1. 引言
在科学研究的进程中,有这样一类问题:不同的研究者会对同一个问题进行研究,在研究实验过程中,总是通过实验组和对照组的比较给出一些问题的因果关系。由于不同的研究者所在的区域不同,研究的对象和实验条件有一定的差异,在实验中的样本量大小也各有不同,这就导致同一项研究得到的研究结论有一定的差异。同一科学研究问题结论的差异性会产生这样的疑问:如何对这同一问题给出一个综合的评价,得到一个具有统计学意义的因果关系呢?对于这一问题,我们需要对每一个研究者的研究进行合并,给出每一个研究在综合评价研究中的权重。并且要保证我们得到的综合评价是具有统计学意义的。
在上述问题中,一个科学问题需要客观评价时,将所有这一问题的各个研究的数据放在一起,这首先体现了数据的大量性;由于对同一个问题研究有着很大的差异性,因此得到的数据是多样的真实的。从这一问题的特点来看,这应该是最早的大数据问题。如何从这些复杂多样的数据中获得我们想要的信息,解决这一问题的方法称为Meta-分析法。
Meta-分析是针对同一问题的不同研究进行定量合并的综合评价方法。虽然Meta-分析在很多应用领域都有较好的应用,但对Meta-分析本身的统计方法研究相对少了很多。从广义上来讲,Meta-分析是以估计量标准误差的逆为权重的点估计加权平均。固定效应模型Meta-分析依赖于各个研究具有相等效应量,最终的效应量是以估计量方差的逆作为权重得到的加权平均效应量。虽然固定效应模型变量之间不允许有协变量,但是对固定响应模型的处理相对来说是很标准的。
随着数据科学的快速发展,各行各业数据维度和数据量急速增加导致单变量Meta-分析无法满足现实应用的需求。多变量Meta-分析方法应运而生并具有许多单变量Meta-分析不具备的优点,如整体性,相关性及优化参数等。针对多变量Meta-分析的理论研究也在不断深入。1988年,为了研究教练在SAT中的作用,Raudenbush SW等人通过广义最小二乘法建立了多效应量合并的模型 [1] ;2002年,van Houwelingen HC等人在广义多元混合线性模型的框架下,通过似然估计方法给出了多元Meta-回归模型,并将此模型扩展到了非正态分布情形 [2] 。2008年,Riley RD等人通过极大似然估计法给出了一些特殊相关系数情形下的二变量Meta-分析的协方差矩阵估计 [3] ;2008年,Ritz J等人通过极大似然估计和估计方程给出了协方差矩阵已知情形下的多元效应量回归参数,并将此模型应用到肺癌发病率的临床推断中 [4] 。2010年,Paul M等人通过基于可积嵌套拉普拉斯近似的贝叶斯方法给出了多元Meta-分析的合并效应量估计,这种方法得到的方差估计偏移量更小且稳定 [5] 。
本文通过极大似然估计法给出效应量及方差估计得到各研究均值效应量协方差矩阵的估计量。由基于均差效应量二变量Meta-分析的固定效应模型给出了合并均差统计量
的具体形式和权重,构建了基于均差估值的二变量Meta-分析的未知相等方差模型。进而得到了
的协方差矩阵和两个变量的
置信区间。
2. 问题描述
在协方差矩阵的基于均差估值的二变量Meta-分析的未知相等方差模型中,我们假设个体量
,
,
和
是独立的并且是正态分布,其均值分别为
,
,
和
,假设两个变量研究的方差分别为
,
。因此
,
,
和
是独立的且服从正态分布,其均值分别为
,
,
和
,方差分别为
,
,
,
。假设两个变量之间的关系是相互独立的。
由上述假设,可以得到均差效应量
的分布为:
其中
,
为均值,
,
及
是非随机的。一般地,
,
为未知参数。接下来通过极大似然估计法来估计
,
。
3. 均值效应量的极大似然估计
根据之前的假设效应量
服从正态分布,因此关于
的似然函数为:
其中
,
。其所对应的对数似然函数为:
定理3.1设效应量
服从正态分布
,则
1).
的极大似然估计量的分量为:
。
2).
