1. 引言
叶绿素a (Chl.a)浓度是衡量水体富营养化程度的重要水质参数,由于湖泊藻类爆发和消亡速度很快,传统的采样监测不能及时反映湖泊藻类水华的发生和发展,自动监测站可以高频率地获取水质数据,但是由于费用较高,往往不能布设很多监测位点,不能获取湖泊藻类爆发的空间分布情况。遥感估算叶绿素a浓度可以实现高时间频率、且空间上连续覆盖整个湖区的监测数据,可以更好地、详细地掌握湖泊藻类水华的发生和发展情况。
针对内陆水体的叶绿素a遥感估算的方法主要有经验模型法、半经验模型法和生物光学模型法 [1] [1, 2] {Song, 2013 #1304;O'Reilly, 2019 #1307} 。生物光学模型法主要基于水体的固有光学特征来模拟,虽然该方法具有很强的稳定性,但是由于生物光学特征参数很难准确获得,限制了该方法的广泛应用。经验模型纯粹基于叶绿素a实测浓度与卫星传感器各波段光谱反射率之间的回归方程建立,没有考虑光学活性物质的光谱特征。半经验算法基于待测光学活性物质的光谱特征来选择光谱波段用于建模,建模过程也较为简单,主要是通过建立采样点的光谱反射率与地面实测值之间的回归方程。根据光学活性物质的浓度变化幅度采用的回归方法有线性回归,指数回归和多项式回归,最常用的还是线性回归方法,按照使用的光学卫星传感器波段数量,可以分为单波段、双波段、三波段法。
基于叶绿素a在红光和绿光波段有2个主要的吸收峰,又大量反射近红外光,因此,红光和近红外这2个波段常用于植被及浮游植物色素等含有叶绿素的地物遥感反演。最常用的基于红光和近红外的遥感指数有通过波段比值计算得到比值植被指数(RVI) [2],以及波段差值与比值相结合计算得到的归一化植被指数(NDVI) [2] [3]。
由于内陆浑浊水体含有许多影响叶绿素a吸收的物质,例如溶解性有机固体(CDOM),悬浮颗粒物等,在较宽的近红外波段范围内容易导致双波段经验模型估算叶绿素a浓度的稳定性较差。Dall’Olmo等 [4] 提出的三波段算法(TBA),采用了一个叶绿素吸收峰λ1,一个狭窄的叶绿素荧光峰λ2和一个纯水吸收峰λ3组合,λ1和λ2对黄色物质与无机悬浮物的吸收系数近似相等,两者相减可以去除这些物质的影响,三个波段总后向散射系数近似相等,TBA算法能够部分去除非色素物质的吸收信号,在轻度和中度浑浊水体中得到广泛应用。宋开山 [5] 等采用哨兵3卫星数据估算了澳洲,美国和中国的多个湖泊的上千个采样点,取得了时间跨度长达5年的叶绿素a浓度数据,研究认为三波段算法取得了与遗传算法同样的稳定性,其相对均方根误差rRMSE为33.4%。最大叶绿素指数(MCI)算法是一种基线算法,其原理是将λ1与λ3的遥感反射率连线作为基线,然后用λ2处的遥感反射率与该基线的距离来作为自变量与叶绿素a浓度进行回归分析,理论上该算法可以去除水中其它色素物质的干扰,该算法充分考虑了浮游植物固有光学特征,具有一定的稳定性 [6]。然而,MCI算法与NAP和CDOM之间有微弱的相关性,因此用MCI反演叶绿素a会产生不可忽略的误差。叶绿素a浓度的变化也会影响浮游植物色素吸收峰的数值和位置 [7],即随着叶绿素a浓度增加,峰值逐渐增大,并且向长波方向移动,出现明显的“红移”现象 [8],所以针对不同浓度范围的叶绿素a遥感估算,选择不同的波段来运算效果会更好。Matsushita等对东亚地区5个湖泊水体进行遥感估算研究,将湖泊区域按照不同的MCI范围,采用不同的回归模型来估算叶绿素a浓度,组合算法得到的归一化平均绝对误差(NMAE)仅有13.3% [9]。
随着卫星传感器技术的进步,狭窄的红边波段对叶绿素荧光激发非常敏感,同时还可以避免其它色素物质的干扰,非常适合用于叶绿素a的遥感估算。欧洲空间局(ESA)的哨兵2 (Sentinel-2)和我国的高分六号卫星 [10] 都装备了红边波段的传感器,且这2种卫星都具有较高的空间分辨率,其中哨兵2卫星的MSI传感器有4个红边波段。以往的研究往往采用某一个模型算法就固定采用一种波段组合来进行计算,灵活性较差。理论上,MSI传感器4个红边波段都是对叶绿素a非常敏感的,可以分别将不同的红边波段作为上述算法中的叶绿素敏感波段λ2,分别代入模型中计算,优选出误差最小的模型。
