1. 引言
粗糙集是1982年英国数学家Pawlak提出的理论 [1],该理论是一种处理不确定的,不精确信息的数学工具。自提出以来,得到了很多学者的关注和研究,并已应用到了决策分析模式识别数据挖掘等领域 [2] [3] [4]。
经典粗糙集模型是一种可以被要求利用信息是完全性的一种模型,却忽略了随机,文献 [5] 提出了多粒度概率粗糙集模型集,解决了经典的粗糙集中下近似过于严格和上近似过于宽松的问题。但是,却没有考虑到信息系统缺失属性值的情况。文献 [6],在不完备的决策信息系统中定义了粒度的属性缺失,粒度组合重要度。文献 [7],根据乐观和悲观的角度,对贝叶斯决策进行了讨论并对决策信息系统进行了约简的讨论。文献 [8],对经典的不完备信息系统进行了讨论和约简。文献 [9],对多粒度粗糙集的粒度约简算法进行了讨论。文献 [10] [11],分别从容差关系模型拓展领域等角度对不完备信息系统进行了研究。
本文是基于不完备信息系统进行的讨论,主要讨论了概率粗糙集的优劣关系及规则提取。在本文当中,第二部分介绍了相关概念;第三部分我们基于相似关系,对多粒度概率粗糙集进行了讨论;第四部分基于劣势关系和优势关系分别从乐观和悲观的角度对不完备的多粒度概率粗糙集进行了讨论,并给出了随
的变化规律与精度变化的规律。第五部分,讨论了基于优劣关系随参数
变化的概率粗糙集的规则提取。
2. 相关概念
定义1 [5]:设
为一个决策信息系统,其中U为论域;
为有限属性集合;C为条件属性集合,D为决策属性集合
,
为属性
的值域;
是一个信息函数,
。在缺失部分条件属性值的状况下(用*表示),被称为不完备的决策信息系统;否则,S是一个完备决策信息系统。
定义2 [5]:设
为一个不完备决策信息系统,
是C的m个属性的子集族。
,X关于A的
(1) 乐观多粒度上(下)近似定义:
(2) 悲观多粒度下(上)近似分别定义:
定义3 [8]:设
是一个不完备信息系统,称
为其相似关系,如果满足
相似关系
是自反而且满足对称性,但通常不满足传递性。记作
,则
被称为x关于
的相似类;记
是构成U的一个划分。
定义4 [8]:设
是不完备信息系统
(1) 称
为优势关系,当满足
时,可以利用优势类关系归类:
,其中:
,
;
表示在属性A上优于x的优势类,
表示在属性A上劣于x的劣势类。
(2) 称
为劣势关系,当满足
时,可以利用劣势类关系归类:
,其中:
,
;
表示在属性A上优于x的优势类,
表示在属性A上劣于x的劣势类。
注:(1) 下文中的所有讨论基于不完备信息系统进行讨论,小标题中不在体现。
(2) 根据定义2中悲观多粒度的上下近似,在下面的文章中,可类似于乐观多粒度概率粗糙集的上下近似的讨论方式得出其相关定理和性质,本文不再给出。
3. 基于相似关系的多粒度概率粗糙集模型
定义5:设
为一个不完备多粒度信息系统,
,
,
,
则X在相似关系
上依参数
的乐观(悲观)多粒度概率粗糙集下近似
和上近似
分别定义:
通过定义5,可以得到在不完备系统中,乐观多粒度概率粗糙集的边界域集合:
二元组
称作是X基于相似关系
关于粒度
的乐观多粒度概率粗糙集。
定理3.1:设
为一个不完备的多粒度信息系统,
,
,
,
则
证明:
定义6:设
为一个不完备的多粒度信息统,
,
,
,
,X在相似关系
上依参数
的乐观(悲观)多粒度概率粗糙集近似精度
分别定义为:
;
。
例1:S是一个不完备的多粒度信息系统,(如表1所示),
,
,
,
,
是8个对象,
是四个条件属性,D是决策性,
是粒度空间。

Table 1. Incomplete information system S
表1. 不完备信息系统S
根据定义4基于相似关系,当
变小,
变大时,求得在不完备多粒度信息系统中概率粗糙集在不同决策类型的乐观(悲观)多粒度上(下)近似集(如表2所示):
Table 2. Optimistic (pessimistic) upper and lower approximate sets of incomplete multi-granularity probability rough sets based on similarity relations
表2. 基于相似关系的不完备多粒度概率粗糙集的乐观(悲观)上下近似集
得到近似精度为:
通过例1,可以发现在不完备信息系统中,基于相似关系对缺省的值进行分类;会出现在乐观的情况下所有的上(下)近似和精度都为空的情况,并且在完备的信息系统中近似精度所满足的性质此时也都不在满足。由此,我们在接下来的文章中基于优劣关系进行讨论。
4. 基于优势(劣势)关系的多粒度概粗糙集模型
定义7:设
为一个不完备的多粒度信息系统,
,
,
,则
(1) 在优势关系
上,依参数
的乐观(悲观)多粒度概率粗糙集下近似
和上近似
分别定义:
通过定义,可以得到在不完备系统中,乐观(悲观)多粒度概率粗糙集的边界域集合如下:
二元组
