1. 引言
近年来,全世界对大数据应用的关注日益提高,不断在数据中挖掘其内在潜力和价值。大数据在集成和组合数据上具有优势,可帮助形成高效的智能调度能力,优化公共交通信息资源的配置,同时辅助制定出较好的统筹协调方案。
交通信息化的核心技术逐渐转向智能交通。采用信息化的技术方法,让政府以及交通管理部门能及时了解整体的交通状况,根据实际数据做出准确的客流分析并提出切实可效的策略,解决现有的交通问题。
手机信令数据是一种新型的大数据源,与其他类型的数据相比,其具有实时性、完整性、出行时空全覆盖性等其他数据源所不拥有的优势,在各类规划中尤其是交通大数据分析中具有独特的应用优势。另外,作为人们生活中必不可少的交流工具,手机通常一直在工作,故数据记录时间长。而且生活中手机的普及率较高,几乎所有城市居民都可以通过移动手机进行监控,而无需额外的成本 [1]。
国外方面,文献 [2] 提出能够识别用户驻留地点的方法,将测试用户作为实验样本研究用户的出行特征和规律。文献 [3] 中作者开发一种基于手机数据的智能工具,帮助交通管理机构探索市民的移动规律和优化公共交通。
国内方面,吴乃星 [1] 等将手机信令数据作为数据集,分析出行需求的空间结构、连续空间分布特征和人口区域运动规律,将分析结果以OD图、密度图和流线图的形式可视化。杨飞 [4] 通过手机定位平面坐标对用户进行追踪,获取居民运动状态,分析活动位置的集中特征,来得到用户的出行OD数据。
本文以手机信令数据作为数据集,搭建大数据伪分布式环境,将数据清洗后,根据设计的算法处理得到用户分布密度数据、出行轨迹数据、出行方式数据,之后开发数据可视化后台系统将数据直观地呈现给系统的用户。
2. 系统整体架构
以用户手机信令数据作为待处理数据,数据的处理主要分为数据输入、数据清洗、数据缓冲、数据处理、数据存储和数据可视化六步。首先在Linux系统下配置数据处理每个步骤所需的环境,然后设计数据处理的数据流向,具体的设计如图1数据处理过程设计图所示。
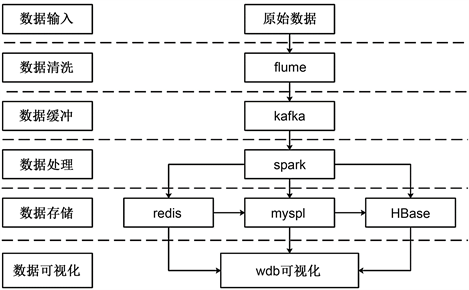
Figure 1. Data processing process design diagram
图1. 数据处理过程设计图
数据清洗:将原始数据输入到flume进行数据清洗,得到所需的数据并存入kafka中准备处理。
数据处理:spark从kafka中读取数据并对其进行处理。
数据存储:将处理后的不同类型的数据分别输出到实时性要求不同的redis、mysql和HBase中存储。
数据可视化:创建springboot架构的web后台,分别从redis、mysql和HBase中读取需要的数据传到前端页面进行展示。
3. 系统算法设计
3.1. 数据说明
本文采用手机信令数据。数据内容包含原始数据.csv、基站经纬度数据.csv和出行方式静态数据.csv三份数据。数据的详细内容如表1所示。
3.2. 数据清洗
数据清洗使用Flume的Taildir Source从原始数据.csv文件读取数据并使用自定义的flume Interceptor对其进行清洗,数据清洗操作分为如下三类:
1) 筛选出需要的数据项并去除数据项缺失的数据;
2) 数据不合法与日期不是2018年10月03日的数据;
3) 将原始数据中的时间戳转换为日期格式。
设计了三个步骤的判断:
Step1:判断数据项是否完整,用于筛除数据项有缺失的数据;
Step2:判断数据项是否合法,刷去数据项格式不正确的不合法数据;
Step3:最后判断是否为指定日期的数据,得到目标数据存入Kafka。
3.3. 数据处理算法设计
数据处理判断对象均为坐标,故以k,v键值对的形式存储[基站位置,基站id],对从kafka获取的数据中的基站位置进行匹配并替换为基站坐标。数据处理的数据流均为从kafka中获取,在Spark中处理,之后实时数据存入Redis,离线部分数据存入Mysql。具体的处理步骤和算法设计如下所示:
1) 热力图数据处理
以基站为单位,统计某一时间点每个基站内包含的人数 [5],同时结合人口的移动情况。具体的算法设计如图2所示。经过处理后,得到[坐标,权值]形式的数据。

