1. 引言
近年来,得益于互联网的飞速发展和网络上海量的数据,人工智能被广泛应用于人类的生活中,如智能客服、语音助手、机器自动翻译等。简答题、叙述题等主观题机器自动评分研究始于上世纪60年代。传统的研究主要采用统计学方法,如:Ellis Page [1] 提出的PEG (Project Essay Grade)方法,评分结合考虑文章平均长度、分号数量和词语稀缺度等因素;高思丹等人 [2] 提出的评分方法先对关键词进行匹配,然后计算语句相似度,最后计算分数;倪应华 [3] 提出的评分方法除了对关键词进行匹配,还引入了模糊数学中的单向贴近度,计算考生答题和参考答案之间的贴近程度。传统的统计学方法,仅考虑答案文本长度、关键词数量等浅层因素,没有考虑到语义等深层复杂因素对评分的影响。
随着计算机性能的提高和自然语言处理技术的发展,基于统计的主观题机器自动评分方法渐渐被基于信息检索和自然语言处理技术的主观题机器自动评分方法取代,并且准确率有了较大地提高。如:David Callear等人 [4] 提出了ATM (Automated Text Marker)方法,该方法引入了近义词词典,初步考虑到语义因素;王逸凡等人 [5] 先用扩展的命名实体识别方法提取关键词,然后采用同义词词林进行相似度计算,最后得出分数;罗海蛟等人 [6] 将结合专家知识的LDA模型引入自动评分中;周洲等人 [7] 使用TF-IDF和LSI方法进行自动评分;张翠翠等人 [8] 采用双向遍历空间模型算法,依据关键字和答案贴合度计算主观题分数。
上述研究方法虽然能提取到文本的整体信息,但是没有考虑到文本内部深层语义和语序等细粒度特征。2018年,Google公司的AI团队发布了BERT (Bidirectional Encoder Representation from Transformers)模型 [9]。BERT内部使用transformer编码器 [10] 搭建了双向的神经网络结构,以无标签的方式训练内部参数,提取含有上下文信息的词语和字符特征。实验结果表明,BERT模型在机器阅读理解顶级水平测试SQuAD1.1中的表现已经超越人类,并且还在11种不同自然语言处理测试中创出最佳成绩。针对BERT的训练参数过多造成的训练周期长等问题,Google公司又提出了基于BERT改进的ALBERT模型 [11],该模型在BERT的基础架构上使用因式分解和跨层参数共享的方式减少了需要训练的参数,极大地提高了训练效率。
将BERT模型直接应用于类似开放式作文等主观题机器自动评分自然是一个不错的选择,然而将BERT模型直接应用于简答题和叙述题等主观题,机器自动评分却难以取得最佳效果。因为,与开放的主观题不同,简答题和叙述题具有自身特点:首先,简答题和叙述题往往有参考答案,在人工评分时,评卷者考虑考生答题的语言逻辑和语句通顺等因素之前,首先考虑的还是考生答题是否符合得分要点(关键步或关键词);其次,汉语存在的一词多义、同义词等现象。基于此,本文模拟人工评分过程,将BERT和同义词词林同时应用于主观题自动评分中,具体步骤是:首先在领域公开数据集上应用BERT模型的Fine-tuning方法进行文本相似度训练;然后将主观题参考答案和学生答题输入到训练好的模型进行整体评价,获得参考答案和考生答题在文本级别的相似度;接着对参考答案和考生答题进行分词、提取关键词等操作后,通过同义词词林进行深层语义评价,计算参考答案和考生答题的在基于关键词的得分点上的相似度;最后综合上述两种相似度计算得到主观题最终评分。
2. ALBERT模型
ALBERT是Google公司AI团队发布的预训练语言模型 [11],采用双向的Transformer编码器结构 [10],如图1所示。其中:Ii表示单个词或字的向量输入,Trm即Transformer,Ti表示最终隐藏层输出,通过编码器里的注意力矩阵和注意力加权后,每个Ti都具有整句话上下文的语义信息。