是一个被称作是X基于优势关系
关于粒度
的乐
观多粒度概率粗糙集。
(2) 在劣势关系
上,依参数
的乐观(悲观)多粒度概率粗糙集下近似
和上近似
分别定义:
通过定义,可以得到,在不完备系统中,乐观多粒度概率粗糙集的边界域集合:
二元组
称作是X基于劣势关系关于粒度
的乐观多粒度概率粗糙集。
定理4.1:设
为一个不完备的多粒度信息系统,
,
,
,则上近似可以表示为
证明:
(其余等式证明可类似定理3.1可证)。
注:(1) 同理可得,悲观的上近似有如下性质
。
(2) 同理基于劣势关系也可得出如上定理。
定义8:设
为不完备多粒度信息系统
,
,
,因此X在优势关系
(劣势关系
)上依参数
的乐观(悲观)多粒度概率粗糙集近似精度
分别定义为:
;
。
例2 不完备多粒度信息系统为例1中给出的(如表1)我们基于优势关系进行讨论,得到在优势关系下
的归类:
根据定义7,当
变小,
变大时,基于优势关系求得在不完备多粒度信息系统中概率粗糙集在不同决策类的乐观(悲观)多粒度上(下)近似集(如表3所示):
Table 3. Optimistic (pessimistic) upper and lower approximations of incomplete multi-granularity probability rough sets under dominance relations
表3. 优势关系下的不完备多粒度概率粗糙集的乐观(悲观)上下近似
得到近似精度为:
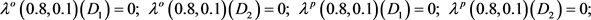

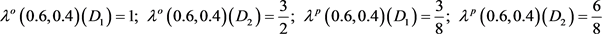
根据定义7,当 变小,
变小,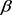 变大时,基于劣势关系求得在不完备多粒度信息系统中概率粗糙集在不同决策类的乐观(悲观)多粒度上(下)近似集(如表4所示):
变大时,基于劣势关系求得在不完备多粒度信息系统中概率粗糙集在不同决策类的乐观(悲观)多粒度上(下)近似集(如表4所示):
Table 4. Optimistic (pessimistic) upper and lower approximations of incomplete multi-granularity probability rough sets under the inferiority relationship
表4. 劣势关系下的不完备多粒度概率粗糙集的乐观(悲观)上下近似
基于劣势关系得到近似精度为:

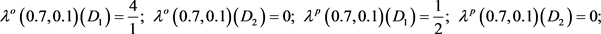
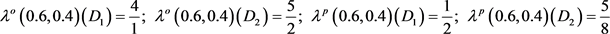
定理4.2:设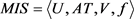 为不完备多粒度信息系统,
为不完备多粒度信息系统, ,
, ,
,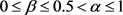 ,因此基于优势关系和劣势关系的
,因此基于优势关系和劣势关系的 的近似精度应有如下性质:
的近似精度应有如下性质:
(1) 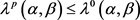
(2) 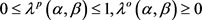
注:在相似关系中上述性质一般不成立。
通过例1和例2的比较,可以发现在不完备系统中,基于优劣关系对缺省的值进行分类;这样可以避免依据相似关系分类时造成的信息偏差,和在乐观情况下所有的上(下)近似和精度都为空的情况。根据乐观和悲观,可以在不完备的多粒度概率粗糙集中通过调整 值,得到不同的近似精度,并有如下变化规律:
值,得到不同的近似精度,并有如下变化规律:
(1) 在相同的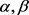 值下,基于劣势关系得到了更大的近似精度。
值下,基于劣势关系得到了更大的近似精度。
(2) 当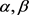 值同时变小时,上下近似会同时变增大;
值同时变小时,上下近似会同时变增大;
(3) 当 值同时变时,上下近似会同时变递减。
值同时变时,上下近似会同时变递减。
(4) 当 逐渐减小,
逐渐减小, 逐渐增大时,可以得到较大的下近似和较小的上近似,并且相应的不完备多粒度概率粗糙集的近似精度会增大。相反,则会减小。
逐渐增大时,可以得到较大的下近似和较小的上近似,并且相应的不完备多粒度概率粗糙集的近似精度会增大。相反,则会减小。
5. 基于优劣势关系的多粒度概率粗糙集的决策规则
定义9 [8]: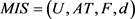 是一个不完备多粒度决策信息系统,d是决策属性,d把U分类为有序的:
