1. 引言
随着互联网和数字多媒体的快速发展,数字音乐服务受到了人们的广泛欢迎,如何帮助用户在海量的音乐中快速而准确的找到想要的音乐,成为了音乐推荐研究领域的热点。目前音乐心理学研究领域表明,音乐在其听众中引起了明显的情绪反应,证明了音乐偏好与用户情绪高度相关,例如用户当前心情很失落、伤心,很想听一些轻音乐舒缓一下心情。
在音乐个性化推荐领域主要有三类不同的推荐算法:基于内容的推荐算法 [1] ,该方法主要是通过获取用户的最近收听记录和音乐的音频特征和网络标签,并计算历史音乐与待预测音乐的相似度和用户与待预测音乐的匹配度,即为用户推荐最近播放音乐的相似音乐;协同过滤推荐算法 [2] ,该方法主要是利用用户之间的相似偏好,来挖掘用户的潜在偏好。主要包括启发式和基于模型两种类型,其中启发式方法是通过用户的历史偏好差异计算用户之间的相似度,然后依据用户的历史偏好和用户之间的相似度计算用户对于待预测音乐的偏好度;基于模型的协同过滤方法是在用户所使用的偏好信息基础上,构建一个有效的预测模型,然后依据用户的实时数据来预测用户对于音乐的潜在偏好,最后把预测的结果生成给目标用户。构建一个优秀的用户偏好预测模型是算法应用过程中的重要部分,目前许多的优秀模型如矩阵分解模型、聚类模型、贝叶斯网络模型等被应用在基于模型的协同过滤推荐算法中。协同过滤推荐算法善于挖掘用户新的兴趣点、可处理复杂的非结构化对象,缺点就是存在数据稀疏性和冷启动问题;混合推荐算法,即使用不同的混合方式将基于内容的推荐算法和协同过滤推荐算法混合,再将预测音乐推荐给目标用户。
本文提出了一种融合面部表情和社交网络行为分析的音乐推荐方法,将用户情境信息融合到推荐算法中去 [3] [4] [5] 。本方法通过在用户的自适应音乐推荐系统中结合情绪情境的推理能力,将面部表情融合到音乐推荐中去,结合用户的社交网络状态建立用户情绪与音乐类型的关联,计算用户在某种情绪下对音乐类型的偏好程度,最后根据用户的实时情绪推荐其当前可能喜欢的音乐。
2. 相关工作
传统的音乐推荐引擎大多单单使用基于内容或协同过滤方法,而不考虑用户的情绪状态,忽略了音乐是用户精神消费品的本质。如用户处于情绪高涨、心情愉悦的时期,却向其推荐伤感的音乐,显然是不合适的。
与传统的音乐推荐相比,近年来,很多学者提出了融入用户情绪因素的音乐推荐方法。如Shin等 [6] 提出来一种自动缓解压力的音乐推荐系统,系统使用无线和便携式手指型PPG传感器来检测用户的情绪。Deger等 [7] 提出来一种基于情感的可穿戴式生理传感器音乐推荐系统,主要是通过测量用户的心率、皮肤电流来反映用户的情绪,将情绪信息作为补充数据被馈送给任何基于内容或协作的推荐引擎。shan等 [8] 提出了基于影视音乐的特性来实现为用户不同情绪状态下推荐不同的音乐,但从影视剧音乐学系得来的情绪特性与用户的实际情绪有较大的差别。Yoon等 [9] 提出通过用户的收听历史 [10] [11] 、上下文信息 [12] [13] [14] [15] [16] 等选定的特征来实现个性化音乐推荐 [17] [18] 。琚老师等 [19] 提出了融入音乐子人格和社交网络行为分析的音乐推荐方法,但是音乐子人格是文化沉淀的结果,不具有个性化和代表性。而且实时情感分析是通过分析用户的社交媒体状态,实时性和准确性不强。
3. 融合社交网络行为分析和面部表情的音乐推荐
3.1. 用户知识模型
基于情境感知的个性化音乐推荐模型是将用户个人信息、情境信息(情绪状态)、音乐资源(类型标签)紧紧联系起来,进行了统一语义的融合。如图1所示。
3.2. 基本定义
定义1 (用户集合)
,U表示用户,S表示用户的ID集合。
定义2 (用户k的情绪状态)