Transformer是Encoder-Deocder结构的seq2seq模型,ALBERT模型使用了Transformer的Encoder层提取输入序列的特征信息,Encoder层由Self-Attention层、Feed Forward层和两个Add & Norm层组成,如图2所示。输入向量序列时,Transformer会把输入词的位置信息向量化后与原词向量相加,让输入词带有位置信息。之后编码器对输入的序列经过Self-Attention处理,通过计算词间关系矩阵并以加权计算的方式更新输入序列的词向量。在Self-Attention层和Feed Forward层后面都连着一个Add & Norm层,该层的操作就是将上一层的输出和Add & Norm层输出直接相加,然后再对相加结果进行归一化。Feed Forward层是一个简单结构的全连接前馈网络。
其中,在Encoder里,最重要的是Self-Attention层,如式(1)所示,其中Q、K、V是输入词向量矩阵,dk是K矩阵的维度。
(1)
在处理输入文本时,Self-Attention层可以计算出句子内部词与词之间的关联度,并利用词间的关联度进行权重计算调整原始输入,形成带有上下文信息的词向量。新的词向量由于融合了词性关系,相比原始输入更能体现词在全局序列中的关键度。
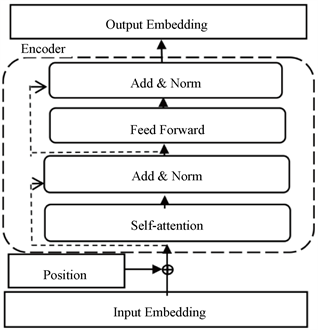
Figure 2. Transformer Encoder structure
图2. Transformer Encoder结构图
在实际应用中,Transformer使用的是Self-Attention的扩展版Multi-Head Attention。Multi-Head Attention通过多个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来,提高了关注输入句子的不同位置的能力,如公式(2) (3)。
(2)
(3)
ALBERT模型使用Transformer的Encoder层学习每个词的上下文信息,获得了更优秀的词向量。除此之外,ALBERT模型还用两个无监督预训练任务强化对词向量的语义表示能力,分别是Masked Language Model (简称MLM)和Sentence-Order Prediction (简称SOP)。
MLM任务:随机选取输入文本中15%的词做三种形式的替换,然后去预测被替换掉的词。形式一是用[Mask]标记替换掉80%的被替换词;形式二是用随机的一个词去代替本来要覆盖的词,随机替换的词占被替换词的10%;形式三是对余下10%的词不进行任何替换。这样设计是为了避免模型在微调时会过度依赖训练数据中不存在的[Mask]标记,同时也让模型在计算词向量的时候更依赖上下文信息。
SOP任务:通过提取同一文本中的两个句子A和B,预测句子中A和B的语序。取正序的A和B为正例,改变A和B的顺序作为反例。因为同一文本中描述的主题相同,所以在同一个文本中选取句子对可以减少文本主题的差异对训练效果的影响。
综上所述,通过MLM任务和SOP任务的结合,ALBERT模型可以更精准地描绘出文本的语义信息。
3. 同义词词林
同义词词林 [12] 是梅家驹等人在1983年所完成的同义词词典。由于时间长远,不适合当前年代的使用,于是哈尔滨工业大学信息检索实验室对该词林进行了扩展,完成了词林扩展版 [13]。扩展版共收录了77343条词语,比前一版本增加了2万多词语,并且增加了两层结构,如表1所示。

Table 1. Comparison before and after expansion of Cilin
表1. 词林扩展前后对比
扩展版通过建立一个树状层次结构将所有词语组织包含其中,如图3所示。词林整个树状结构从上到下分成五层,分别是大类层、中类层、小类层、词群和原子词群。同一个原子词群里的词语语义相同或十分接近或关联性很强。
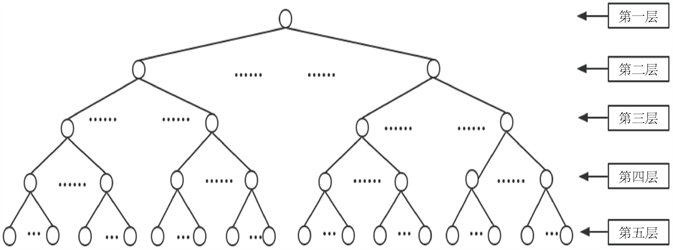
Figure 3. The tree-like hierarchical structure of Cilin
图3. 同义词词林的树状层次结构
词林对每个词语赋予唯一的8位编码,其中,高7位为树状层次结构各层次编码最低位为标记位,编码规则如表2所示。标记位主要是用于区分原子词群层次下的词语之间的语义关系,分常规同义词、相关词和只有词语本身(即没有同义词也没有相关词)三种情况,分别用“=”、“#”和“@”三个字符表示。