是一个不完备多粒度决策信息系统,d是决策属性,d把U分类为有序的: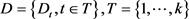 ,对于任意
,对于任意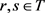 ,当
,当 时,
时, 中的对象优于
中的对象优于 中的对象,于是这些有序的决策类用向上联合与向下联合近似来表示:
中的对象,于是这些有序的决策类用向上联合与向下联合近似来表示: ,当
,当 时,表示x至于属于
时,表示x至于属于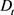 决策类;而当
决策类;而当 时,表示x至多属于
时,表示x至多属于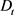 决策类。
决策类。
定义10:设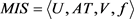 为一个不完备多粒度信统,
为一个不完备多粒度信统,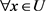 ,
,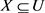 ,
,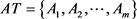 ,
, ,
,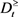 和
和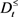 在优势关系
在优势关系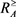 上的下近似与上近似表示:
上的下近似与上近似表示:
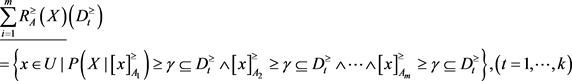
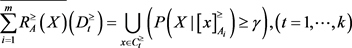
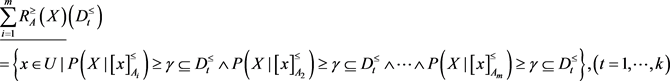

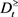 和
和 的边界为:
的边界为:
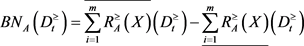

则可能的决策规则有:
(1) 确定的 规则:若
规则:若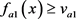 与
与 与
与 与
与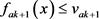 与
与 ,则
,则 。
。
(2) 可能的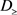 规则:若
规则:若 与
与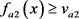 与
与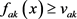 与
与 与
与 ,则x可能属于
,则x可能属于 。
。
(3) 确定的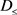 规则:若
规则:若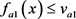 与
与 与
与 与
与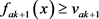 与
与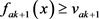 ,则
,则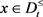 。
。
(4) 可能的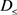 规则:若
规则:若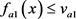 与
与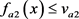 与
与 与
与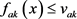 与
与 ,则x可能属于
,则x可能属于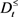 。
。
例3:s是一个不完备的多粒度决策信息系统(如下表5所示),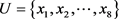 ,
, 是8个对象,
是8个对象, 是四个条件属性,是决策属性,
是四个条件属性,是决策属性, 是粒度间,
是粒度间,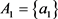 ,
, ,
, 。
。
Table 5. Incomplete information system
表5. 不完备信息系统
从表中得到决策类 ,其中:
,其中: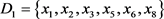 ,
,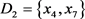 。
