1. 引言
随着当今社会互联网和自媒体的普及,网络技术的日益革新,新闻文本每天都会大量产生,互联网作为新闻传播的新媒介,存储了海量的信息。但是由于这些文本信息大都是以非结构化的方式存储在互联网中,使得其很难被处理,面对这巨大的信息财富,一个快速从中获取有价值信息的方法显得越来越重要。
新闻一般以事件的形式呈现出来,对新闻中蕴含的事件进行抽取,可达到快速获取主要信息的目的。一般的顺序不敏感模型没有明确的位置标记,可能会导致在处理语法敏感的任务时由于语序或者语法结构的影响不能完全捕获自然语言的语义。因此我们采用上下文敏感的模型进行事件抽取任务。接着很多研究中使用端到端的神经网络进行训练,其性能通常较好,但由于事件抽取任务的复杂性,其通常伴随大量参数从而导致巨大的计算力使用。至此,本文提出一种简洁事件抽取模型架,基于上下文敏感模型产生的预训练词向量且具有更少的参数,输出上采用类似于在SQuAD等阅读理解任务上的输出对中文事件进行抽取。
2. 相关研究
一般认为,事件抽取要区分为元事件抽取与主题事件抽取两种任务。元事件表示一个动作的发生或状态的变化 [1],包括参与该事件的主客体,通常由动词或动名词作为触发词。主题事件包括一类核心事件或活动以及所有与之直接相关的事件和活动 [2],可以由多个元事件构成。本文探讨研究的范畴只限定于元事件抽取,下文统称为事件抽取。图1描述了一个事件的构成:

Figure 1. The basic constitutive elements of a “release” event
图1. “发布”事件的基本构成要素
事件由事件触发词(Trigger)和描述事件结构的元素(Argument)构成。事件抽取作为知识抽取领域的一个子任务,也是其一个非常重要的研究方向,一直受到许多研究者们的注意。对事件抽取的研究主要分为模式匹配和机器学习两大类方法。
2.1. 基于模式匹配的事件抽取
基于模式匹配的方法是在一些人工定义的模式下对事件进行识别和抽取,模式主要用于指明构成目标信息的上下文约束环境 [2],主体思想是融合语言知识与领域知识。ExDisco [3],GenPAM [4] 是两个典型的基于模式匹配的事件抽取系统。基于模式匹配方法适合应用于特定领域,能达到较高的性能需求,但移植性较差,且需要在领域专家的指导下构建。
2.2. 基于机器学习的事件抽取
事件抽取任务在机器学习方法一般中一般被视为分类问题。基于机器学习的方法又可划分为传统机器学习和深度学习。
传统机器学习的研究主要在于对候选触发词和论元的语法、句法和语意等等特征进行研究以进行捕捉,之后基于统计分类模型进行分类。文献 [5] 用MegaM二元分类器和TiMBL多元分类器进行事件抽取,在ACE英文数据集上取得较好效果。文献 [6] 结合触发词和二元分类相进行事件抽取,在ACE中文数据集上取得较好效果。
随着大数据时代到来,以及计算机算力的快速增长,近年又随之兴起深度学习方法,其能学习到不同于传统机器学习离散型特征的连续型向量特征。文献 [7] 率先将深度学习方法应用于事件抽取,采用预训练的词向量的同时融入对于单词的语义语法的建模,接着利用位置信息来描述各个词与候选触发词的距离,取得了很好的效果。文献 [8] 提出一种联合学习事件识别和论元角色分类的基于RNN的模型,在论元角色分类任务上达到SOTA效果。
2.3. 词向量表示
词向量表示对事件抽取任务有着重要意义,同时其也是NLP领域非常热门的一个研究方向。其是将不可计算、非结构化的词转化为可计算、结构化的向量。较早的词向量训练工具Word2Vec9 [9] 将每个词映射到唯一的向量,从而表示词与词之间的关系,但由于其词和向量的一对一关系,所以无法解决一词多义的问题。文献 [10] 提出的ELMo模型,基于双层Bi-LSTM,双向拼接正向编码器和反向编码器提取特征信息,使上下文无关的静态向量变为上下文相关的动态向量。文献 [11] 提出了GPT模型,与ELMo模型的不同点是GPT采用Transformer替代LSTM作为模型进行特征提取,但GPT只使用了单向编码。考虑到ELMo和GPT都不能同时利用两个方向的信息,谷歌提出了使用双向transformer的BERT [12] 模型。
