1. 引言
随着我国信用经济规模的迅速发展,越来越多的人通过信用卡、蚂蚁花呗、京东白条等信用产品进行有别于传统消费模式的超前消费。因此信用贷款、以个人名义的无抵押贷款等业务在商业银行、互联网金融机构及消费金融公司中所占的比例越来越大,与此同时,信贷违约问题也随之增多。然而客户违约问题严重影响了信贷行业的发展,进而使市场经济活动面临重大风险隐患,因此准确高效的信用评估算法能很好地规避信用违约带来的风险。
大多数学者认为,个人信用风险评估就是根据个人的信用信息,通过建立相应的数学模型对信贷客户进行科学的信用风险评估 [1] [2]。一般来说,我们将申请贷款的客户分为违约和不违约两类,因此信用风险分析可以看作是一个二分类问题。Durand (1941) [3] 最早将Fisher (1936) [4] 针对鸢尾花分类问题提出的多元判别分析法应用到信用风险分析中,他通过计算同意贷款带来的风险判定客户类别,进而引发了业界的研究兴趣。随后,Wiginton (1980) [5] 最先在信用评估中运用Logistic回归算法并与多元判别分析法进行对比,结果表明Logistic算法的建模效果更优。目前,Logistic算法已经是使用较为广泛的信用评级模型 [6]。罗昊(2016) [7] 将自适应Lasso与Logistic相互结合,进行了变量选择以及参数估计,基于信息权重的Logistic信用评估模型由此被提出。李海超等人(2017) [8] 运用Lasso回归算法,建立了最优变量子集回归模型来对影响网络借贷成功的影响因素进行分析,同时还提高了拟合精度。除此之外,Odom等人(1990) [9] 将深度学习最先运用到信用评估领域。Baesens等人(2003) [10] 在某信用数据集上比较了SVM与其他算法,结果表明SVM的分类效果更优。Yeh等人(2007) [11] 基于决策树对信贷数据集进行信用评估,并与多种模型对比分析,结果表明决策树有着相对不错的分类性能。近年来,Sang等人(2016) [12] 提出了一种基于并行随机森林分类器的信用评分模型来评估申请人的信用风险。Jena等人(2017) [13] 运用k近邻分类器在澳大利亚信贷和德国信贷两个数据集上预测贷款人的能力。Xia等人(2017) [14] 基于 XGBoost算法构建了XGBoost-TPE模型并使用多个信用数据集进行检验,结果表明该模型能够有效提高个人信用评估的分类性能。Ma等人(2018) [15] 对于P2P网络贷款违约现象,运用机器学习中的Light GBM和XGBoost算法进行研究,结果表明在多个信用数据集分类中Light GBM算法的预测效果最佳。
然而在实际中,我们会面临变量较多,建模耗时费力等情况,为了得到简单高效的模型,我们需要在建模前进行变量选择。基于这一想法,本文提出Lasso-CatBoost算法,并以某银行的个人信用数据为样本来构建个人信用评估模型,与传统logistics回归算法、随机森林、Adaboost、XGBoost、LightGBM等集成算法相比,Lasso-CatBoost算法使用了较少的特征,体现了通过该算法建模的简单性。其次,比较各个算法的AUC指标和ROC曲线,我们得到Lasso-CatBoost算法的预测效果最好。综上研究结果,Lasso-CatBoost算法能帮助银行信贷机构正确评估申请贷款的客户,提高工作效率和减少风险,具有重大的商业价值。
2. Lasso-CatBoost算法
