1. 引言
在后处理工艺过程中,单体设备常采用质量限制或几何限制等方法以确保核临界安全。当存在多个单体设备因实际需要组成多体时,因单体间中子扩散、慢化、反射等因素的影响,整个多体系统可能存在临界安全风险,因此,若能在多体系统运行时实时给出表征系统临界安全特性参数keff值,则既可对工艺过程进行监督,又能对人员安全提供保障 [1] [2] [3]。
在多体系统运行时,由于各系统间存在联系且运行时各参数动态变化,多体系统在考虑其临界安全问题时通常给出包络性计算结果,或给出若干关键危险状态点的中子有效增殖因数 [4] [5],针对系统运行时的实时临界安全状态无法定量评估,造成该问题的主要原因一方面在于系统参数的动态变化导致建立的系统模型不断改变,另一方面在于进行临界安全计算的软件(例如MCNP程序或MONK程序等)即使采用多核心并行计算方法,也无法同时兼顾计算结果准确性和计算的实时性 [6] [7]。
为解决上述问题,通常对简单的多体系统采用数据拟合方法来粗略估计keff值的变化,对于复杂的多体系统由于关键自变量参数繁多,使用常见的拟合方法难以给出自变量与keff值之间明确的拟合公式,粗拟合后进行结果修正的方法也无法给出精确解。因此,基于已有的实验或计算数据,发展快速预测系统临界安全状态的数值计算技术,是获得实时keff值的关键所在。利用BP神经网络进行拟合时,不需要再次建立几何模型,不需要拟合公式,只要通过训练得到合适的网络结构和参数,并且给出待分析多体系统的任意一组运行特性参数,即可实时得到相应的keff预测值 [8]。目前,采用神经网络算法对临界安全数据进行实时计算在国内属于首次探索,在国外文献中也还未见到该方面的应用,具有广阔的应用前景和价值。
2. 物理模型与计算模型的建立
以后处理工艺中硝酸铀酰溶液系统为例,在同一工艺间中通常存在多个储液罐、络合罐等,各工艺罐中物料浓度、硝酸含量、硝酸铀酰溶液总质量等各不相同,其共同组成一个多体系统。因工艺参数、工艺流程的保密特性,现对该模型简化后如图1所示。
已知质量和成份的硝酸铀酰溶液储存于单体1中,随着工艺的进行,以设定效率E1和E2分别进入单体2和单体3中,在单体2中完成相应工艺后,以效率E3进入单体4中。在整个溶液系统运行时,单体1、2、3、4共同组成一个多体系统,各单体间存在中子交换和中子相互作用。

Figure 1. Solution system model diagram
图1. 溶液系统模型图
因硝酸铀酰溶液供料参数的多变性,工艺动态变化的特性,单体1中硝酸铀酰溶液的质量和成份在一定范围内变化,工艺效率E1、E2、E3也随着工艺的进行发生变化,从而导致单体2、单体3和单体4中物料的成份及质量发生变化。若想得到任意时刻该多体系统有效中子增殖因数的准确值,除使用程序开展计算外别无它法。
建立基于神经网络的计算模型,不受物理模型复杂度的影响,可以快速计算任意时刻的keff值:在预先给定的临界安全计算数据集的基础上,通过合理搭建和精细调参,确定神经网络模型;对于实时给出的任意一个临界安全状态,高精度、快速给出当前状态下对应的keff值,对于判定系统临界安全裕量具有重要参考作用。
3. BP神经网络原理
人工神经网络(简称神经网络)是基于生物学中神经网络的基本原理,以网络拓扑知识为理论基础,模拟人脑的神经系统对复杂信息的处理机制的一种数学模型 [9] [10]。神经网络通过网络的拓扑关系、权重、激励函数等网络参数的调节,实现非线性拟合功能,是确定性拟合的进阶,是不需要函数表达式的高级拟合技术。
典型的BP神经网络由输入层、输出层以及中间的隐含层构成,是一种误差反向传播网络。设输入层维度为n0,隐含层节点数为m,输出层节点数为n1,用l代表层数。第
层第i个节点与下一层第j个节点的连接权值表示为
。节点偏置表示为
。图2为n0 = 3、n1 = 2、m = 3、偏置为
的3层神经网络示意图。
