛伦兹曲线是在一个总体(国家、地区)内,以“最贫穷的人口计算起一直到最富有人口”的人口百分比对应各个人口百分比的收入百分比的点组成的曲线。这里穷富靠分数高低来评判,如图1所示。
其中
表平均直线OT与洛伦茨曲线围成的面积,
为绝对平均直线以下直角三角形OPT的面积,基尼系数的计算公式如下:
。
的值在0与1之间,即
。计算基尼系数的方法有很多,如直接计算法、切块法、函数法、弓形面积法等。本文使用切块法。根据理论知识,先画出该方法基尼系数计算示意图,如图2所
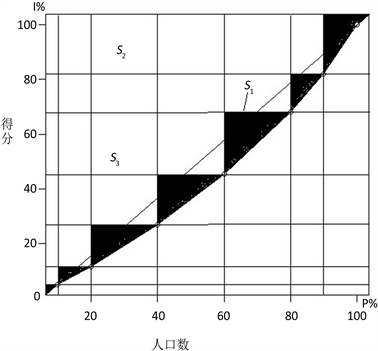
Figure 2. Gini coefficient obtained by jackknife method
图2. 刀切法算基尼系数
示:设
为该记录对应的预测概率,
为每条记录所占比例,即
,则基尼系数公式中
的面积可表述为下列三部分的代数和,其中
近似于图中所涂阴影部分面积和:
为洛伦茨曲线以上的面积中除去
的阴影面积的部分:
为单位正方形面积的一半,
。由于
,
,Qi为前i条记录的累积比例,故基尼系数基本公式为:
刀切法算基尼系数的优缺点分别为:
优点:洛伦茨曲线的曲线越平缓,即曲率越小,越接近对角线,估计的精度越高。
缺点:在计算过程中省略了弓形面积,所以其结果较真实基尼系数值偏小。
(2) C值:一个衡量Logistic模型预测准确程度的统计值。
比如有一个数据,共10,000条记录。其中1000条表响应的人(目标变量 = 1),另外9000条是不响应的人(目标变量 = 0)。通过预测这10,000个人每个人响应的概率,得到所有预测正确的记录所占的百分比。
(3) 整个模型分组得分
调试模型完成后,将每组数据值代入模型,可估计出
值,称为得分数值。将这些得分按降序进行排序,将其均分为若干组,得到所在组的秩。
为了避免模型过拟合现象,我们采用交叉验证方法进行建模。首先用训练集建立模型,得到参数估计和模型表达式,例如
,这里的
为属性变量,表示买或者不买该产品,
是自变量。用此模型得到测试集的
值,从高到低排列分成10组,得到每一个
的秩。理想的模型是这些秩依次递减、不跳跃,而且第一组指标值越大越好。最后,根据经验取一个得分分割点作为临界值,对分值大于临界值对应的潜在客户进行营销,其他不营销。
综合评价变量和模型的统计量及其作用,总结如表1所示。
(三) 多重Logistic模型
多重Logistic模型的因变量有3个类别,定义购买家庭险下的面向房屋拥有者的人群为目标变量1,定义购买家庭险下的面向租客保险的人群为2,其它人群为3。回归函数以因变量3作为基准,回归系数取做0。对其它两类别,每个类别都和其它人群一起建立一个Logistic函数,因此每个自变量都有两个回归系数,自由度为2。CA上的模型结果见表2。
其中,响应模式1是房屋拥有者和其它人群对比建立的模型,模式2是租客与其它人群建立的模型。只有两对变量符号不同,其它变量符号都一样,而且这两对符号不同的变量在模型中的贡献率之和低于10%。从表中结果来看,多重Logistic模型存在一些局限性。以“花在车险上的钱”这个变量为例说明,在模式1中,它为正号,表明资金较多的客户更容易购买面向房屋拥有者的保险,而在模式2中,它也是正号,表示资金越多客户越容易购买面向租客的保险,这样的结果说明同一个潜在客户资金越多,两种家庭险都容易购买,这与实际情况不吻合。由此说明从变量角度,很难区分这两部分人群。经过实证分析,发现不管是CA还是NCA,多重Logistic模型都存在以下问题:
1、选出的变量一样,且系数相差不大。
2、相应的变量符号一样,即使有符号不同的,但它们在整个模型里贡献率之和还未达到10%。

Table 1. Evaluation and effect of statistic for Variables and models
表1. 评价变量和模型的统计量及其作用
Table 2. Results of multiple Logistic model for California
表2. 加利福尼亚州多重Logistic模型结果
综合以上原因,可认为多重Logistic模型并不能有效地区分出两种家庭险的客户,即不能有效地达到预期效果,于是我们尝试使用两阶段Logistic模型。