2.1. Lasso算法
Lasso算法对于一般的回归模型:
(1)
其中
是被解释变量,
是解释变量矩阵,
是未知模型参数,
是误差项。我们由此可以预测响应变量
:
(2)
其中
是通过估计得到的模型参数。常用的估计方法有最小二乘估计和极大似然估计,但是这两种方法不能对变量进行选择,使得模型的预测和解释能力不佳。因此,一些惩罚技术被开发出来以提高预测效果。Lasso是一种使用
正则化来选择变量,它可以减少某些变量的系数,甚至是绝对值小于0的系数,从而提高了模型的泛化能力:
(3)
式(3)的第一部分是最小二乘估计的目标函数,表示模型的拟合情况。第二部则是对变量施加惩罚,为了达到变量选择的目的,将绝对值较小的系数压缩为0。
2.2. CatBoost算法
CatBoost是2017年俄罗斯搜索巨头Yandex推出的一种机器学习库,是Boosting族算法的一种。CatBoost和XGBoost、LightGBM是GBDT的三个主要算法。它们都是在GBDT算法框架下的改进实现。XGBoost在工业上得到了广泛应用,LightGBM有效地提高了GBDT的计算效率,而Yandex的CatBoost算法在算法精度上优于XGBoost和LightGBM。CatBoost是一种基于对称决策树(oblivious trees)的GBDT框架,具有参数少、支持分类变量、精度高等优点。
主要的难点在于如何有效合理地处理类别型特征,Categorical和Boosting组成了CatBoost。另外,CatBoost还解决了梯度偏差(Gradient Bias)和预测偏移(Prediction shift)的问题,减少了过拟合的发生,提高了算法的精度和泛化能力。
CatBoost具有提供分类列索引的灵活性,通过使用one_hot_max_size将其编码为独热编码。假设数
据集
,其中
是一个包含m个特征的向量,
是标签的值。
首先,CatBoost算法对所有的数值特征进行二值化:使用oblivious树为基预测器,将浮点特征、统计信息与one-hot编码进行二值化。
其次,利用计算出的数值(TS:Target Statistic)代替
的处理分类特征的方法是有效的:1) 随机排序输入观测集以生成多个随机序列。2) 计算将同一类别置于给定值之前的标签值分类之一,此TS值的计
算如下:
。由于某些类别出现的次数少,所以需要做平滑处理,将所有的分类特征值转
换为数值
(4)
其中
为指示函数:满足条件
则函数值取1,否则函数值取0。P为先验值,参数
为先验的权重,
。添加先验值有助于减少从低频类别中获得的噪音。
最后,进行特征组合处理时,CatBoost算法采用“贪婪策略”组合:1) 在树的第一次分裂中,不进行组合;2) 在第二次分裂中,当前树中的所有现有组合和分类特征与数据集中的所有分类特征相结合;3) 对组合结果进行了分析,将树中选择的所有分区作为二值分类,组合生成数字特征和分类特征的组合。
在梯度偏差处理中,CatBoost算法分两步构造树:1) 选择树结构,确定树结构,计算叶节点值;2)列出不同的分割方法来计算叶节点值。对获得的树记下评分以选择最佳分割。采用梯度或牛顿步长来逼近两步叶节点值。
CatBoost实现了训练数据集与处理类特征的同步,大大提高了特征处理的效率。同时,叶节点计算算法可以有效地避免“过拟合”,减少参数设置的需要,使模型更具通用性。同时,CatBoost将特征二值化处理,从而实现了最终打分时,模型输出的二值化。
