1. 引言
我国正处于国际国内形势严峻、人民内部矛盾凸显、刑事犯罪高发的时期,刑侦部门打击刑事犯罪、保护人民生命财产、维护社会稳定的任务更加繁重而艰巨。随着计算技术、网络技术、通信技术和Internet技术的发展,公安行业积累了大量的业务数据,这些数据和由此而产生的信息、情报、知识是侦查破案、打击犯罪、保持社会稳定和维护治安秩序的关键,是公安行业的最大财富。本文针对已有方法存在的问题,提出了将Minitab、贝叶斯和决策树方法进行比较研究,比较了三种方法的犯罪挖掘复杂性、预测准确度。并对模型结果进行了可视化编程实现。
2. 相关工作
一些学者,在犯罪网络分析与犯罪数据挖掘的研究中,提出了犯罪数据挖掘的一些方法,为犯罪数据挖掘的理论发展做出了重大贡献。数据挖掘应用于犯罪集团或恐怖组织社会网络分析是一种新兴的研究方法,国内外在分析犯罪和恐怖组织之间通信行为方面的研究工作亟待深入 [1] ,为了挖掘犯罪网络的核心成员,乔少杰等 [1] 提出了一种基于社会网络分析挖掘犯罪组织核心成员的算法CNKM (Crime Network Key Member Mining),通过使用合适的通信数据流分析工具,模拟和分析社会网络中具有不同个性特征个体的通信规律,并检测异常通信行为,进而达到预测犯罪/恐怖活动的目的,为我们进行犯罪数据挖掘提供了一个思路和参考。金光等 [2] 用数据挖掘中的决策树技术对犯罪行为进行分析,给出了一个较为成功的挖掘思路和模式,得出了一个犯罪风险预测模型。黄建设等 [3] 利用数据挖掘技术对犯罪行为进行分析,得出了数据挖掘技术在犯罪行为分析中的应用方案。李万彪等 [4] 通过为期半年的通话与转账数据作为数据源进行实验,利用社会网络分析手段进行犯罪网络分析,分析数据特点,建立关系数据模型,从各类数据资源中发掘犯罪团伙信息。杨莉莉等 [5] 通过对犯罪组织重点人员的判定以及犯罪组织成员间关系的分析,提出了基于社会网络的犯罪组织关系挖掘方法。G. C. Oatley等 [6] 研究了匹配和犯罪预测技术在智能系统中的应用。R. William Adderley [7] 在其博士论文中,利用数据挖掘技术进行犯罪趋势分析,并给出了犯罪数据挖掘方法的一个框架。吴绍兵 [8] 采用贝叶斯网络和EM算法来分析影响某地区刑事犯罪的影响因素,给出了影响因素模型,并由该模型得出,影响该地区的刑事犯罪的因素依次是人的因素、环境因素、犯罪类型因素、犯罪位置因素和交通因素等。
以上对犯罪数据挖掘的研究,大多是针对犯罪数据挖掘的算法,进行理论的研究,而实现和可视化应用研究的较少,本文针对已有方法存在的问题,提出了将贝叶斯、Mintab和决策树三种方法结合的犯罪数据挖掘方法,实验结果表明,该贝叶斯方法的挖掘效果优于Minitab和决策树。
3. 数据挖掘方法
3.1. 数据挖掘概述
数据挖掘(Data Mining, DM)是指从大量数据(包括文本)中挖掘出隐含的、未知的、对决策有潜在价值的关系、模式和趋势,并用这些知识和规则建立用于决策支持的模型,提供预测性决策支持的方法、工具和过程。数据挖掘的目的就从数据中“淘金”,就是从数据中获取智能的过程 [9] [10] 。
3.2. 数据挖掘方法
3.2.1. 数据预处理
数据预处理就是数据中包括的不一致性数据、缺失数据、重复数据、不合理数据、虚假数据、异常数据、逻辑错误数据、非结构化数据、半结构化数据等变为计算机可处理的结构化数据。主要包括抽样、降维和去噪 [11] 三个阶段。文献 [12] 从公共数据库的角度提出数据清洗应尽量满足如下要求:
① 尽量放松清洗规则,保证数据的原样性;
② 在清洗过程中,只能作数据映射,不能修改用户数据,不对错误数据进行纠正;
③ 清洗的数据要保存。
1) 抽样
抽样是数据挖掘从大数据集中选择相关数据子集的主要技术。它用于预处理和最终解释步骤中。之所以使用抽样是因为处理全部数据集的计算开销太大。抽样的关键是发现具有整个原始数据集代表性的子集,其具有与整个数据集大概类似的兴趣属性。最简单的抽样技术是随机抽样,任意物品被选中的概率相同。
2) 降维