有一些采用经验模型估算叶绿素a的研究得到了较好的效果,误差较小,但是这些研究采用的建模数据集和验证数据集均来自同一次采样的数据,无从得知模型的适应性,采用不同日期的星地同步观测数据分别建模和验证模型才能得知模型的普适性。
杨国范等 [11] 研究清河水库的叶绿素a浓度遥感估算,建模和验证采用同一天的星地同步观测数据,其LS-SVM模型平均相对误差为7.21%,线性回归模型平均相对误差为16.43%。杨硕等 [12] 采用实测光谱数据来优选TBM模型中三个波段的位置,建模与验证数据集来自于不同批次的采样,前后相差一个月,结果验证数据的平均相对误差在20%~25%之间。马荣华等采用MODIS影像,基于经验正交函数(EOF)估算太湖叶绿素a浓度,用不同批次的数据集进行建模和验证,得到无偏均方根误差接近80% [13]。前述宋开山等 [5] 的研究采用的TBM模型虽然得到了rRMSE超过30%的结果,但是其采用了时间和地域跨度均很大的数据集来验证,其验证结果可以证明模型具有很强的普适性。
星云湖位于云南省玉溪市江川区,属于高原断层淡水湖,是云南省九大高原湖泊之一,总面积约34 km2。 [14] 20世纪90年代初期,星云湖开始出现藻类水华,营养级别属于中–富营养水平,到了90年代末,藻类水华大面积周期性爆发,营养级别达到富营养化的程度,水质下降到劣V类 [15]。
迄今为止,针对星云湖的叶绿素a估算的算法研究都是采用MODIS卫星建立经验估算模型 [16] [17],由于MODIS卫星对浮游植物敏感的波段空间分辨率为1 km,而整个星云湖只相当于34个像元,因此采用MODIS估算星云湖的叶绿素浓度的结果会非常粗糙。
Sentinel-2 (哨兵2)卫星是欧盟“全球环境与安全监测”计划的第二颗卫星,由两颗卫星组成(A星和B星),携带一枚多光谱成像仪MSI,拥有13个光谱波段,10 m空间分辨率,双星重访周期达到5d,目前全世界在轨的可以公开获取数据的多光谱卫星中,Sentinel-2是空间分辨率和光谱分辨率最高的。采用哨兵2对星云湖进行遥感监测,可以获得34万个像元,空间解析度远比MODIS高 [10]。
本研究采用Sentinel-2卫星进行星地同步观测,以此建立星云湖叶绿素a浓度估算模型,采用MCI、TBM、NDVI、RVI、DVI,5种算法,并将多个叶绿素敏感的红边波段应用在上述模型中,得到多种算法的组合,优选误差最小的算法用于星云湖叶绿素a浓度的遥感估算。本研究建立的星云湖叶绿素a估算模型对实现针对星云湖的高时空分辨率的蓝藻水华遥感监测具有重要的参考意义。
2. 研究方法
2.1. 采样点布设
本次研究对星云湖进行了2次采样,采样时间分别为2018年10月18日和2018年11月18日,采样点的布设如图1所示,采用思拓力S7-D型GPS定位,定位误差在1米以内,10月份有13个采样点,11月份有9个采样点,编号及位置如图1所示。

Figure 1. Sampling point layout and the Sentinel-2A satellite image at pseudo-color
图1. 采样点布设及哨兵2A卫星影像假彩色合成图
2.2. 水样叶绿素a的测定方法
采用热乙醇萃取分光光度法对水样叶绿素a进行测定 [18] [19],即将采集的水样用0.45 um的水系滤膜抽滤后放入冰箱−20℃冷冻24 h。然后取出来将滤膜剪碎放入离心管,用80℃水浴3 min的90%乙醇倒入离心管,避光浸泡4小时,然后3000转离心10 min后再用90%乙醇作为参比液进行比色,先后在665nm和750 nm波长测消光率E665、E750,然后在样品比色皿中加1滴1 mol/L盐酸进行酸化,加盖摇匀,1min后重新在665 nm、750 nm波长测消光率A665、A750,再按公式(1)进行叶绿素a的浓度计算。叶绿素a计算公式如下:
(1)
其中Chl.a是叶绿素的浓度(mg/L),V乙醇是乙醇萃取液定容的体积(ml),V样品是过滤水样的体积(ml)。
2.3. 卫星数据
用于星地同步观测的Sentinel-2A卫星数据通过USGS (http://glovis.usgs.gov/)获取,原始卫星影像为L1C级别,采用官方的预处理工具SNAP和Sen2cor进行大气校正预处理为L2A级别。本研究两次采样的日期和时间分别为2018年10月18日早上10~12点,2018年11月18日早上7~9点(图1)。Sentinel-2A卫星过境星云湖的时间分别为2018年10月19日11点37分,2018年11月18日11点40分。因此,2018年10月18日采样,19日卫星过境的数据属于准同步数据,相差一天。2018年11月18日采样与卫星过境的时间相差在4个小时以内,属于同步数据。
2.4. 波段敏感性分析及叶绿素a估算模型的建立
本研究首先分析MSI各波段与建模数据集叶绿素a浓度的相关关系,采用SPSS计算皮尔逊相关系数,然后选择具有显著相关性,相关系数高的波段,基于比值植被指数(RVI) [2]、差值植被指数(DVI)、归一化差分植被指数(NDVI) [2]、三波段(TBM) [5]、最大叶绿素指数(MCI) [9] 作为自变量,建立相应的线性回归模型。上述算法的表达式如下:
(2)
(3)
(4)
(5)
(6)
上式中,
是光谱反射率,
是近红外波段(叶绿素强烈反射波段),
是红光波段(叶绿素强烈吸收波段),
是750 nm附近的波段。本研究将根据MSI传感器的波段设置,基于各波段反射率与叶绿素浓度之间的相关分析结果,采取不同的波段组合构成自变量,将与叶绿素浓度呈显著正相关的波段作为上述遥感指数的
,与叶绿素浓度呈显著负相关的波段作为
,建立回归模型。模型建立和模型验证均采用缩减主轴回归分析(RMA) [20] 来计算斜率、截距和决定系数R2。
关于建模和验证数据集的选取,由于10月18日采样的7,8,9,10号位点在10月19日的卫星影像里面有云和云下阴影遮盖,所以将其剔除;1,2号位点由于叶绿素a浓度太高,将其作为异常值剔除。最终用于验证的有效位点为编号3,4,5,6,11,12,13这7个点。11月18日采样的4号位点数据异常,引起建模误差较大,将其剔除。最终,有8个2018年11月18日的采样点的数据用于建模,7个同年10月18日采样的数据用于验证。
陈宇炜 [19] 等认为一般富营养化水体的叶绿素a浓度在0.1 mg/L以下,因此建模实测数据以0.1 mg/L为界限,分为高浓度和低浓度样点,分别建立All,High和Low三个数据集建模,其中All数据集采用全部8个采样点建模,High数据集采用高浓度的4个采样点数据建模,Low数据集采用低浓度的4个采样点数据建模。验证数据也分为All,High和Low三个数据集,其中High数据集有4个采样点,Low数据集有3个采样点(见表1)。

Table 1. Monitoring data of chlorophyll-a in Xingyun Lake (mg/L)
表1. 星云湖叶绿素a监测数据(mg/L)
① All dataset; ② Data with a concentration greater than 0.1 mg/L of chlorophyll-a is a high concentration dataset; ③ Data with a concentration lower than 0.1 mg/L of chlorophyll-a is a low concentration dataset.
