1. 介绍
显著性目标检测是计算机视觉的一个基本分支,其目的是为了检测到图像中最突出的目标。显著性目标检测应用在很多领域,例如目标检测和识别 [1] 、图像和视频压缩 [2] 、基于内容的图片检索和图片浏览 [3] 、图片编辑和操作 [4] 等。
显著性目标检测早在90年代就有人对其进行研究了,最早的模型是被Itti等提出的 [5] ,推动了计算机视觉的发展。该模型是受早期灵长类动物的行为和神经元结构的启发后提出来的,求取图像的颜色、亮度和方向特征在不同尺度下的差值进行归一操作,合成显著性图。但是由于在构成高斯金字塔时的下采样操作和高斯模糊会滤除部分高频信息,造成最后得到的显著性图很模糊。为解决这个问题,基于Itti模型和图模型,Harel等人 [6] 用马尔科夫链生成显著性图。Achanta等人 [7] 提出了调频的方法,使用颜色特征和亮度特征来决定图像某个区域与其周围的对比度,产生和原图像大小一样的显著性图。Cheng等人 [1] 提出了基于全局对比度的显著性区域检测,将图像用图像分割方法分割成多个区域,每个区域的显著性值被定义为该区域与图像其他所有区域的距离的加权叠加,而区域与区域的距离定义为区域中的量化后的所有颜色距离的加权叠加。该方法性能和识别效果在简单场景中较好,不过在大场景和复杂场景中效果差强人意。上述的方法都是传统的,适用性和精度都有待提高。随着卷积神经网络(CNNs) [8] 的兴起,基于深度学习的显著性目标检测的模型被很多研究者研究。目前在很多研究中,CNNs被证明在应用于显著性目标检测中是有效率的。由于它们的多水平和多尺度特征,CNNs能在没有先验知识的情况下精确捕获到最显著的区域。He等人 [9] 使用了一维卷积模型来学习超像素水平下的特征表示,对比基于像素水平的CNN模型,他们的模型减少了计算开销。但是只使用颜色平均值来表达超像素特征是不够的,图像空间结构很难使用一维卷积和池化操作就能表示完全,这导致了模糊预测。Wang等人为更好检测出显著性区域,将局部和全局信息考虑进去 [10] 。模型被分别设计成局部评估和全局搜索两个网络,一个深度神经网络(DLL-L)先用来学习局部块的特征,捕获高层次客观对象来决定每个像素的显著性值。对于全局搜索,他们训练另一个深度神经网络(DNN-G),使用大量的全局对比特征,例如几何信息、全局对比特征等来预测每个显著性区域的显著性值。选取前K个候选区域使用权重和来计算最终的显著性图。
目前大部分基于深度学习模型的目标检测算法是针对图像空间单位来做的,通过模型确定每一个空间单位是否属于显著性目标区域来确定整个显著性目标。因此它们只注重了空间单位之间的对比,而忽略了图像的整体性空间关系(全局上下文信息)。这样做的坏处有两个:1) 因为其注重的是空间单位的对比,所以假设有两个比较突出的物体,就很容易把两个都标出来,而实际上Ground truth只有一个;2) 无法给出显著性目标的精确轮廓,特别是复杂场景下。
Liu等人 [11] 提出用两个子网络来产生预测map图,用VGG16 [12] 提取粗糙的全局的预测,另一个网络由一系列循环卷积层结合前一个网络中相应的特征进行精度提炼。该方法得到的显著性检测效果良好,虽然使用了多层循环卷积网络,但是多次下采样还是会导致结果边缘模糊,并性能上有待提高。本文提出的新模型,输入的是原图像,这样有利于抓住原图像的整体空间信息(整体上下文),端对端输出显著性区域图像。首先通过VGG16 [12] 和Region-CNN两个子网络得到一个粗略的结果,用于大概定位显著性目标的形状和位置,然后通过一系列RCL (Recurrent CNN Layer) [13] 来将粗略的显著性区域图像的轮廓精度提升,最后得到比较精确的结果。
2. 模型介绍
如图1所示:整个模型分为两个过程,分别为粗提取到细精炼两个过程。
粗提取过程用于得到一个粗略的显著性区域图像,分别用了两个现有模型,VGG16和Region-CNN。VGG模型是发表在ICLR 2015上的一个图像检测模型,获得了2015年imagenet的冠军,有多种变体,本文采用的是VGG16,VGG16可以通过深层CNN提取到图像的高层次特征(high level feature),是现在公认的效果较好的一个图像特征提取模型。VGG16的具体结构这里不再赘述,通过VGG16获得一个大小14 × 14,512通道的feature map,经过一层全连接得到一个392维的向量。Region-CNN主要分为两个步骤,第一个是Region proposal,对一个图像进行区域划分,本文划分的算法采用的是Mean Shift [14] ,有利于图像局部特征的提取和图像结构信息的表达,然后通过CNN对分割后的图像进行特征提取,最后经过一层全连接同样得到一个392维的向量,与VGG16得到的392维向量进行拼接,得到784维向量,最后将这个向量reshape成一张粗略的显著性目标区域图像。
后半部分通过一个基于RCL (Recurrent CNN Layer)的模型,对粗略的显著性目标区域图像进行逐步
轮廓精度提升。接下来将详细介绍这个模型以及上述提到的Region-CNN模型。
2.1. Region-CNN子网络