随着大数据时代的到来,不仅有定义高维空间特征的数据集,也有在空间中信息非常稀疏的数据集。稀疏和维度灾难是大数据挖掘中反复出现的问题。即使在最简单的背景下,也很可能会有成千上万条记录的行和列稀疏矩阵,其中大部分值是零。因此降低维度就自然而然的了。在大数据挖掘中,最相关的降维算法有两个:主成分分析(PCA)和奇异值分解(SVD)。
3) 去噪
数据挖掘中采集的数据可能会有各种噪声,如缺失数据,或者是异常数据。去噪的目的是在最大化信息量时去除掉不必要的影响。
3.2.2. 数据分析
数据分析是从大量数据中发现有趣、有价值的信息,是整个数据挖掘过程的核心部分。而数据分析的成功与否不仅与研究者所运用的一系列理论、算法有关,还与数据分析所涉及的具体领域有着重要的关系。
3.2.3. 结果评价与展示
数据分析的目的是为了让用户能够从中获得有用的信息并对结果进行评价。其难点在于用户并不具备相应的专业知识,因此需要更加具体与形象化的表示,例如可视化技术。这也正是大数据环境下数据挖掘中的一个研究热点与难点。大数据处理的基本流程是数据挖掘思想在大数据环境中的具体表现,因此有很多的相似之处 [13] 。
3.3. 数据挖掘算法
3.3.1. Minitab
根据百度百科记载,Minitab软件是现代质量管理统计的领先者,全球六西格玛实施的共同语言,以无可比拟的强大功能和简易的可视化操作深受广大质量学者和统计专家的青睐。Minitab 1972年成立于美国的宾夕法尼亚州州立大学。
目前从新兴企业到全球500强公司大都选择Minitab作为改善流程、提高质量的首选软件,它是现代质量管理统计的领先者,是六西格玛管理中必需的统计分析软件,更是持续质量改进的良好工具软件,它的核心功能就是进行数据分析、图形分析以及趋势预测。本文使用Minitab 16.0版作为分析辅助工具,主要使用里面的回归分析模块。
3.3.2. 贝叶斯犯罪挖掘算法
被称为先验概率,是根据以往经验获得的在已知状态
的情况下
的分布。对于企业创新风险。先验概率就是在以往经历的失败或者成功的创新活动中,各风险指标的分布情况。在风险指标为离散值的情况下,先验概率可以通过统计历史数据的方法得到。
(1)
贝叶斯定理:由总体信息(
)、先验信息(
)和样本信息(
)得出,后验概率(
)。
贝叶斯犯罪挖掘算法步骤:
第一步:已知总体信息、样本信息和先验信息概率
第二步:利用贝叶斯公式转换成后验概率
第三步:根据后验概率大小进行决策分类
3.3.3. 决策树
决策树 [11] [14] 是以树结构形式对目标属性(或类)进行分类的分类器。要分类的观察数据(或物品)是由属性及其目标值组成的。树的节点可以是:1) 决策节点,在这些节点中一个简单属性值被测试来决定应用哪一个子树;2) 叶子节点指示目标属性的值。
4. 基于Minitab、贝叶斯与决策树的犯罪数据挖掘应用研究
根据上节所述的大数据挖掘相关方法,为简化计算,采用随机抽样的方法,从我们收集的某民族地区的犯罪数据中抽样选取如表1的数据作为分析研究的样本数据。
4.1. 基于Minitab对犯罪数据的挖掘
Minitab软件是由1972年成立于美国宾夕法尼亚大学的Minitab Inc.公司开发的。目前从新兴企业到全球500强公司大都选择Minitab作为改善流程、提高质量的首选软件,它是现代质量管理统计的领先者,是六西格玛管理中必需的统计分析软件,更是持续质量改进的良好工具软件,它的核心功能就是进行数据分析、图形分析以及趋势预测。本文使用Minitab 16.0版作为分析辅助工具,主要使用里面的回归分析模块。

Table 1. Sample data of a national police crime analysis
表1. 某民族公安犯罪行为分析样本数据
基于单因素试验设计,对优化工艺条件进行了一系列的试验,在最陡爬坡试验的基础上,根据Box-Benhnken的中心组合试验设计原理。利用Design-Expert8.0.6进行响应面法优化。影响某民族地区犯罪行为的7个主要因素:年龄(x1),经济状况(x2),文化程度(x3),正当职业(x4),犯罪记录(x5),特长(x6),常驻人口(x7),考察目标为犯罪程度(y),试验因素水平安排以及根据以上水平编码设计试验表格并检测响应值结果见表2。