3. 基于BERT-DGCNN的新闻类内容事件抽取模型
本模型分为两部分:第一部分为事件类型预测模型,第二部分为对事件角色抽取模型,其中第一部分的抽取结果同时与文本作为第二部分的输入。
3.1. 事件类型抽取模型
模型共分为三部分:句子级编码层、膨胀门卷积网络层与平均池化层、分类层。图2描述了事件类型抽取模型的整体框架:
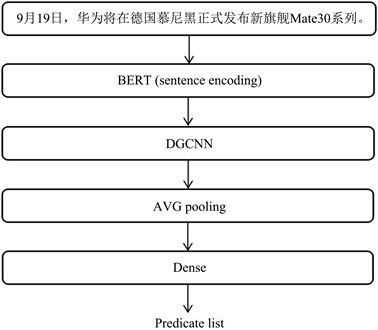
Figure 2. The framework of the event type predication model
图2. 事件类型预测模型框架
3.1.1. 句子级编码层
本层使用BERT (Bidirectional Encoder Representation from Transformers) [12] 得到句子级编码特性。它是由谷歌在2018年提出的一种预训练模型,基于双向transformer,创新地引入了MASK语言模型与Next Sentence Prediction机制,前者用来解决transformer只能利用单向信息的问题,后者能够让模型学习到句子间的关系。
BERT的输入由三部分组成:Token Embeddings、Segment Embeddings、Position Embeddings。其中Token Embeddings是词向量,在中文NLP任务中,只需要在句子本文开头添加一个特殊的token:[CLS],文本末尾添加token [SEP],以及未登录词典字换为[UNK]即可;Segment Embeddings用于区分输入中的第一个句子和第二个句子,本任务输入只有一个句子,全部设置为0即可;Position Embeddings用于对文本的字符进行位置编码,因为一般认为transformer没有对输入进行位置编码。
本文实验中使用的是Google发布的BERT-Base中文版,该模型使用12层的Transformer,隐藏层维度大小为768,自注意力multi-head = 12,模型所有参数为12 × 768 × 12 = 110 M,使用GPU内存7G多。
3.1.2. 膨胀门卷积神经网络(Dilated Grated CNN)与池化
膨胀门卷积神经网络,将门卷积与膨胀卷积融合使用。令门卷积假设处理序列为:
,我们对普通的一维卷积添加一个门:
使用两个形式相同但权值互不共享的Conv1D网络,其中后者使用sigmoid函数激活,而前者没有使用,之后再逐位相乘。sigmoid激活后的Conv1D函数值域为(0, 1),类似于将其每个输出施加一个阀门。
接着使用残差结构:输出以(1 − ξ)的概率直接通过,ξ的概率经过变换后通过,如公式表达:
其中σ即为sigmoid操作,使用残差结构的意义一方面在于使得梯度消失的可能性更低,另一方面可以在多通道传输信息。
之后我们使用膨胀卷积代替普通卷积,普通卷积捕捉与中心相邻的输入,而膨胀卷积捕捉到的是与中心有间隔的输入,像是一个窗口内被挖空若干单元的卷积,所以也叫空洞卷积,这样可以在不给模型添加参数的情况下,使得CNN能够捕捉更远距离的特征。
接着对DGCNN的输出进行池化,池化的作用是使得要处理的特征个数和参数减少。常用的池化有最大池化、平均池化和随机池化。最大池化一般能获取最显著的特征,平均池化可以保留数据整体的特征,随机池化中元素值大小和元素被选中的概率成正相关。本模型使用的是平均池化。