2.3. Lasso-CatBoost算法
本文的创新算法Lasso-CatBoost算法(如图1)是根据以上Lasso和CatBoost的基础理论,我们提出下面的Lasso-CatBoost算法,即Lasso和CatBoost两阶段的组合。首先根据Lasso中对回归系数的
正则化约束,将对信用评估有影响的特征筛选出来,同时删除对信用评估几乎没有影响的特征,从而降低数据的维度。随后使用Lasso筛选出来的特征作为CatBoost的输入,进而构建信用风险评估模型。因此,Lasso-CatBoost算法充分结合了Lasso筛选变量的特点和CatBoost分类准确率高的特点。
3. 实验结果及分析
3.1. 数据来源及描述
本文采用了是kaggle网中名为default of credit card clients的信用数据集。该数据集包含2005年4月至2005年9月某地区30000个不同的信用卡客户信息,其中,诚信客户有23364个,违约客户有6636个。具体的客户信息包括拖欠付款、人口统计因素、信用资料、付款历史及账单结单。我们将这些数据分为23个自变量,1个因变量。其中自变量有4个类别型变量,19个数值型变量。因变量有两个取值,分别为“0”和“1”,其中0表示信用好的客户,而1表示信用差的客户。
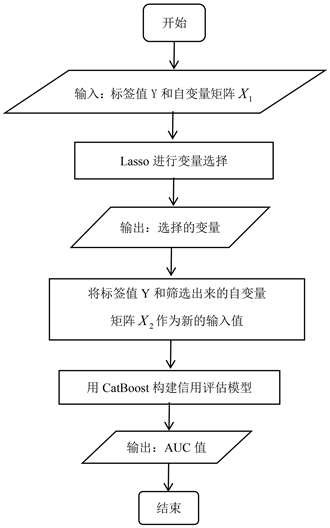
Figure 1. Lasso-Catboost algorithm flow chart
图1. Lasso-CatBoost算法流程图

Table 1. Default data of credit card customers
表1. 信用卡客户违约数据
对表1进行变量说明:X1为LIMIT_BAL表示信用额度;X2为SEX表示性别;X3为EDUCATION表示学历;X4为MARRIAGE表示婚姻状态;X5为AGE表示年龄;X6~X11是PAY_1~PAY_6:PAY_1为2005年9月的还款情况、……、PAY_6为2005年4月的还款情况;X12~X17是BILL_AMT1~BILL_AMT6:BILL_AMT1为2005年9月的账单记录、BILL_AMT2为2005年8月的账单记录、……、BILL_AMT6为2005年4月的账单记录;X18~X23是PAY_AMT1~PAY_AMT6:PAY_AMT1为2005年9月的支付记录、PAY_AMT2为2005年8月的支付记录、……、PAY_AMT6为2005年4月的支付记录。
PAY_1~PAY_6的取值含义为:0 = 及时还;1 = 延迟1个月还款;2 = 延迟2个月换狂;3 = 延迟3个月还款;……;9 = 还款延迟九个月及以上。每月的支付金额PAY_AMT大于每月的还款最低额,否则判定为违约。如果支付金额PAY_AMT大于上月账单金额BILL_AMT,视为还款及时,剩余金额存入信用卡下次消费;支付金额低于上月账单金额但高于最低还款额的,视为延期还款。
以下是对于性别、学历、婚姻状况及年龄4个类别型变量在信用贷款中的具体影响进行简单的统计分析。
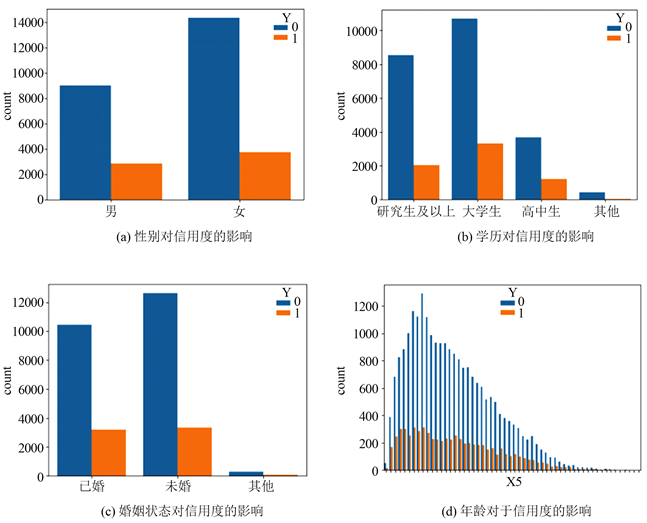
Figure 2. The influence of gender, education background, marriage and age on credit