Table 2. Crime data coding table for a certain ethnic area
表2. 某民族地区犯罪数据编码表
对表2数据进行二次多元回归拟合,可求出影响因素的一次效应、二次效应以及交互效应的关联方程并可绘制出响应面图。该模型通过二阶经验模型对变量的响应行为进行表征,即:
(2)
式中:y代表响应值;
、
、
表示偏移项、线性偏移和二阶偏移系数;
是交互效应系数;
——各因素的编码值。以x1,x2,x3,x4,x5,x6,x7为自变量,y为响应值,利用Minitab 16.0进行响应曲面回归分析得如表3:y的回归系数和表4:y的方差分析:
Table 3. Estimated regression coefficients for y
表3. y的估计回归系数
从而,得响应面方程得:
(3)
最后,由(3),利用Minitab工具得出的模型,采用C#设计实现了如下可视化界面(图1,图2)。

Figure 1. Crime prediction based on Minitab
图1. 基于Minitab的犯罪预测
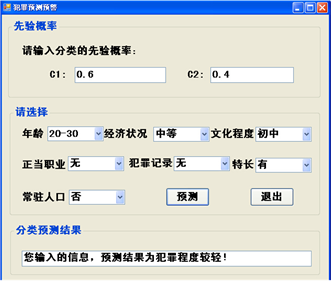
Figure 2. Bayesian-based crime prediction
图2. 基于贝叶斯的犯罪预测
4.2. 基于贝叶斯方法的犯罪数据挖掘应用
由上表可知,将对犯罪程度进行分类的过程归结为典型的两类问题,根据以上的分类规则则可判定任意一个犯罪行为,是较轻,还是严重。
其中:C1表示,犯罪行为的犯罪程度较轻,C2表示犯罪行为的犯罪程度较重。选取上表中的10个数据构成的表5作为训练数据,另外的数据作为测试数据。
由表5得到:
,
;
对未知样本X = (年龄为20~30,经济状况 = 中等,文化程度 = 初中,正当职业 = 无,犯罪记录 =无,特长 = 有,常驻人口 = 是),进行分类;
P (年龄 = 20~30|犯罪程度 = 较轻) = 0.5;P (年龄 = 20~30|犯罪程度 = 较重) = 0.74;
P (经济状况 = 中等|犯罪程度 = 较轻) = 0.333;P (经济状况 = 中等|犯罪程度 = 较重) = 0.25;
P (文化程度 = 初中|犯罪程度 = 较轻) = 0.501;P (文化程度 = 初中|犯罪程度 = 较重) = 0.25;
P (正当职业 = 无|犯罪程度 = 较轻) = 0.333;P (正当职业 = 无|犯罪程度 = 较重) = 0.5;
P (犯罪记录 = 无|犯罪程度 = 较轻) = 0.667;P (犯罪记录 = 无|犯罪程度 = 较重) = 0.25;
P (特长 = 有|犯罪程度 = 较轻) = 0.167;P (特长 = 有|犯罪程度 = 较重) = 0.5;
P (常驻人口 = 是|犯罪程度 = 较轻) = 0.5;P (常驻人口 = 是|犯罪程度 = 较重) = 0.25;
利用以上结果,根据公式(1)分母相同,可以不用计算,只比较分子即可,
记
(4)
可得;
(5)
Table 5. Analysis of criminal behavior in a certain ethnic area
表5. 某民族地区犯罪行为分析表
所以,

分类结果为C1,犯罪程度较轻,对照表,是吻合的。
为了方便使用,我们在基于表5的情况下,计算出了各条件概率如表6。最后,利用贝叶斯理论,采用C#语言程序设计实现了如图2所示的界面。
Table 6. Criminal behavior analysis sample data conditional probability table
表6. 犯罪行为分析样本数据条件概率表
4.3. 基于决策树算法的犯罪数据挖掘应用
4.3.1. 选取挖掘目标和采集数据
笔者选择某犯罪行为过程分析数据,希望通过数据挖掘,从中分析出:影响犯罪程度的因素,并得出犯罪程度较轻和犯罪程度严重的分类规则。即,挖掘出犯罪程度。从而为社会治安综合治理以及人员的管控提供决策依据。
4.3.2. 决策树算法的数据挖掘过程
1) 决策树模型的分类原理
a) 决策树的枝干和叶节点是如何生成的?