① 全部数据集;② 叶绿素a浓度大于0.1 mg/L的数据为高浓度数据集;③ 叶绿素a浓度小于0.1 mg/L的数据集为低浓度数据集。
2.5. 误差的估算
本研究采用多个误差评价指标,包括均方根误差(RMSE),相对均方根误差(rRMSE),归一化均方根误差(NRMS),平均归一化偏倚(MNB),归一化平均绝对误差(NMAE) [9]。其中RMSE是指估计值和观测值偏差的平方与观测次数n比值的平方根,能很好地反映出模型的误差,RMSE计算公式为:
(7)
式中,
指估算值,
指的是实测值,N为总的数据量。
相对均方根误差(rRMSE)的计算公式为:
(8)
其中
为实测叶绿素a的浓度平均值。
NRMS表示结果的相对随机不确定性,它代表
的标准差,计算公式为:
(9)
是测量值与估算值之差所占实测值的百分比,计算公式如下:
(10)
MNB表示估算的平均偏差,它代表
的平均值;NMAE表示估算的平均绝对误差,它代表
的绝对值的平均值,计算公式如下:
(11)
(12)
3. 研究结果与讨论
3.1. 叶绿素a浓度测定结果与波段敏感性分析
从现场实测数据来看(表1),10月份监测数据叶绿素a浓度较高,到了11月份,叶绿素a浓度有所降低,从图1呈粉红色的区域分布也可以看出10月19日星云湖南北湖区的蓝藻水华分布比较集中,颜色较深,与实地监测叶绿素浓度的分布情况较为一致。2018年11月19日的叶绿素a浓度高值区域位于星云湖北部湖区,并且颜色要比10月18日的浅,推测11月的富营养化程度没有10月份的严重。
波段敏感性分析表明在使用建模数据中的全部数据集的时候,红光波段(Red)反射率值与实测叶绿素a浓度呈现显著的负相关,而4个红边波段(VRE)和近红外波段(NIR)反射率与实测叶绿素a浓度呈现显著正相关。而高浓度和低浓度数据集与红光波段都是负相关,但是显著性不强。在红边和近红外波段,除了低浓度数据集与B8a红边波段反射率相关系数很高,但是显著性不强以外,其余波段均与相应数据集有显著正相关,见表2。本研究将选择B4作为λ1,B5,B6,B7,B8,B8a波段作为λ2代入上述5个模型中分析。
Table 2. Pearson correlation analysis result
表2. 皮尔逊相关性分析结果
*At level 0.05 (double tail),**At level 0.01 (double tail),the correlation was significant.
