1. 引言
近年来,随着图像数据的大规模增长,人们对图像分类提出了迫切需求,图像分类成为了热门研究领域 [1]。图像分类一般分为对象级分类和细粒度图像分类(Fine-grained image categorization) [2],细粒度图像分类又被称为子类别图像分类(Sub-category recognition) [3],细粒度图像分类是对粗粒度图像中的更小的子类别进行分类,如飞机型号、鸟类品种、服装款式与菜肴样式等。由于同一个粗粒度图像下的各子类图像在几何结构上十分相似,造成细粒度图像类间差异小;而同一个细粒度类别下的图像,从物体的形状、姿态、背景等角度来看都有可能产生极大的差异,致使子类内图像区分难度大。细粒度图像在工业界与学术界都应用广泛,比如在道路交通管理上,可以识别不同车型的数量,计算实时的交通状况;在生物学领域,可以帮助研究人员快速识别不同种类的物种,而不用受太大专业知识的限制。因此细粒度图像分类成为研究热点和难点 [4]。
细粒度图像分类主要分为强监督的分类方法和弱监督的分类方法。强监督细粒度分类方法除了需要图像的类别标签之外,还需要标注框、局部位置等额外的人工标注信息,而这些人工的标注信息往往是需要丰富的专业知识才能够获得,所以这一类方法的代价较高。文献 [5] 提出的Part-based R-CNN,该算法采用R-CNN对图像生成大量的候选区域,然后再对这些候选区域检测,给出每一个局部区域的评分值,根据评分值确定最后的定位检测结果。结合全局特征(物体级别特征)和判别行更强的局部特征进行分类取得了不错的效果,但是需要额外的人工标注开销,并且由于R-CNN算法产生大量的候选区域会大大增加计算复杂度,造成检测速度较慢。文献 [6] 提出的Part-Stacked CNN,它与文献 [5] 类似,也是分为两个步骤,由定位网络与分类网络两部分组成,在定位网络中用到了FCN (Fully Convolutional Network)提高了分类准确率,并且加快了算法的效率,但同样是需要对象与部位级的标签。文献 [7] 提出了一种新颖的局部区域检测模型,在细粒度图像分类中引入了协同分割,提出了一种无需借助局部区域标注信息,只需要标注框就可以完成分割与对齐操作,分类准确度能够达到82%。
由于获取人工标注信息代价大,弱监督图像分类方法越来越受到重视。文献 [8] 提出两级注意力(Two level attention)算法,它关注对象级和局部级两个不同层次的特征。但是利用聚类算法得到的局部区域并不十分准确,所以分类准确率有限。文献 [9] 提出基于双线性卷积神经网络(Bilinear Convolution Neural Networks, B-CNN)的弱监督分类模型,它由两路VGGNet构成。该模型将两个网络提取的卷积特征进行双线性操作,以提高图像特征表达能力,实现了一个端到端训练的弱监督分类网络。但是该模型利用VGGNet作为特征提取网络,没有能充分关注物体判别性区域对分类准确率的影响。
综合以上,影响细粒度图像分类准确率的两个主要因素,一是对图像局部显著性区域的关注,二是对局部区域特征的提取和表达。本文在B-CNN的基础上,提出一种基于Grad-CAM [10] 与B-CNN的细粒度图像分类方法,该方法首先利用Grad-CAM模型提高对象级显著性区域检测结果,聚焦判别性区域,去除无关区域对分类结果的影响,并且改用更加有效的特征提取函数,采用B-CNN模型对判别性区域进行特征提取与分类,从而提高细粒度图像的分类准确率。这种方法不需要标注框和局部位置等人工标记信息,也能够减少背景区域的干扰,在理论上将讲这种方法是一种有效的细粒度图像分类方法。
2. 相关理论
2.1. 类别激活映射
2.1.1. CAM
具有区别性的显著性区域特征是分类的关键。类别激活映射(Class Activation Mapping, CAM) [11] 提供了一种解释图像分类结果的方法,它采用全局池化层(global average pooling, GAP),解决全连接层参数过多、网络不易训练和容易过拟合等问题。该方法以HeatMap来映射图像中与该类别的最相近的即显著性区域,使得模型有更强的解释性。是一种寻找图像中显著性区域的更好的方法。CAM模型如图1所示。
CAM方法用GAP层替换全连接层来接收最后一层卷积的结果,输出每一个特征图在每一个通道的平均值,接着是全连接层接收这些平均值生成最后的预测值。选择最终全连接层节点的权重作为最后一层卷积层的特征图的权值,并对特征图像按通道加权形成最后的类别激活映射图。
2.1.2. Grad-CAM