= {快乐,悲伤,愤怒,中立},
,
表示ID为k的用户的情绪状态。
定义3 (音乐集合)
,M表示音乐,I表示音乐ID集合。
定义4 (音乐 的风格)
= {流行,民谣,英伦/爵士,轻音乐,古典,摇滚,说唱},
,
表示ID为i的音乐的风格。
定义5 (用户情绪-音乐类型关联)
,R表示用户情绪-音乐类型关联四元组,k表示用户ID,i表示音乐ID,
表示用户k的情绪状态,
表示用户k对音乐i所属类型的偏好度。
3.3. 社交网络行为分析
伴随着网络技术的发展以及计算机的普及,各类社交网络服务( Social Network Services,SNS)软件诸如Facebook、Twitter、微博、微信等出现并得到广泛使用。这些软件为用户提供多种沟通交流的方式,如在线聊天、发布动态、文件共享。本文主要研究微博动态的行为分析。
本文社交网络行为分析主要分析用户带有情绪的微博动态以及前后30 min收听的音乐记录,计算用户对音乐的偏好度,将用户情绪与音乐类型关联起来,构建用户知识模型。本文将用户的情绪归纳为4种,分别是快乐、悲伤、愤怒和中立。
3.3.1. 音乐底层特征提取
现有的音乐平台一般在引入歌曲时,都会有歌曲自带标签,根据标签为用户推荐同种口味的歌曲,有欢快、轻音乐、古典、伤感、摇滚等。
3.3.2. 用户情绪-音乐类型关联
不同用户在相同情绪状态下对同一首歌曲的偏好程度不一样,同一用户在不同情绪状态下对同一首歌曲的偏好程度也不一样。因此,为了挖掘用户在不同情绪状态下对音乐的偏好程度,需结合用户的微博等社交媒体动态和用户的音乐收听记录,为每一个用户建立情绪与音乐类型之间的关联,构建<用户,音乐类型,情绪,偏好度>四元组。
1) 微博情感分析
抽取用户发布的带有情绪词并且在此前后30分钟有听歌记录的社交动态,用户的点播记录与社交动态越近,表明在该情绪状态下对音乐所属类型的偏好程度越高。
对于用户发布的某条社交动态,本文采取汉语词法分词系统进行预处理。
2) 音乐偏好度
当用户发布一条带有情绪的微博动态时,本文认为只有在该条动态发布的时间点附近用户所点播的音乐是用户在该情绪状态下喜欢的音乐。用户点播音乐的时间点离微博动态发布的时间越近,时效性越强,用户的偏好度越高。本文用数值0~10表示用户对该类型音乐的偏好度,数值越大,偏好度越高,并构建<用户,情绪,音乐类型,偏好度>四元组。
用户在某情绪状态下对某类型音乐的偏好度通过时间加权求和的计算方式如式(1)所示。
(1)
其中
为时间窗口长度(本文取值30),
为音乐时长,t为微博动态发布的时间,
为第i首音乐点播的时间,
为第i首音乐播放结束的时间,
为第i首音乐所属类型的偏好度,n为时间窗口内符合条件的所有音乐总数目。
3) 基于用户上下文的张量分解
通常我们将一位数组称之为向量(vector),二维数组称之为矩阵(matrix),三维及以上数组称之为张量(tensor)。张量是一种矩阵到高阶情形的延伸,拥有N个维度就被称为N阶张量。张量分解类似与矩阵分解,能够完整的表示高维数据以及空间数据的结构信息,因此张量分解方法在推荐系统中受到广泛欢迎。在本文中,张量分解能够补充用户、上下文和音乐类型变量构成的稀疏张量缺失的评分值,将张量分解得到的紧凑偏好值用于最后根据某个用户情绪变化推荐的TOP-N音乐列表中 [20] 。
典型的张量分解方法主要有CP(Candecomp/Parafac)分解和Tucker分解,Tucker分解是一种高阶的主成分分析,它将一个张量表示成一个核心(core)张量沿每一个mode乘上一个矩阵。因为Tucker分解是对于三阶张量来说,三个向量长度不等的情况下,因此本文采用的是Tucker分解。建立移动用户-情绪-音乐类型三阶张量分解模型如图2所示。