如编码“He03B14 = 出让转让让”表示词语“出让”、“转让”和“让”同属于H大类、e中类、03小类、B词群、14原子词群下三个词语,他们是同义词。
4. 基于ALBERT和同义词词林的主观题自动评分
计算评分的具体流程如图4所示。把主观题参考答案和学生答题输入到训练后的ALBERT模型,获得参考答案和学生答题在文本级别的相似度;同时使用同义词词林对从参考答案和学生答题提到的关键词序列进行相似度计算,得出两者基于关键词的得分相似度;最后综合两种相似度得到学生答题的综合预测评分,并针对题目总分以预测评分生成预测分数。
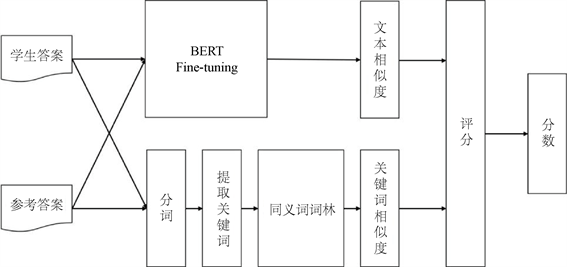
Figure 4. Automatic scoring flowchart for subjective questions
图4.主观题自动评分流程图
4.1. 文本相似度计算
利用ALBERT的Fine-tuning方法可以简单高效地实现自然语言序列之间的语义相似度计算。Fine-tuning方法把语义相似度任务归类为二分类任务,通过计算相似概率与不相似概率得出分类结果,具体流程如图5所示。首先将学生答题和参考答案输入到ALBERT模型中进行编码,然后将编码后的结果输入到式(4)的线性函数和式(5)的softmax函数进行Fine-tuning,最后得出两个文本的相似度。使用的损失函数是交叉熵损失函数,如式(6)所示。
(4)
(5)
(6)
4.2. 关键词相似度计算
关键词相似度的计算,就是对学生答题文本和参考答案文本进行关键词提取,然后对提到的关键词序列进行词语相似度的计算。
目前词语相似度的计算主要有两种方法,第一种是使用大规模的语料库,并通过一定的概率模型去计算;第二种是基于一些世界知识来计算,比如通过具有完备性的语义词典中的结构特点去计算 [14]。
本文用的是第一类的方法,基于同义词词林扩展版,并根据彭琦等人 [15] 提出的基于信息内容词语相似度计算公式计算词语相似度,如式(7)所示。
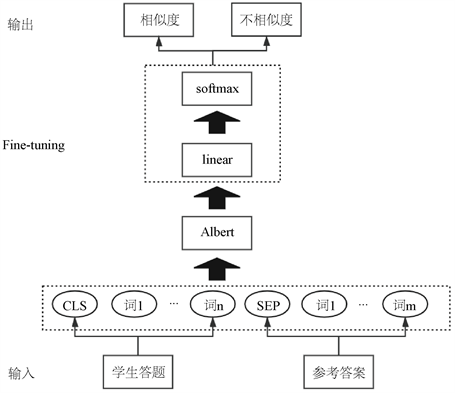
Figure 5. Block diagram of text similarity calculation
图5. 文本相似度计算框图
(7)
其中MaxDIFF和MinDIFF分别表示词林的最大差异性与最小差异性,当两个词语是两个不同大类下的叶子节点,最近公共父节点为根节点时,具有最大差异性,当两个词语在同一叶子节点上时,具有最小差异性,根据式(7)的差异性计算公式,可得出最大差异性为2,最小差异性为0。
(8)
(9)
在式(8)中,LCS(C1,C2)表示两个词语的最近公共父节点,IC(C)表示词语C的信息内容含量,由式(9)计算得出。式(9)中的hypo(C)表示词语所在节点的子节点个数,maxnodes表示词林里的全部节点的数量,取值90114。
具体方法如算法1所示。
4.3. 综合评分
教师在批改试题时,通常是先观察学生答案的整体作答情况,然后再查看学生答案中是否具有各个得分点的关键词,最后给出分数。通过参考教师批改试题的评分过程,本文提出了综合评分公式,如式(10)所示,其中TextSim是利用ALBERT得到的文本相似度,取值范围为0~1,KeySim是基于同义词词林计算得出的关键词相似度,取值范围也是0~1,MaxScore为题目的分值。其中α、β为超参数,由实验筛选出最佳取值。
(10)
5. 实验
5.1. Fine-Tuning实验
本文使用的中文预训练模型为albert_tiny_zh1,使用来自哈尔滨工业大学的LCQMC [16] 数据集,该数据集一共有26万多个带有是否相似标注的句子对,包括有训练集约24万个,验证集约9千个,测试集约1万2千多个。本文对该模型训练了5个epochs,最终在测试集上的准确率为85%。
5.2. 自动评分实验
5.2.1. 实验设置
本文选取了某中学高中阶段语文月考的一道阅读试题(满分为6分)作为测试数据,随机抽取了100份考生答卷,每份答卷均已由认可教师进行过人工评分。具体试题和参考答案如下:
试题:请简要概括我国大数据交易面临的困境有哪些?