*在0.05级别(双尾),**在0.01级别(双尾),相关性显著。
3.2. 模型的构建和验证
本研究采用2018年11月18日的星地同步监测数据进行建模,然后用2018年10月18日采样,第二天卫星观测的准同步数据进行验证。本研究中模型的命名规则如下,例如:MCI1H,其中的MCI为自变量x的算法名称,数字1为编号,H为高浓度数据集,建模分别采用2018年11月18日的A,H,L数据集,验证数据也对应采用同年10月18日的A,H,L数据集。建模和验证结果如表3所示。
建模结果表明,全部数据集建模误差均较大(见表3),误差最小的模型是DVI1A,其rRMSE为32.77%,NMAE为28.44%,MNB为2.94%。高浓度数据集建模误差最小的模型是RVI1H (见表4),其rRMSE和NMAE分别为4.01%和3.95%。表现较好的模型有MCI2H,DVI1H以及所有的NDVI各波段组合,其NMAE均小于10%,rRMSE均小于11%。低浓度数据集表现最好的模型是NDVI1L和DVI2L (见表5),前者rRMSE为25.95%,NMAE为19.32%,MNB为−13.3%,后者的rRMSE为25.71%,NMAE为24.86%,MNB为−17.32%。低浓度数据集MNB最低的模型是TBM1L,为−0.57%。MNB较低的模型模拟值与实测值之间正负偏离抵消较多,比较适用于计算全湖的平均值。
本研究还发现,三个数据集建模最佳的模型选择的λ2除了低浓度数据集的DVI2L选择红边波段B6 (中心波长740 nm)以外,其余都是红边波段B5 (705 nm),与近红外波段B8的842 nm相距较远,与红光波段的中心波长665 nm距离较近。因此,全部数据集建模,用差值植被指数作为自变量,误差最小,如果估算全湖平均值可能得到更低的误差。高浓度数据集则用RVI指数作为自变量最适合,无论是估算单个点的还是全湖平均值,误差均是最低的。此外,高浓度数据集建模,自变量可以选用的指数很多,包括NDVI,DVI,MCI都表现不错。而低浓度数据集建模,可以选用NDVI或者DVI作为自变量,它的单点估算误差最低,如果要做全湖平均值的估算,选用TBM作为自变量是最适合的。
Table 3. Estimation and Verification results of chlorophyll-a model (All dataset)
表3. 叶绿素a遥感估算模型建立和验证结果(全部数据集)
Table 4. Estimation and Verification results of chlorophyll-a model (High dataset)
表4. 叶绿素a遥感估算模型建立和验证结果(高浓度数据集)
Table 5. Estimation and Verification results of chlorophyll-a model (Low dataset)
表5. 叶绿素a遥感估算模型建立和验证结果(低浓度数据集)
3.3. 模型应用
根据前述建模和验证的效果优选出来的模型,在实际应用中,本研究提出基于浓度分区的星云湖叶绿素a遥感估算方法,既首先选用DVI1A模型进行估算,将估算结果按照叶绿素a浓度0.1 mg/L作为阈值,将湖区分为高浓度区域和低浓度区域,然后分别针对高浓度和低浓度区域使用对应的最适用模型再次估算,高浓度湖区采用RVI1H模型,低浓度湖区采用NDVI1L模型进行估算,该方法由ENVI/IDL代码实现,计算机逐像元判断第一次估算的结果,并选择合适的模型进行第二次估算计算,最终得到星云湖叶绿素a浓度模拟结果,如图2和表6所示。
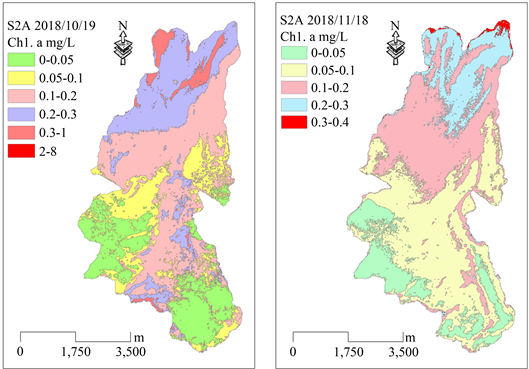
Figure 2. Remote estimation of chlorophyll-a in the Sentinel-2A satellite at the Xingyun Lake
图2. Sentinel-2A卫星估算星云湖叶绿素a分布图