Region-CNN分为两个阶段。第一个是区域分割阶段,这里采用的是Mean Shift算法,该算法抗噪性和边缘贴合度好,生成的超像素极不规则。第二个阶段时CNN阶段划,对分割后的图像进行操作,具体细节如下图2所示:经过八层的神经网络,第一层和第二层分别是一次卷积和一次最大值池化,第三层和第四层都是卷积操作,第五层是一次卷积和一次最大值池化,第六层和第七层是一次全连接得到一个392维的向量,即为之前图1中所示的用于拼接的392维向量。
2.2. RCL (Recurrent CNN Layer)与轮廓精度提升
介绍轮廓精度提升的模型之前,先介绍一下RCL (Recurrent CNN Layer),如图3所示:右边黑色虚线框是左边RCL的展开,在每一层RCL中都有若干个小得循环,在本文中设置了4层小循环,t (1~4),每个小得循环层间的状态转换可表示为如下的公式:
(1)
其中f是ReLU [15] 激活函数,g是局部响应归一化函数(LRN, local response normalization) [15] ,用于防止梯度爆炸,g的表达式如下所示:
(2)
f(z(t))缩写成f,其中K是feature map的个数,N是相邻feature map的大小,α和β是两个常量,分

Figure 2. Convolution process of the Region-CNN
图2. Region-CNN的卷积阶段
图3. RCL结构图
别设置为0.001和0.75。所以我们关注点应该落在z(t)上,它是一个单元的输入,而它由前馈参数和循环参数得到,其状态表示如下所示:
(3)
其中两个w分别是前馈网络权重和循环网络权重,分别表示为如图3所示的虚线和实线,u表示的是当前RCL层做卷积的那个单元,
表示为小循环层做卷积的单元,b表示为偏置。所以每个小循环的feature map都由整个RCL的输入,和上一层小循环层的输入得到,能够不断获取其局部上下文信息,提高图像feature map的精度。
结合图1,轮廓精度提升的模型总共包括4层,每一层都是独立开的,都由一个损失函数来确定其偏差,然后分别反向更新其权重。每一层都由一个65通道的RCL组成。第一次得到的结果为14 × 14大小的,将其与之前VGG的conv4_3层得到的feature map合并,得到一个65通道的feature map,然后得出一个精度稍提高的结果,将其上采样至28 × 28维再将其与VGG的conv3_3的feature map合并,同样得到一个65通道的feature map,以此类推,最后得到224 × 224高精度的显著性区域结果。这样做的原理是:因为层数的深度,每层都会产生计算偏差,但是在VGG模型中,随着层数的增加,其精度是由高到低的,所以只要结合VGG中每个阶段的feature map,就能逆向还原出高精度的结果。其中VGG模型每一层都得到不止64维的feature map,为了减少计算开销,将其裁剪至64维。
3. 训练方法
本文介绍的模型采用端到端的训练方式,以交叉熵 [16] 为损失函数进行训练。交叉熵为现在使用的较多的损失函数,其公式如下图所示:
其中y是标签,a是网络得出的结果,交叉熵的优势就在于,它可以克服权重更新较慢的情况,当误差较大的时候,其权重更新较快,当误差较小的时候,其权重更新较慢,这正是我们训练网络所希望出现的现象。
模型采用随机梯度下降算法(SGD)来训练,每次从样本库中抽取batch (本文设为32)个样本,训练网络模型,训练包括五个阶段,第一个阶段为特征提取网络权重的训练,经过第一个损失函数更新完权重后,输出直接作为下一层RCL的输入,到第二个损失函数时反向更新这层RCL的权重,直到最后一层。
4. 实验
数据集ECSSD包括1000张有意义但又复杂的图像,MSRA10K包括10,000张不同物体的图像,大部分都只有一个显著性目标,且背景非常简单。DUT-OMRON包括5168张一个或者多个显著性目标的图片,且其背景非常复杂。PASCAL-S包含850张真实场景下的图片,其中的显著性目标与背景都非常复杂。
实验结果如图4所示:第一列为输入图像,最后一列为标签,倒数第二列为本文模型得出的结果,其他的为现有的模型得出的结果,从结果上可以看出,本文的模型得出的结果相比其他模型结果要好很多,比如第三幅图,由于其背景比较亮,大多数模型都把背景识别成了显著性目标,但是本文模型可以较为精确得得到正确结果。见图5。
5. 总结
传统的显著性目标检测算法是根据人工提取的特征通过计算不同区域的对比来进行的,这样做在性
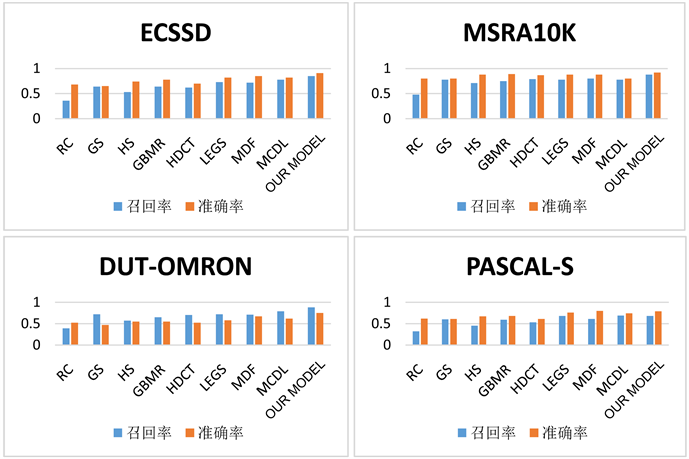
Figure 5. Our model compares the recall rate and accuracy with other algorithms in four data sets
图5. 本文模型与其他算法在四个数据集上的召回率和准确率的对比
能和结果上都不是很理想,本文提出了一个新的端对端训练的深度学习模型,在Region-CNN中增加了超像素的区域信息,在不断地参数以及性能优化后,能够提取图像的全局上下文信息,并通过RCL的图像精度提升来得到一个较好的结果。相对于其他模型,本文提出的模型在性能,召回率和准确率上都有比较理想的提升。