参考答案:数据的开放和共享跟不上市场的发展,无法满足需求。各类数据主体缺乏共享理念。大数据交易缺乏统一标准,各大数据交易平台的交易规则也存在差异和缺陷,适用范围小。大数据专业人才匮乏。
利用同义词词林扩展版进行关键词相似度计算时,首先要对参考答案和考生答题进行分词以及关键词提取的操作。在本实验里,选用NLPIR2分词工具进行分词,筛选文本的实词作为关键词。
对于式(10)中α和β参数的设定,经过多次实验结果表明,当α为0.5,β为0.7时,自动评分和人工评分的分数最接近。
5.2.2. 实验结果分析
本实验选用准确率、QWKappa、平均误差分作为评价指标,选取基于同义词词林的方法、基于双向遍历空间的方法以及基于LDA的方法进行实验对比分析。评分结果如表3、图6所示。
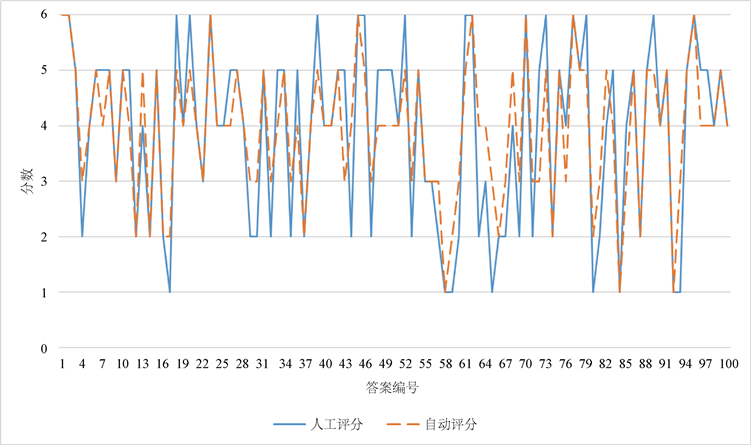
Figure 6. Comparison of manual scoring and automatic scoring
图6. 人工评分与自动评分的对比
由表3可以看出,本文提出的方法效果明显:在三个评价指标上均优于三个baseline方法。与表现最好的基于词林的方法相比,本文提出的方法在准确率、QWKappa、平均误差三项评价指标上分别提升了3.3个百分点、提升了0.13、降低0.2。与人工评分结果相比,本文方法自动评分分数已经非常贴近人工评分分数。总体来看,本文提出的自动评分方法已经取得良好的效果。
6. 总结与展望
针对有参考答案的主观题自动评分既要考虑关键得分点契合度,又要考虑文本整体相似度等问题,提出基于ALBERT和同义词词林的主观题自动评分方法。方法使用ALBERT预训练模型和同义词词林计算出参考答案与考生答题之间的文本语义相似度以及针对每个得分点的关键词相似度,最后结合两种相似度计算总体分数。实验表明,相比传统的方法,本文的方法在一定程度上提高了评分的性能。
该方法存在一定的弊端,它强调的是两个答案之间的相似度、贴合度,如果是没有标准答案的试题,该方法将束手无策。在下一步的研究工作中,将引入知识图谱等技术,让自动评分的适用性更广。
基金项目
广东省研究生教育创新计划项目(2017JGXM-ZD14)。广东省科技计划项目(2020B1010010010、2019B101001021)。
NOTES
1https://github.com/brightmart/albert_zh.
2https://ictclas.nlpir.org.