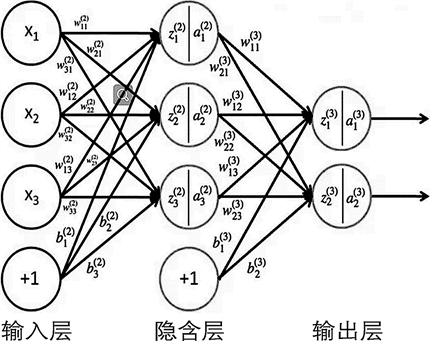
Figure 2. Schematic diagram of neural network structure and parameter
图2. 神经网络结构、参数示意图
设有1个输入维度为N、输出维度为q、隐含层节点数为m的3层BP神经网络。对于输入层,输入等于输出。用
表示第k层的第h个节点的输入,
表示相应的输出。
、
表示偏置,
代表激活函数。
对于隐含层的第j个节点有:
(1)
(2)
对于输出层的第j个节点有:
(3)
(4)
然后定义1个损失函数E:
(5)
式中,
为输出层第i个节点期望输出。
BP神经网络的学习过程就是以降低损失函数E为目标,不断调整输入输出层的权值w,令期望输出和实际输出靠近的迭代过程。这是一个优化问题,通常采用梯度下降算法来优化权值。梯度下降算法用公式如下:
(6)
上式中:n为迭代次数;
为学习率,
的取值对算法的收敛性和收敛速度有较大的影响。
根据“万能逼近定理”,只要给予网络足够数量的隐藏单元,BP神经网络能够以任意精度逼近任意复杂度的连续函数 [11] [12] [13]。
4. keff参数预测
4.1. 原始数据获取
在一定条件下,通过分析目标系统(如硝酸铀酰溶液系统)的动态过程,得到影响系统keff值(简称k值,下同)的关键特征X,它们存在
关系,其中向量X为其他与时间无关的条件,如质量(Quality)、成份(Ingredient)、效率Ei(
)等,t为时间参数。
根据实际经验,某系统除了8个时间节点外,k值数据随时间呈线性变化规律,对于不在该时间点上的k可以通过线性插值得到。该系统的k值在这8个节点上只与5个关键参数
有关。因此在固定时间点上,可简化关系为
。在5个关键参数允许范围内均匀取样本点,利用MCNP程序分别计算8个时间节点(0分钟、1分钟、2分钟、5分钟、10分钟、50分钟、100分钟、150分钟)上的有效增殖系数keff。
基于蒙特卡罗计算的原始数据,由于模型复杂、精度要求高,每个时间点分别生成2660组数据,计算时间在数十分钟到数小时。获得原始样本数据集T:
(7)
其中,Xi 表示输入向量,包含质量(Quality)、成份(Ingredient)、效率1 (Effect1)、效率2 (Effect2)、效率3 (Effect3)等5个维度的数据,yi为对应的k值,称(Xi, yi)为一个样本,m代表数据集的样本总量,这里m = 2660,n代表了输入向量的维度,这里n = 5。
4.2. 数据预处理
(一) 数据标准化
使用min-max标准化方法对包括输出在内的每一特征进行数据进行归一化:
(8)
使得同一特征的数据处在(0, 1)之间,图3展示了归一化后的数据集。由于输出进行了归一化,真实输出的计算公式:
(9)
由上式可知,计算真实输出需要获得样本的最小值、最大值与最小值的差。
(二) 划分数据集:测试集与训练集
8个时刻各对应一个数据集,对每个数据集随机打乱顺序,然后按照3:7比例分割为测试集和训练集。利用训练集中的数据对神经网络进行训练,利用测试集中的数据来检验经过训练后神经网络的预测能力(精度)。
4.3. BP网络的构建
基于样本数据,需通过不断的调节BP神经网络中包括隐藏层数量、隐藏层节点数量、激活函数、学习率、迭代次数等诸多参数,最终确定合适的网络结构。图4为BP人工神经网络拓扑结构图,该网络仅含一层隐藏层,输入层含5个节点,输出层为1个节点,隐藏层为128个节点。表1为神经网络的一些超参数设置,它们需要反复调试来确定,连同网络结构一起实现了网络的拟合性能。
8个节点对应的神经网络在结构上是一致的,但是样本数据集不同,最终得到的模型权值不同,性能也不同。

Table 1. Other parameters of BP neural network
表1. BP神经网络的其他参数
4.4. 神经网络训练结果分析