的极大似然估计量分别为:
。
证明:因为关于
的似然函数为:
其所对应的对数似然函数为:
1). 上述对数似然函数对
,
的偏导数为:
令
即得:
因此上述关于
的线性方程组的解为:
。
2). 上述对数似然函数对
的偏导数为:
令
,
即得:
因此上述关于
的方程组的解为:
。
将
代入上式即得:
。
注:由上述定理可知,
,其中
;且
。
由上述效应量
服从正态分布的合并效应量均值估计量分量的具体形式,可以得到合并效应量均值估计量的如下性质:
性质3.1 设效应量
服从正态分布
,
的极大似然估计量的分量为:
。则
对于
是无偏的。
证明:要证明估计量的无偏性,需证等式
成立.根据我们给出的效应量
服从正态分布的合并效应量均值估计量分量的具体形式,需要证明
,
。因为
,
,所以
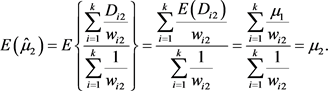
综上所述,
对于
是无偏的。
4. 均值效应量极大似然估计量的协方差矩阵
假设所有的研究都提供所有的均值效应.由多变量统计学的大数定理,合并效应量均值估计量可以近似为一个多元正态分布,其对应的协方差矩阵可由下面的定理给出:
定理4.1 设效应量
服从正态分布
,那么
的合并均值效应量极大似然估计量为:
。则 所对应的协方差矩阵
为:
所对应的协方差矩阵
为:
证明:根据多元随机变量可知:如果随机变量
,
,其中T表示矩阵
的转置。
因为合并均值效应量极大似然估计量的矩阵形式为:
,且
,其中
由
及
为对角矩阵,通过计算可得:
,
,
,
,
。则
由
及
可得
所对应的协方差矩阵
为:
。
通过合并均值效应量极大似然估计量
所对应的协方差矩阵
可以给出
的如下性质:
性质4.2 设效应量
服从正态分布
,那么
的极大似然估计量的分量为:
。则
对于 是一致的。
是一致的。
证明:
对于
的一致性的充分条件是证明
并且
。
由性质3.1可知,对于任意的k都有
成立,因此可得
。又因为在合并均值效应量极大似然估计量
所对应的协方差矩阵
中有:
即得
。综上所述,
对于
是一致的。
5. 整体均值合并统计量的估计
在上述研究中,效应量用的是均差。因此我们可以给出均值效应量
的协方差估计为:
,其中
。
在Meta-分析中,合并统计量是由具体研究表现统计量的加权平均给出的。根据均差估计二变量Meta-分析的固定效应模型可知,通过
可以给出每一个研究的权重及均差合并统计量。具体如下:
1). 对于均值合并统计量,每个研究均差的权重为:
注意到权重
只与个体研究的样本量有关并且是非随机的。
2). 整体均值合并统计量的估计量为:
从上式我们注意到,
与合并均值的极大似然估计量
的结果是一致的。因此
的协方差阵的估计量为:
通过
所对应的协方差矩阵
可以给出单变量和联合变量的置信区域,其具体形式为:
性质5.1 设效应量
服从正态分布
,那么合并均值效应量
的估计量为:
。则合并均值效应量
所对应各个分量的
置信区间为:
和
,其中
表示正态分布的
分位数,
表示矩阵
第i行第j列的分量。
6. 结束语
本文通过极大似然估计法给出效应量及方差估计,进而得到各研究均值效应量协方差矩阵的估计量。然后,由基于均差效应量二变量Meta-分析的固定效应模型给出了合并均差统计量
的具体形式和权重,构建了基于均差估值的二变量Meta-分析的未知相等方差模型,进而得到了
的协方差矩阵和两个变量的
置信区间。本文的结果对流行病学的研究有着重要的统计学意义。
声明
本项目由如下基金支持:国家自然科学基金(61871475, 61471133, 61571444, 61473331),广东省科技计划(2017B010126001, 2017A070712019, 2016A040402043, 2015A070709015, 2015A020209171, 2016B010125004, 2014B040404070, 2015A040405014, 2016A070712020),广东省教育厅科技计划(2017GCZX001, 2016GCZX001, 2017KTSCX094, 2017KTSCX095, 2017KQNCX098),广州市科技计划(201707010221)。
参考文献
NOTES
*通讯作者。