(四) 两阶段Logistic模型
两阶段Logistic模型中,对于其目标变量的定义如下:第一阶段将成功交叉销售家庭险的人群定义为1,其它为0。第二阶段将购买家庭险下的面向房屋拥有者保险的人群定义为目标变量1,购买家庭险下的面向租客保险的人群定义为0。
美国住房情况具有以下特点,大多数美国人对拥有自己房屋的美梦并不难实现,例如不需全部现款购屋的交易方式,已大大提高一般人民的购买能力,再加上一些减税的政策,使一般房屋拥有者的负担得到减轻,所以说在美国买房比住房划算 [9] 。但是在美国住房由工作单位或政府分配的情况很少,所以住出租房也是相当普遍的现象。另一方面,经济条件好的家庭一般会优选买房自住,经济条件不好的家庭会优选租房住,且在城市里中租房的人较多,而农村住房拥有者更多。对于美国车险费率制度,其基本信息见表3。
了解这些基本情况后,本文分别在CA和NCA建立两阶段Logistic模型,各变量、系数及其模型贡献率结果见表4和表6。
表3. 美国车险费率制度基本信息
Table 4. Results of two-stage Logistic model for California
表4. 加利福尼亚州两阶段Logistic模型结果
从表4结果知,以上变量及其在模型里的符号,与实际情况相符,且第一个变量的贡献率约50%,对变量一一作如下分析:(1) 倾向于按月付保额的人,说明其不稳定性较大,相对来说是房屋拥有者的可能性较小,可认为是租客;(2) 一个家庭里年龄较大的驾驶员,越老越有可能是房屋拥有者,因老年人更倾向于住在自己的房子里;(3) 家庭拥有的汽车数目越多,说明这个家庭有较好的经济状况,则越不可能是租客;(4) 居住地区的平均家庭收入越高,一般为城市,因而租客居多,较不可能购买保单;(5) 过去一年索赔额越多,越有可能是租客。(6) 每次双保险事故限额越高,说明该客户经济收入越稳定,越有可能是房屋拥有者;(7) 最新的车越老,则越不可能是房屋拥有者;(8) 拥有保时捷、宝马Mini汽车、斯巴鲁、沃尔沃、奥迪、雷克萨斯、奔驰、宝马和捷豹等高端车的人越有可能是房屋拥有者;(9) 家庭居住在客户保险公司的客户占有率越大的地区,越有可能是房屋拥有者。
以上显示为模型变量的信息,表5给出了模型各项评价指标值。
其中C值处在保险行业规定的0.6~0.8之间,基尼系数也相对较高。此时总模型表示为:
上式中
表示更倾向于按月付款,
表示最大驾驶员年龄,
表示汽车数目,
表示居住在高收入
家庭区,
表示过去一年索赔额,
表示双保险每次事故限额,
表示最新车的车龄,
表示拥有保时捷、奔驰、宝马等高端车,
表示客户占有率。
通过与A公司负责人深入探讨,公司反馈回来的信息显示这部分人确实更容易发生购买行为。
非加利福尼亚州的各变量,系数及其模型贡献率如表6所示。同样,模型里的变量及其符号都符合实际,且第一个变量的贡献率明显未超过60%,对变量一一作如下分析:(1) 家庭里驾驶员数目越多,越有可能是房屋拥有者;(2) 信用评价越差,越不可能是房屋拥有者;(3) 倾向于按月付保险款的人,说明他不稳定性较大,越不可能是房屋拥有者,这与CA情况相同;(4) 一个家庭里最年轻驾驶员的年龄越大,说明财产收入等越稳定,越可能是房屋拥有者;(5) 最新的车越老,说明该家庭越没有钱,则越不可能是房屋拥有者,这也与CA情况相同;(6) 每次双保险事故限额越多,说明该客户的经济收入越稳定,越有可能是房屋拥有者,这也与CA情况相同;(7) 人口密度越大的地区,越有可能是城市,那么生活在该地区的人越有可能是租客;(8) 保险公司为了吸引更多的稳定客户,会对经济能力强的客户在他进行保单转移时有折扣,那么这些人也更有可能是房屋拥有者;(9) 对与保险公司关系密切的团体进行保单打折,这些人也更有可能是房屋拥有者。
以上显示为模型变量的信息,模型的各项评价指标值见表7。
Table 5. Model evaluation index for California
表5. 加利福尼亚州模型评价指标
Table 6. Results of two-stage Logistic model for non-California
表6. 非加利福尼亚州两阶段Logistic模型结果
表7. 非加利福尼亚州模型评价指标