Table 6. The results of remote estimation chlorophyll-a concentration at Xingyun Lake (mg/L)
表6. 星云湖叶绿素a浓度遥感估算结果(mg/L)
两次遥感估算应用结果表明,叶绿素a高浓度分布区域与卫星影像上的藻类水华大量爆发区域一致。其中11月18日的藻类水华主要分布在北部湖区,而10月19日在南北两边都有大量藻类覆盖湖面,但是南边部分区域因为有云,而云团被误识别为低浓度的叶绿素a,范围在0~0.05 mg/L之间,见图2。
基于浓度分区估算星云湖叶绿素a的结果最大值分别达到0.4342 mg/L (11月18日)和7.5112 mg/L (10月19日),估算结果最小值均小于0,计算机自动调整为0,平均值为0.1146 mg/L (11月18日),0.1453 mg/L (10月19日)。2018年10月19日估算的结果大于0.47 mg/L的像元仅有8个,可以认为是异常值,其主要的叶绿素a浓度分布区间可以用平均值加减2倍标准差来表达,其中平均值减去2倍标准差均小于0,可调整为0,平均值加上两倍标准差的结果如表6所示,10月19日的结果为0.3411 mg/L,11月18日估算的结果为0.2467 mg/L,10月份的估算结果明显高于11月份,这与假彩色影像上的主观感受类似。
4. 结论
本研究采用了Sentinel-2A卫星对星云湖的叶绿素a浓度开展遥感估算,通过星地同步观测,建立叶绿素a估算模型。首先,以实测叶绿素a浓度0.1 mg/L为阈值,将建模数据分为三个数据集,分别是高浓度、低浓度和全部数据集;其次,将建模数据与哨兵2A卫星各波段反射率值做相关分析,得到5个显著正相关的红边和近红外波段,根据敏感波段结合DVI,RVI,NDVI,TBM,MCI这5种算法组合形成21种不同波段组合的算法,将其作为自变量x,分别代入3个建模数据集,形成63个回归方程,比较这些回归方程的建模和验证效果。优选出适合不同浓度区间的最佳模型,提出基于浓度分区的方法对星云湖叶绿素a进行遥感估算,该方法可以灵活地针对不同叶绿素a浓度范围的湖区,应用不同的模型进行运算,以此来提高叶绿素a估算精度。本研究得到如下结论:
1) 哨兵2卫星4个红边波段和近红外波段反射率均与叶绿素a浓度呈强烈正相关,叶绿素a浓度高于0.1 mg/L时,采用RVI1H模型,误差最低,其rRMSE和NMAE分别为4.01%和3.95%。叶绿素a浓度低于0.1 mg/L时,采用NDVI1L模型进行估算,rRMSE为25.95%,NMAE为19.32%,MNB为−13.3%,采用TBM1L模型估算时,MNB为−0.57%,说明模拟值与实测值之间正负偏离抵消较多,比较适用于计算全湖的平均值。
2) 基于浓度分区对星云湖叶绿素a进行估算,2018年10月19日估算的叶绿素a浓度大于同年11月18日的估算结果,这个结论与标准假彩色影像的感官结果类似。
3) 低浓度叶绿素a估算模型误差较高浓度模型的误差大,主要原因是本研究基于两次不同时间的星地同步和准同步观测来建模和验证,不同时间的卫星数据,由于大气状况不同,大气校正也并不是完美地消除所有大气的影响,相同的地物在两次不同时相的影像中的反射率值是有细微的差别的,而不同批次的采样和实验也会带来一定的误差,气象因子方面,风的作用会改变浮藻的位置,而低浓度范围的叶绿素a估算精度更容易受到这些误差的影响。在今后的研究当中需要积累更多的星地同步观测数据,同时也要加强对星云湖中其它光学敏感物质的监测研究,排除各种干扰物质的影响,进一步提高叶绿素a的估算精度。
4) 建模的时候得到的回归方程的决定系数高,只能说明建模数据集的线性较好,但是模型是否适用,主要依据还是验证数据的误差。
基金项目
玉溪师范学院大学生创新创业训练计划项目(编号2018A33),云南省地方本科高校(部分)基础研究联合专项项目(编号2017FH001-100,2018FH001-067,2018FD094,2017FD161)和云南省教育科学规划项目(编号GJZ171813)联合资助。
参考文献
NOTES
*通讯作者。