CAM能够反映特定类别的显著性区域,实现分类解释。但是CAM需要改变原模型结构,并且重新训练,这大大限制了CAM的应用场景。Grad-CAM与CAM的基本思路是一样,都是通过得到每一个通道特征图的权重,最后加权求和。但是,与CAM不同的是Grad-CAM不需要改变原模型结构,只需要通过梯度的全局平均求取通道映射为类别的权重,这样可以保留卷积之后的全连接层,并且经过数学推导证明Grad-CAM与CAM得到的通道特征图的权重是一致的。Grad-CAM模型如图2所示。
参考图1、图2模型,设
为最后一个卷积层输出的特征图中的第k个通道的
位置上的激活值,
为通道k的特征图,则:
(1)
对于某一个特定类别标签c,
表示的是softmax层的输入,则:
(2)
其中
是通道k映射为类别c的权重。所以根据式(1)、式(2):则:
(3)
用
表示类别c对应的激活映射,
表示激活映射图
位置上的激活值,则:
(4)
第k个通道对应的类别c的权重值
为:
(5)
其中Z为特征图中像素的个数,
是对应类别c的分数(在代码中一般用logits表示,是输入softmax层之前的值),
表示第k个特征图中,
位置处的像素值。
类别映射图反映了原图中各个显著性区域与特定分类分别之间的相关性。因此可以利用Grad-CAM来进行位置定位,用于检测相应物体在原图中的区域,并获取HeatMap中的最大联通区域的边界框,将边界框作为定位框。
2.2. B-CNN
双线性卷积神经网络(B-CNN)是一个典型的弱监督的细粒度图像分类算法,不需要任何的人工标记就已经在鸟、飞机、狗等数据集上达到了较好的准确率,其模型如图3所示:
一个双线性卷积神经网络模型可由一个四元组
表示,
。其中
、
分别表示两个特征提取函数,P是池化函数,C是分类函数。在每一个位置对两个网络提取到的特征做外积,组合成双线性特征(bilinear feature),如式(6)所示:
(6)
其中,l表示每一个局部位置,I表示原图。
对所有位置得到的双线性特征进行求和池化,作为原图像的特征:
(7)
2.3. 残差模型
经典的双线性卷积神经网络是由两个VGG分支网络组成的,Stream A进行图像中的目标定位,检测局部区域;Stream B进行定位后区域的特征提取。两个网络相互协调工作,最终完成对图像的分类。通常情况下,深度卷积神经网络的层数较少时,可以增加深度来获得更好的特征提取效果;一旦网络层数过高,会使得网络产生大量的参数,也难以使得网络收敛。VGG对于细粒度图像分类的有一定的局限性,对特征的提取和表达不能更加精确。文献 [12] 表明,随着网络层数的增加,网络发生了退化(degradation)的现象。因此,在文献 [12] 中何凯明等人提出了深度残差网络(ResNet)。其残差模块结构如图4所示。
其中,X是第一层残差模块的输入,
是经过第一层线性变化并激活后的输出。在第二层线性变化之后激活之前,
加入了第一层输入值X,然后激活输出。残差网络的提出解决了深层网络梯度消失的问题,提升了网络的分类准确度,相比于双线性卷积网络所使用的VGG网络,ResNet有更深的网络结构,也能更加准确识别图片中的细节特征,从而实现精细化识别。
3. 本文模型结构及算法流程
结合Grad-CAM与B-CNN模型,本文采用的细粒度图像分类模型如图5所示。
本模型分为两个模块,原图经过Grad-CAM检测之后,原图中更精细区域被定位,在Grad-CAM中依旧采用VGG网络来实现检测;显著性区域检测出来为提取特征做准备,B-CNN双线性模型中的VGG网络利用ResNet50代替,更加高层的双线性特征有利于最后的分类任务。
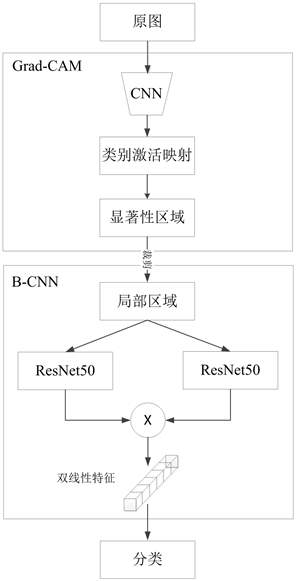
Figure 5. Fine-grained image classification model based on Grad-CAM and B-CNN
图5. 基于Grad-CAM和B-CNN的细粒度图像分类模型
算法描述如下:
1) 输入原图,对原图进行统一尺度缩放为
的图像I;
2) 将图像I进行卷积,并计算最后一层特征图
,
表示A的空间维度,d表示通道数量。A的第k个通道对应的c类别的权重值为
,分别表示每一个通道的重要程度,则:
(8)
表示通道k中位置
的像素值,用梯度
的全局平均来计算每一个通道的权重值
。
3) 求得所有特征图的权重之后对其加权求和并ReLU激活;
(9)
表示通道k的卷积特征图,
表示类别c判别定位图,用ReLU线性组合所有的加权特征图,输出突出目标类别的热力图;
4) 得到图像I的热力图
,设定一个像素阈值
,如果热力图中
,则令
;如果
,则令
,通过热力图得到掩码图M;
5) 显著图 =
,通过点乘去掉不显著区域,得到显著图;
6)根据显著图中像素值为255(即白色部分)区域,用矩形框框出显著图区域并从原图中裁剪出显著图部分的图像
,并对
的尺寸归一化;
7) 双路残差网络把
映射成同一维度的特征,两个特征通过一个双线性池化操作P汇聚,得到一维的双线性特征B;