3.1.3. 分类层
一段文本可能含有多个事件类型,所以本文将其视作一个多标签任务,分类层使用一个全连接层后,以池化结果作为输入,使用sigmoid函数进行输出。
3.1.4. 损失函数的设计
下面给出损失函数的设计:
其中yti为标签值,yi为预测值,
为原始交叉熵损失函数。
作为边界指示函数,只惩罚模型还未充分学到的样本,忽略已可分样本用于解决样本噪声与类别不平衡问题,
其定义如下:
其中又有
,用来表示已可分样本,m用来设定样本被正确识别的阙值。
3.2. 事件角色抽取模型
这部分的模型结构与事件类型预测模型除输出部分外基本一致。
输入部分:将前一模型预测结果与事件角色拼接作为BERT输入sequence 1,文本作为输入sequence 2,如图3所示:

Figure 3. Event extraction model input sample
图3. 事件抽取模型输入示例
输出部分:使用类似于在SQuAD等阅读理解任务上的输出,每个token有两个作为事件论元角色首末地址的概率输出,这些概率不互斥所以使用Sigmoid输出,并且便于加入先验分数、选取多个候选项和进行阙值筛选等。
4. 实验设计和实验结果分析
4.1. 数据集
本文采用的是目前中文事件抽取DuEE数据集,其定义了8个主事件类别,每个类别包含若干个子事件类型,共65个事件类型和121个事件角色类别。数据集总共包括1.7万个中文句子,其中1.3万作为训练集,0.15万作为验证集,0.35万作为测试集。
4.2. 实验环境与超参数设置
本文实验采用谷歌Cloab平台进行,它是一种托管式 Jupyter 笔记本服务,免费提供GPU甚至TPU算力,十分适合机器学习任务。本任务使用Linux 18.04.5 LTS操作系统,GPU算力是Nvidia K80,python版本为3.6,BERT版本为中文版BERT-BASE。
BERT的训练超参数如表1所示:

Table 1. The hyperparameters of BERT model
表1. BERT模型超参数设置
4.3. 评价指标及评价方法
此次实验按字级别匹配进行打分,选用精确率(P)、召回率(R)以及F1值作为评价指标,计算公式为:
其中,
;
;
;
。
4.4. 实验结果
将本文提出的BERT-DGCNN模型与ERNIE-CRF、BERT-base、BERT-CRF三种模型进行比较,实验结果如下表所示:
Table 2. The experiment results of each event extraction model
表2. 各事件抽取模型实验结果
从表2可以看到,本文的模型在百度DuEE数据集上取得了相对不错的结果,ERNIE-CRF和BERT-CRF差距比较大的原因可能是初始预训练语料存在一定差异同时对模型的迭代方式存在一定差别。BERT-CRF相对于BERT-Base在F1值上提升的效果并不明显可能是因为加上CRF使得模型对训练集的拟合效果较好,但相对的泛化能力有所减弱。BERT-DGCNN模型相较于BERT-CRF在准确率、回率和F1值三个指标上都有所提升,说明了本模型在中文事件抽取任务上效果有所提升。
5. 结束语
本文提出一种基于BERT预训练模型的中文事件抽取pipeline模型,利用BERT模型产生词嵌入,DGCNN对上层产生的向量化序列进行编码,之后将DGCNN池化结果送入一个全连接层进行分类。实验结果显示,本文提出的模型在DuEE数据集上实验效果较好。在接下来工作中,计划针对特定领域,对模型进行优化,以技术支持特定领域知识图谱的构建等工作。
基金项目
合肥工业大学2019年大学生创新创业训练计划项目国家级项目:基于知识图谱的新闻类内容校验系统(项目编号:201910359097)。