图2. 性别、学历、婚姻、年龄对信用度的影响
通过图2(a)我们可以了解到女性整体贷款人数大于男性,但是在贷款的男性女性中,男性违约率高于女性违约率。图2(b)中学历不同,贷款人数不同。从贷款总人数来看,大学生排第一,研究生及以上排第二,然而研究生及以上学历人群的违约率略高,因此并不是学历越高,违约率越低。图2(c)表明未婚人群贷款人数大于已婚人数,而相比之下已婚人群的违约率较高。图2(d)说明在信用贷款中年轻人贷款居多,而这部分人的违约率也是比别的年龄段人的违约率高。
3.2. Lasso变量选择及Catboost参数设置
本文的数据集共有30,000个样本,其中有23个变量,数据相对庞大,在银行等实际工作过程中,这样建立的模型过于复杂,需要消耗的资金人力均过大,不够经济实惠,那么我们构建的模型就不符合实际情况,实用性将下降。因此本文运用Lasso算法进行变量筛选,对变量进行降维处理,挑选相对重要的变量,剔除系数为零的变量。最终我们通过Lasso算法删除了六个系数为零的变量,分别为X10即2005年5月的还款情况、X11即2005年4月的还款情况、X14即2005年7月的账单记录、X15即2005年6月的账单记录、X17即2005年4月的账单记录、X19即2005年8月的支付记录,选取了剩余17个系数不为零的变量作为CatBoost算法的输入值。
本文基于CatBoost算法构建个人信用评估模型。我们不断地调整参数,经过交叉验证后以AUC值为评级指标,最终选取的参数如下表2。
调整好参数、建立模型后,我们得到了基于Lasso-CatBoost算法的特征重要性排序,如图3所示。
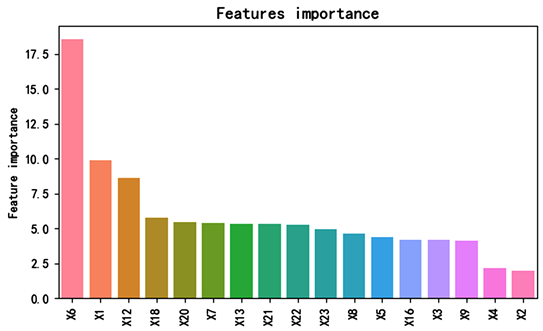
Figure 3. Ranking of feature importance
图3. 特征重要性排序
从图中可以看出,2005年9月的还款情况这一因变量最重要,明显高出其余变量许多,根据实际情况也可以考虑到,还款及时,是信用表现良好的重要指标;信用额度居第二重要,如果开始银行给与客户的信用额度,包括个人信用额度和客户的家庭信用额度就高的话,说明在贷款之前就进行过调查研究,信用额度高也能说明信用可能良好;第三重要的是2005年9月的账单记录。根据给出的重要性排序,在实际银行贷款审核是否同意放贷过程中,应该更加注意这些变量所带来的影响。
3.3. 评价指标
算法性能评估主要通过准确率、精确率、召回率、AUC以及ROC曲线图等指标进行比较,接下来结合本文研究的问题对这些指标进行简单介绍。
混淆矩阵(confusion matrix)是衡量一个分类器分类效果准确程度的矩阵,如表3。
准确率(Accuracy)是所有样本数量中预测正确的比例,即预测的正例实际为正例,预测的反例实际为反例的占比。
(6)
精确率(Precision)是预测为正例的所有样本中,实际也确实是正例的样本数量所占的比例。
(7)
召回率(Recall)是预测为正例的样本数量占实际就为正例的样本的比例。
(8)
有时候精确率和召回率会出现矛盾,此时应该综合评价这两个指标,对它们进行加权调和平均,就是F-Score,当
时,就是最常用的F1值:
(9)
ROC曲线:受试者工作特征曲线(receiver operating characteristic curve,简称ROC曲线)。采用真阳性率和假阳性率作出的曲线,横轴FPR:1-TPR,纵轴TPR。FPR越大,预测出为正例的样本数量中实际是负例的样本量越多;TPR越大,预测出为正例的样本数量中实际为正例的数量也越多。