其中C值处在保险行业规定的0.6~0.8之间,基尼系数也相对较高。总模型为:
上式中
表示驾驶员数,
表示信用评分,
表示更倾向于按月付款,
表示最年轻驾驶员的年龄,
表示最新车的车龄,
表示双保险每次事故限额,
表示人口密度,
表示保单转移有折扣,
表示对与保险公司关系密切的团体进行打折。
同理,实际结果也显示这部分人更容易发生购买行为。
4. 方法分析比较
从上面的结果可知,多重Logistic模型结果无法合理地解释选出的变量及其符号意义,而两阶段Logistic模型能够与实际情况相符。多重Logistic模型在加利福尼亚州的得分情况见表8,两阶段Logistic模型在加利福尼亚州的得分情况见表9,两种模型的累计交叉销售成功数对比见图3。多重Logistic模型在非加利福尼亚州的得分情况见表10,两阶段Logistic模型在非加利福尼亚州的得分情况见表11,两种模型累计交叉销售成功数对比见图4。
(1) 加利福尼亚州。见表8,表9,图3。
(2) 非加利福尼亚州。见表10,表11,图4。
对比上面两种建模方法,在房屋拥有者保险方面,可发现两阶段Logistic模型在各个组别上的累积得分都高于多重Logistic模型的累积得分,其中第一组别累积得分为323,高于多重Logistic模型第一组别的累积得分312,又因为两阶段Logistic模型的各个变量及其符号都与实际情况相符合,所以两阶段Logistic模型在CA的预测效果更好。
5. 结论与展望
对比上面两种建模方法,对房屋拥有者保险而言,在各个组别上的累积成功交叉销售指标值,其中
Table 8. Scores of multiple Logistic model for California
表8. 多重Logistic模型在加利福尼亚州的得分表
Table 9. Scores of two-stage Logistic model for California
表9. 两阶段Logistic模型在加利福尼亚州的得分表
Table 10. Scores of multiple Logistic model for non-California
表10. 多重Logistic模型在非加利福尼亚州的得分表
Table 11. Scores of two-stage Logistic model for non-California
表11. 两阶段Logistic模型在非加利福尼亚州的得分表
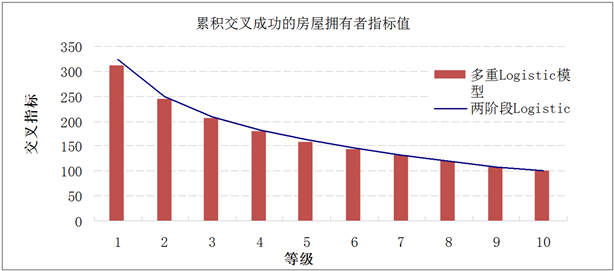
Figure 3. Cumulative score comparison of two models for California
图3. 加利福尼亚州两种模型累积得分对比图
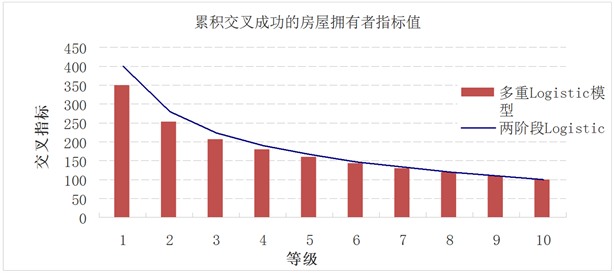
Figure 4. Cumulative score comparison of two models for non-California
图4. 非加利福尼亚州两种模型累积得分对比图
第一组别累积得分为399,明显高于第一组别的多重Logistic模型累积得分351,可发现两阶段Logistic模型在各个组别上的累积得分也都高于多重Logistic模型的累积得分,又因为两阶段Logistic模型的各个变量及其符号也都与实际情况相符合,所以两阶段Logistic模型在NCA的预测效果也是更好。再次印证了两阶段模型表现更优的结论。
综上所述,在加利福尼亚州和非加利福尼亚州,不管是从对模型变量及其符号的解释上,还是从模型得分的对比上,两阶段Logistic模型预测效果均优于多重Logistic模型。通过本文的努力,模型选出的变量更有利于指导A公司获取数据的方向,有助于探究易购买目标保险的潜在客户特征,能够达到交叉销售模型的预期目标。
致谢
本工作受到国家自然科学基金和教育部人文社科基金青年项目资助。感谢匿名审稿人提出的宝贵意见,对论文的修缮工作起到重要作用。感谢美库尔商务咨询(南京)有限公司、南京审计大学统计科学与大数据研究院提供数据及编程环境、多次参与论文的讨论并给出专业意见。
基金项目
本文获得国家自然科学基金11401094、11571073,教育部人文社科基金13YJC910006及江苏省高校优势学科PAPD项目资助。