图5是8个时刻k值的神经网络模型训练过程中损失函数、平均相对误差随迭代次数的变化曲线。

Figure 5. Change curve of loss function and error function in neural network training
图5. 神经网络训练中损失函数、误差函数的变化曲线
每个时间节点包括2个图,左图是损失函数随迭代次数的变化曲线,损失函数(loss)从迭代开始就急剧下降,直到100多代之后趋于平缓,缓慢下降直至300多代。实线为训练集上的损失值,虚线为测试集上的损失值,图中两者变化趋势基本相同,几乎重合在一起。右图是平均相对误差随迭代次数的变化曲线,实线为训练集上的误差,虚线为测试集上的误差,8个时刻的曲线略有不同,但是趋势相同。
表2统计了8个时刻模型的训练收敛时测试集的均方误差、平均误差和最大误差。8个模型的均方误差均在3 × 10−5以内,平均误差在1%左右,最大误差不超过4%。无论是从数据拟合程度角度还是从工程实践角度,均满足要求。
Table 2. Training results of 8 node-data
表2. 8个节点数据的训练结果
5. k值随时间变化曲线的拟合
5.1. 不在8个时间点上的keff参数预测
一旦给定质量(Quality)、成份(Ingredient)、效率1 (Effect1)、效率2 (Effect2)、效率3 (Effect3)这5个参量的值,根据已训练的BP神经网络模型,即可预测0 mins、1 mins、2 mins、5 mins、10 mins、50 mins、100 mins、150 mins等8个时刻点上k的值。对于处于这些时刻之间的时刻t,k值数据(kt)随时间呈线性变化,可利用其左右两个相邻时间节点上的值进行线性插值得到 [14],如式(10):
(10)
其中,
、
为
、
时刻的keff值。
给定一组已知参数数据,转化为输入数据
(已归一化),对应质量(Quality)、成份(Ingredient)、效率1 (Effect1)、效率2 (Effect2)、效率3 (Effect3) 5个参量的值。其蒙特卡罗模拟计算出8个时刻的k值如表3第2行(模拟结果)所示,作为真实值。利用8个训练好的神经网络预测出的结果,如表3中第3行(预测结果)所示,作为预测值。表3最后1行给出了每个时间节点中真实k值(模拟结果)与预测值(预测结果)之间的相对误差,该值在0到0.77%之间,预测结果精度很高,从图6 (“-o-”为真实值对应的曲线,“--x--”为拟合曲线)中可以看出两条曲线几乎完全重叠在一起。
值得指出的是,计算一个示例,蒙特卡罗模拟单机计算需要大约1小时时间才能获得结果,而基于上述网络的预测模型,只需要0.5~1.5秒,仅前者的4/104左右,其计算速度发生本质的变化。对于复杂模型,蒙卡模拟的计算时间还会增加,而基于神经网络的预测模型则几乎不会变化。
5.2. 误差评估
显然,节点外t时刻k值的误差与ti+1、ti时刻的误差有直接关系,式(11)计算出其预测误差的上界:
(11)
式(11)说明,只需保证节点上足够小的误差,整个拟合曲线的误差也会足够小。根据表2可知,在整个拟合曲线的任意一个时刻,BP神经网络预测的k值平均误差在1.1%以内。
6. 结论
利用多体系统的核安全临界的数据集或者其MCNP模拟数据集,通过数据预处理、搭建网络拓扑结构、调参、训练和测试等一系列过程,构建精度较高的BP神经网络模型,可以实现核临界安全keff参数的实时智能预测。在一定条件下,神经网络预测模型对任意给定系统的质量、成分、效率1、效率2、效率3和时间等参数,不需要求解函数关系、推导物理模型,就可以快速准确预测出keff参数的值,从而以该数据为基础对系统运行状态及安全性能进行实时评估。该方法不需要过多的专业知识,且可以毫无困难的推广至系统运行其他关键参数的实时预测,是非常具有前景的方法。