Figure 2. Heat map data processing flowchart
图2. 热力图数据处理流程图
如图所示,将数据从Kafka中取出后保存用户的数据,然后判断id是否匹配、坐标是否匹配和基站是否已被记录。根据不同的判断结果对于权值和坐标进行不同的操作。
2) OD图数据处理
以基站对为单位,统计出某一时段从一个基站到另一个基站的人数 [6],可实时刷新也可查看历史记录。通过对从Kafka中取出的数据判断其id、坐标和时间,来确定是否对地区迁徙权值进行+1操作。设计具体步骤如下:
Step1:获取kafka中缓存数据,存入Map[id,坐标,时间]格式数据;
Step2:匹配到与当前id相同的Map;
Step3:获取该Map的坐标和时间,判断用户上个坐标和当前坐标是否相同;
Step4:判断上一个坐标—>当前坐标的迁徙是否被记录。被记录过,该地区迁徙权值+1,否则存入该地区迁徙,权值为1。
3) 驻留图数据处理
根据同一用户的坐标变化,判定驻留情况,在一段时间内,坐标无变化则判定为驻留。以基站为单位,统计每一个基站的驻留次数,驻留人数和驻留时间。
算法核心思想:判断同一用户的坐标是否相同,如果相同则为驻留,将该驻留点的权值加1;否则判定为非驻留点,如果上条数据被记录过驻留且权值不为0,则该坐标的权值减1。
4) 出行方式分析数据处理
出行分析是将数据的分析标签化,分析每个用户的出行方式。该分析总体分为轨迹处理和出行方式标签化两个部分,对数据经过判断去除不符合的数据后,计算每次出行的特征值 [7],最终实现出行方式的分析,处理流程图如图3所示。

Figure 3. Flow chart of travel analysis processing
图3. 出行分析处理流程图
a) 轨迹处理
轨迹处理是先对数据清洗后的数据进行去重,去乒乓切换,去数据漂移 [8] 等处理并将用户一条轨迹通过关键点拆分为多条出行路径,其中关键点包括驻留点与换乘点。
I) 去除重复的数据
用户在同一个基站范围内停留时,可能会产生多条坐标相同而时间不同的数据。对于此类数据选取最开始和最后的一条数据进行保留,中间数据可以舍弃。去除的数据示例如图4所示。
II) 去数据漂移
对于记录A、B、C,A到B的距离 << A到B加B到C的距离,并且A到B与B到C的时间较短,可判定为发生了数据漂移,B点为数据漂移点,将其去掉,只保留记录A,C。如示例图5所示。

Figure 4. Example diagram of removing duplicate data
图4. 去除重复的数据示例图
III) 去乒乓切换
乒乓切换分为高速乒乓切换和低速乒乓切换。高速乒乓切换一般在用户基站覆盖范围重合区移动时发生。低速乒乓切换一般在用户的活动区域同时在多个基站的覆盖范围内时发生。对于乒乓切换保留第一条与最后一条数据。如图6所示。

Figure 6. Example diagram of switching to ping-pong
图6. 去乒乓切换示例图
b) 出行方式标签化
通过计算每一条出行记录特征值,再结合静态交通数据和交通方式的划分对每种交通方式的可能性进行分析,得出每种交通方式的权值,选取权值最大的方式为此处出行的出行方式 [9]。实现流程如图7所示。

Figure 7. Flow chart for implementing travel labeling
图7. 出行标签化实现流程图
出行特征值:确定出行记录的95%位速度、中位速度、平均速度、低速度率作为出行的特征值。
交通方式的划分:根据每种交通工具的速度,将交通方式按照速度划分为步行、自行车、摩托车、公交、汽车、地铁、火车。
静态交通数据:使用爬取到的地铁数据与公交数据增加模型的准确度。
出行方式:根据出行特征值,结合交通方式的划分和静态交通数据对每种交通方式的权值进行计算,取权值最大的为本次出行的出行方式。设每种交通方式的权值为
,则静态交通数据的权值为
4. 系统实现
根据设计的数据处理流程处理数据并存入mysql和redis中,搭建SpringBoot后台框架,引入高德地图API,实现的效果如图8~12所示。

Figure 9. System Resident Map Interface
图9. 系统驻留图界面

Figure 12. Travel mode-population visualization
图12. 出行方式—人口可视化
5. 结语
对已给出的手机信令数据,经过数据清洗,数据处理,数据存储,数据可视化等操作最终得到有价值的数据,并将数据存储。编写实现Web网站端,提供实时和离线两种方式,以各种图表和地图的形式将数据呈现给用户。该系统挖掘出了数据中潜藏的价值,能够很好地对城市的智能化交通带来一定的贡献。
NOTES
*通讯作者。