。
由于只有两个决策类,得到向下联合 与向上联合
与向上联合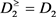 ,于是当
,于是当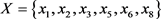 ,取
,取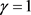 时,得到下近似,上近似和边界为
时,得到下近似,上近似和边界为
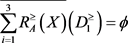 ,
,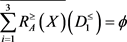
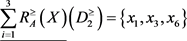 ,
,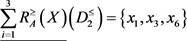
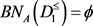 ,
,
取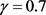 时,得到下近似,上近似和边界为
时,得到下近似,上近似和边界为
 ,
,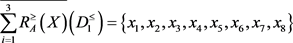
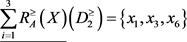 ,
,
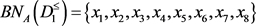 ,
,
因此,可以将不完备信息中的多粒度层整体考虑来得到规则:
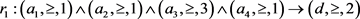 ,支持这个决策规则的对象有
,支持这个决策规则的对象有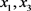 ;
;
 ,支持这个决策规则的对象有
,支持这个决策规则的对象有 ;
;
 ,支持这个决策规则的对象有
,支持这个决策规则的对象有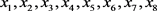 ;
;
 ,支持这个决策规则的对象有
,支持这个决策规则的对象有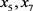 ;
;
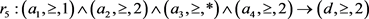 ,支持这个决策规则的对象有
,支持这个决策规则的对象有 ;
;
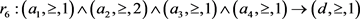 ,支持这个决策规则的对象有
,支持这个决策规则的对象有 。
。
当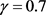 ,规则
,规则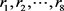 全部可能是确定的
全部可能是确定的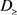 决策规则,也有可能是
决策规则,也有可能是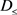 决策规则。
决策规则。
当 时,规则
时,规则 时确定的
时确定的 决策规则,
决策规则,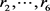 ,可能是
,可能是 决策规则,但是也有可能是确定的
决策规则,但是也有可能是确定的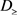 决策规则。
决策规则。
由此,可以发现当 值越大,则得到的确定性规则越多,反之会越少。这样我们就可以根据决策者的不同要求来获取更为有用的规则。
值越大,则得到的确定性规则越多,反之会越少。这样我们就可以根据决策者的不同要求来获取更为有用的规则。
6. 结论及展望
本文是基于不完备信息系统进行的研究。在本文开始,介绍了不完备系统中的多粒度粗糙集理论和乐观粗糙集近似和悲观多粒度粗糙集近似的定义;第三部分给出了不完备信息系统中基于相似关系的多粒度概率粗糙集的相关定义及性质,讨论了其上下近似和近似精度。第四部分基于优势关系劣势关系分别讨论了多粒度概率粗糙集的上下近似和近似精度,并做了对比,通过调整参数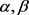 的值来得到更高的近似精度,讨论了近似精度满足的性质和变化规律。最后在第五部分提出了不完备信息系统中的多粒度概率粗糙集基于优劣关系的规则提取。
的值来得到更高的近似精度,讨论了近似精度满足的性质和变化规律。最后在第五部分提出了不完备信息系统中的多粒度概率粗糙集基于优劣关系的规则提取。
每个相关的定义都给出了具体实例验证,进一步探讨概率粗糙集模型基于优劣关系的规则提取的有效性,接下来的工作将针对这些规则的给出,尝试给出更为高效的约简及其规则提取的算法。
基金项目
青海省自然科学基金(2018-ZJ-911);青海民族大学科研创新团队专项经费支助。
NOTES
*通讯作者。