8) 对所有位置的双线性组合特征B求和;
9) 训练网络,完成分类。
在算法开始前,将原图缩放到统一的尺寸。然后利用Grad-CAM对图像的显著性区域进行定位,生成显著性区域的热图。根据热图得到掩码图,并计算掩码图中的最大联通区域,该连通区域就是目标物体所在的位置。从原图中相应位置裁剪出显著性区域,并缩放图像尺寸,并输入双线性残差卷积神经网络以完成分类
4. 实验与分析
在算法开始前,将原图缩放到统一的尺寸。然后利用Grad-CAM对图像的显著性区域进行定位,生成显著性区域的热图。根据热图得到掩码图,并计算掩码图中的最大联通区域,该连通区域就是目标物体所在的位置。从原图中相应位置裁剪出显著性区域,并缩放图像尺寸,并输入双线性残差卷积神经网络以完成分类。
4.1. 实验设计
论文使用开源深度学习框架Keras作为实验平台,基于一台英伟达GTX1070显卡和16G DDR4内存的ubuntu16.04计算机系统上采用Python编程实现。
实验采用加州理工大学鸟类数据集CUB-200-2011 [13]、斯坦福大学狗类数据集Stanford Dogs [14] 和斯坦福大学汽车数据集Stanford Cars [15] 等三个经典的细粒度图像分类数据集。
CUB-200-2011鸟类数据集是在细粒度图像分类领域使用最为广泛的一个数据集。该数据集包括11,788张鸟类图片,一共分为200个类别。其中5994张图片用于训练模型,5794张图片用于测试模型。每一张图片都有详细的人工标注标签,物体标注框和局部位置标注点。Stanford Dogs狗类数据集总共包括20,580张图片,其中12,000张图片用于训练模型,8058张图片用于测试模型,一共分为120个类别。Stanford Cars汽车数据集总共包括16185张图片,其中8144张图片用于训练模型,8041张图片用于测试模型,一共分为196个类别。
因为细粒度图像分类的3个数据集都比较小,用于训练和测试的样本数较少,如果直接在这3个数据集上训练可能会导致网络无法收敛,因此,利用在ImageNet数据集上预训练好的参数对网络进行初始化,然后在三个细粒度图像数据集上对模型进行微调(fine-tuning),这样会有更好的训练效果。
输入图像统一缩放成448 * 448的三通道的彩色图像,裁剪出来的显著性区域统一缩放为224 * 224 * 3,学习率设置为0.005,训练批次为32,迭代次数为100,000次,使用随机梯度下降优化器来训练和优化模型。
4.2. 性能指标
对于以上所述的三个经典数据集,为了直观体现算法的性能与效果,使用分类准确度Accuracy作为评价指标。
(10)
其中,N表示总共用于测试样本的数量
,表示测试样本中正确预测的数量。用准确度Accuracy可以直观的反应算法的分类性能。
4.3. 实验结果
通过实验,计算出原图的掩码图与显著性图如图6所示。

Figure 6. Salient regions detection of Fine-grained images. (a) Original image; (b) HeatMap; (c) Salient region
图6. 细粒度图像显著性区域检测。(a) 原图;(b) 热图;(c) 显著性区域
将本文提出的基于Grad-CAM与B-CNN的细粒度分类方法与PDFR [16]、Two-level [17]、Low-rank [18]、Constellations [19]、DVAN [20]、B-CNN等主流细粒度分类算法对比,在三个数据集上的实验结果如表1所示。
实验结果表明本文方法在CUB-200-2011数据集上的分类效果比其他的方法略有提高,比B-CNN模型提高了0.6%;在Stanford Dogs数据集上,本文算法优于B-CNN、Low-Rank、Two-Level等弱监督分类模型87.1%;与原模型B-CNN相比较,在3个数据集上的分类效果都有所提高。

Table 1. Comparison of experimental result
表1. 实验结果对比
5. 结束语
本文在双线性卷积神经网络的基础上提出改进的基于梯度类别激活映射与双线性残差网络的细粒度分类方法。首先基于Grad-CAM提取图像中的显著性区域,将显著性区域从原图中裁剪出来并预处理,用两个ResNet50网络作为特征提取函数,提取显著性区域更加细致的特征,然后通过结合全局与局部的特征信息进行分类。在3个经典数据集上实验结果表明,在不使用物体包围框以及局部位置标注点的情况下,本文方法可以提升双线性卷积神经网络的分类性能,能够优于其它分类方法对细粒度图像进行有效分类。
基金项目
本文得到广东省自然科学基金项目(No.2019A1515011056,2018A030313868)的资助。