b) 节点的选取
i) 划分节点时,模型所需的信息量最小
ii) 能生成一个相对简洁的树
c) 基于信息熵的原理
熵是自信息量的数学期望,它是一种信息的度量,属性变化越多,熵越大。
2) 类别熵
根据熵的定义,把类别看作随机变量,并给出相应的计算熵的公式(6):
(6)
由本文的数据集,C1:较轻;C2:较重;
,
3) 条件熵
根据条件熵的定义,及如下公式(7),可得出第一个变量X1:年龄的条件熵。
(7)
由数据表可知,
= P (年龄为20~30) = 0.5,
= P (年龄为30~40) = 0.3,
= P (年龄40) = 0.2;
所以,
因而,
4) 信息增益
由类别熵减去条件熵,得到该属性的信息增益。最后根据所有属性的信息增益来确定根节点和其他枝干节点。信息增益由下面的公式(8)给出:
(8)
于是,对于上面的年龄属性的信息增益,可计算得:
同理,可根据条件熵,得出其他属性的信息增益为:
5) 决策树的生成
通过上面计算的信息增益,可得如下的信息增益表7。
Table 7. Information gain table with economic status
表7. 含经济状况的信息增益表
其中,信息增益值最大的属性为经济状况,于是,决策树的根节点,就是经济状况。
去掉经济状况属性,用上面的方法,得到信息增益表为表8。
Table 8. Information gain table without economic status
表8. 不含经济状况的信息增益表
其中,信息增益值最大的属性为常驻人口,于是,决策树子树的根节点,就是常驻人口。
重复此步骤,可生成决策树,如图3。
4.3.3. 决策树挖掘规则应用
根据犯罪数据挖掘决策树,可以直接提取出犯罪预测分类规则:
1) IF经济状况 = 中等,THEN犯罪程度 = 较轻;
2) IF经济状况 = 差and常驻人口 = 否,THEN犯罪程度 = 严重;
3) IF经济状况 = 差and常驻人口 = 是and正当职业 = 有,THEN犯罪程度 = 较轻;
4) IF经济状况 = 差and常驻人口 = 是and正当职业 = 无,THEN犯罪程度 = 严重;
利用决策树方法挖掘犯罪防控的有用信息,根据分类规则找出与研究对象有关联的信息,方便警务工作者科学决策,并作出相应的警务模式改革。

Figure 3. Crime prediction decision tree
图3. 犯罪预测决策树
4.4. 三种犯罪数据挖掘方法的分析比较
本节,我们采用Minitab、贝叶斯和决策树三种方法对犯罪数据进行挖掘。Minitab方法在进行编码的情况下,由软件工具自动计算生成犯罪预测模型,方法直观,计算量小。贝叶斯方法由于要计算先验概率、条件概率及后验概率,使得计算量比Minitab大一些。而决策树方法由于要计算总熵、条件熵、信息增益,全部属性的信息增益算完后,再比较大小,才产生决策树的根节点,依次类推,直到生成一棵决策树。通过对三种方法进行预测准确性的测试,得出预测准确性见表9。
Table 9. Comparison of crime data mining in three methods
表9. 三种方法的犯罪数据挖掘比较情况表
5. 结论
分类方法是数据挖掘的重要方法之一,其应用领域非常广泛。将基于Minitab、贝叶斯和决策树理论的分类器应用于犯罪数据挖掘领域,通过对人的初步判断,可对该人的犯罪风险程度进行准确地分类,从而可实现对不同的人员实施不同的管理策略,促进社会的和谐发展,人民的安居乐业。本文采用Minitab、贝叶斯和决策树三种方法对犯罪数据进行了挖掘。并对Minitab和贝叶斯方法得出的模型进行了可视化编程实现。决策树方法的编程实现以及三种方法的融合研究,加强抽样、降维、去噪等预处理技术的研究,提高预测准确性等,将是下一步工作的目标。
基金项目
国家社会科学基金项目(13CFX038);云南省教育厅科学研究基金项目(2013C188);云南警官学院教育教学改革项目(2018YJJGB01)。
参考文献
NOTES
*通讯作者。