Figure 2. Third-order tensor tucker decomposition model
图2. 三阶张量tucker分解模型图
在本文中,其Tucker分解为式(2)所示。
(2)
三阶Tucker分解的展开形式如式(3)所示。
(3)
三阶张量
被分解成核心矩阵G和三个分别代表移动用户U、用户情绪E和音乐类型M的因子矩阵,其中核心张量
,各因子矩阵
,
,
。此模型进行偏好预测时,为了获取最优的预测值,
和
需要满足下式:
(4)
其中
为实际偏好值,
为预测偏好值,λ1和λ2为避免过度拟合加入的正则化参数,使得G,U,E,M具有相同的数量级,
为张量U的Frobenius范数。
3.4. 面部表情分析
面部表情是传达情感,情绪和感受的最古老和最自然的方式,精准的情绪识别能够帮助开展各类基于人脸表情分析的复杂工作,例如广告精准投放、用户的产品满意度分析、在线教育等。在本文中,我们是将面部表情分析应用于音乐推荐中去,为了更方便描述情绪,我们将面部表情分为4种不同的情绪类别,即快乐,悲伤,愤怒和中立。
在本节中,我们研究卷积神经网络(CNN)在情绪识别中的用法。卷积神经网络包括输入层、卷积层、密集层和输出层,可以实现图片的特征提取和降维。本文的神经网络结构如图3所示。
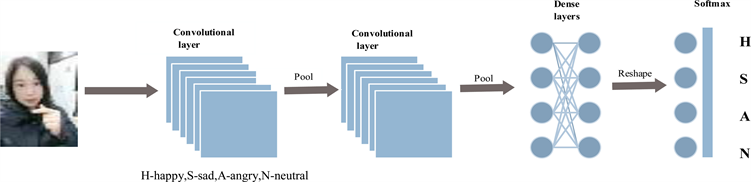
Figure 3. Convolutional neural network structure
图3. 卷积神经网络结构图
3.4.1. 卷积神经网络
从2013年以来,卷积神经网络模型在特征识别、图像处理等任务中取得的效果,远远超过传统方法。因此,卷积神经网络在语音识别、图像识别等领域应用广泛。卷积神经网络包含输入层,卷积层,汇集层、一些密集层(也称为完全连接层)和输出层。
1) 输入层:输入层需要预定尺寸,因此,为了对图像进行预处理,我们在将图像馈送到图层之前使用OpenCV进行图像中的面部检测。使用来自Haar预先训练过的滤波器用于快速找到并裁剪脸部。然后将裁剪的面部转换为48 * 48的灰度图像。
2) 卷积层:每一个特征检测器都是一个接收域,它在原始图像上滑动并计算特征图,卷积为同一输入图像生成不同的特征映射。在我们的神经网络中,每个卷积层生成256个特征映射,每个卷积运算后都使用了直线线性单位。在每一组卷积层之后,使用流行的MaxPooling来减少每个特征映射的维度,同时保留关键信息。
3) 密集层:卷积和池化层的输出表示输入图像的高级特征。密集层使用这些功能将输入图像分类为各种类。这些特征通过训练数据的前向传播然后向后传播其错误来训练网络。
4) 输出层:我们使用softmax作为密集层输出层的激活函数。因此,输出层表示每个情绪类别的概率分布。
3.4.2. 情绪识别方法
人脸表情识别的关键之处在于面部特征的提取和分类器的训练。传统的人脸表情识别方法主要有Gaber小波变换、局部二值模式(Local binary patterns LBP)。Gaber小波在图像处理和计算机视觉方面有着广泛的应用,Gaber函数经常作为线性滤波器进行边缘检测、纹理分析以及视差估计等。LBP描述符是一种局部特征,具有灰度不变性、旋转不变性、扩展方便和对方向信息敏感等特点。
目前,大部分学者利用卷积神经网络来实现面部表情识别。CNN是一个前馈式神经网络,能从一个二维图像中提取特征,从一端的原始图像像素到另一端的分类类别,在最后一个全连接层存在一个损失函数(例如Softmax损失函数)。
卷积神经网络的训练包括两个阶段:
1) 前向传播阶段。从训练样本集中抽取一个样本x,其对应的类别标签为y,将x输入到CNN网络,上一层的输出就是当前层的输入,然后通过激活函数计算出当前层的输出,逐层传递下去,最后得到Softmax层的输出
。
2) 反向传播阶段,也称为误差传播阶段。计算Softmax层的输出
与给定样本的类别标签向量y的误差,并使用最小化均方误差代价函数的方法调整权值参数。
4. 结果分析
4.1. 数据集描述
在本文中,我们使用了两个数据集,数据集一是我们用于训练人脸表情识别模型,是来自Kaggle面部表情识别挑战,该数据由面部的48 * 48像素灰度图像组成,每个面孔被归类为“愤怒、厌恶、恐惧、快乐、悲伤、惊讶,中立”7种情绪中的一种。数据集二是来从”酷我音乐”网站获取的信息,“酷我音乐”里的推荐分类有一个心情分类,就爬取了情绪、歌曲列表、播放次数、音乐标签等。
4.2. 实验分析
本次实验主要是对面部表情进行分析以及对加入情绪的推荐结果进行对比。
1) 由图4和图5所知,面部表情分析相比2013年Kaggle面部表情识别挑战赛最高准确率为34%有较高的正确率,可以较为准确的分析用户的情绪。

Figure 4. Model accuracy rate rendering
图4. 模型准确率效果图
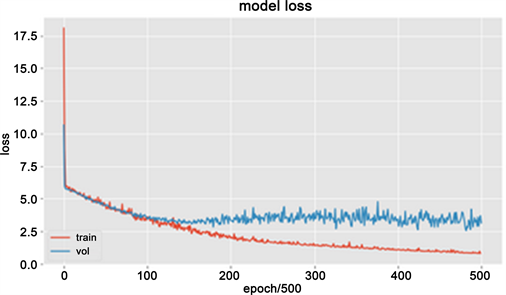
Figure 5. Model loss function rendering
图5. 模型损失函数效果图
2) 利用已被标记偏好度的音乐m,计算用户u对未被标记音乐n的偏好度。首先计算音乐m与音乐n之间的相似度,如式(5)所示。
(5)
设置相似度阈值s,取相似度值大于s的音乐作为音乐n的最近邻,
表示音乐n的最近邻音乐集。利用式(6)来预测音乐n的偏好度p。
(6)
本文采用MAE和P@N作为加入情绪后的推荐结果。MAE值是被用来比较预测的用户偏好度和用户的实际偏好度,具体定义如式(7)所示。
(7)
由图6可知,本文基于协同过滤推荐算法分别使用余弦、Pearson和基于项目的相似度计算方法比较,融入情绪的推荐算法具有较小的MAE值。

Figure 6. Comparison of recommendation algorithms for emotional integration into MAE
图6. 融入情绪的推荐算法MAE比较
P@N是根据推荐集中TopN的音乐与目标用户实际偏好度前TopN的音乐做比较,计算其准确度。本实验与传统协同过滤算法作比较,由图7可知,融入用户情绪的推荐算法相对于未融入用户情绪的推荐算法准确率较高。
P@N = 推荐列表中TopN音乐包含用户实际偏好TopN的音乐数量/N。

Figure 7. Comparison of recommendation algorithms P@N incorporating user emotions
图7. 融入用户情绪的推荐算法P@N比较
5. 结束语
本文针对目前许多音乐推荐忽略用户情绪的情况,提出了一种融合社交网络行为分析和面部表情的音乐推荐方法。首先根据用户历史数据建立<用户、情绪、音乐类型、偏好度>四元组,然后充分利用目前时兴的面部识别技术判断用户的情绪,最后为用户实时推荐其当时可能感兴趣的音乐。
但是,本文工作还存在许多改进的地方,比如用户没有历史数据的冷启动问题,面部表情分析的准确性问题。未来,这将作为工作的一部分,进一步提高音乐推荐的性能。
基金项目
本文得到国家自然科学基金项目(No. 61572144),广东省科技计划项目(No. 2017B030307002, 2015B010110001, 2016B030306002)的资助。