(10)
(11)
AUC (Area Under Curve)值为ROC曲线下方的面积大小。显然,AUC越大,预测效果越好。
3.4. 多种模型对比分析
为了更准确地分析所构建的Lasso-CatBoost算法模型的性能,文章选取了除该分类算法以外的其他5种分类算法,分别为Logistics、RandomForest、Adaboost、Xgboost、LightGBM进行对比研究。这6种算法在训练集为0.7、测试集为0.3的比例下,得出了各自的混淆矩阵如图4。

Figure 4. Confusion matrix of six algorithms
图4. 6种算法的混淆矩阵
从图4各个算法的混淆矩阵图可以简单计算分析得到,Lasso-CatBoost算法是正确预测违约或者不违约的客户人数占总样本人数比例最高的算法,即在特征经过Lasso变量选择后,减少6个变量,与其他算法相比较准确率仍然是最高的。那么可以初步认为本文所建立的Lasso-CatBoost算法这一想法是可行的。
那么接下来进一步通过多方面、多种评价指标进行验证。对于分类问题,常用的评估指标是准确率,对于银行来说,精确率、召回率和F1这3个指标也具有实际意义,而AUC 值也是金融风控中常用的评估指标,因此模型的性能评价以AUC值为主(表4)。
Table 4. Comparison between different classification algorithms and Lasso catboost
表4. 不同分类算法与Lasso-CatBoost的对比
在所有算法中,Lasso-CatBoost算法的准确率最高,即正确预测违约或者不违约的客户人数占总样本人数的比例为0.8268,RandomForest、Xgboost居第二第三;所有预测为不违约风险客户中,实际正确的客户所占的比例,即精确率为0.8447,也是这6中算法中最高的;所有的不违约风险客户中,我们预测正确的客户样本数量所占的比例,即召回率为0.9548;精确率与召回率会出现矛盾的情况,此时利用F1值去评判,Lasso-CatBoost算法的F1值为0.8964,同样也是六者中最高的;AUC值表示ROC曲线下方的面积大小,AUC越大,越接近1,预测效果就越好,与其他算法相比,Lasso-CatBoost算法的AUC值最高,说明其预测效果最好。
从使用的特征个数来看,本文提出的Lasso-CatBoost算法仅用了17个特征,其余五种算法均用了23个特征,但无论用准确率、精确率、召回率、F1值还是AUC值作为评价指标,我们提出的算法都比其他算法在信用风险评估方面表现得更好。
ROC曲线用来评价分类器的性能,也是一个评判分类算法好坏的一个重要指标。通过测试分类结果可以计算得到TPR和FPR的一个点对。ROC曲线越靠近左上方,离得越近,说明分类效果越好。纵轴TPR表示所有实际正例中,能预测为正例的比例。横轴FPR表示所有实际负例中,错误的预测为正例的比例。
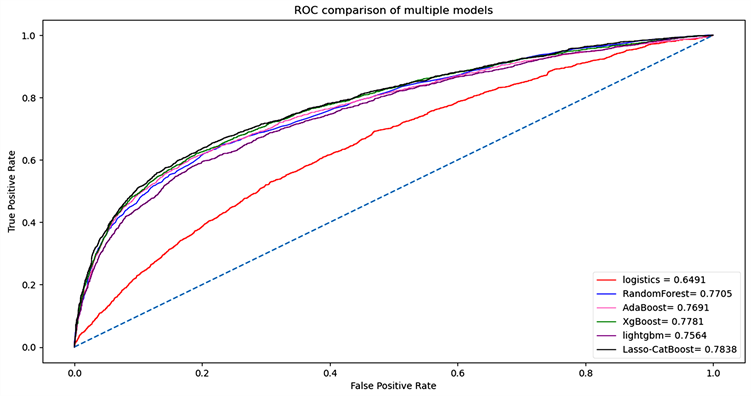
Figure 5. ROC curve comparison of each algorithm
图5. 各算法的ROC曲线对比图
如图5所示,6种算法的ROC曲线均在0.5阈值的左上方,说明均是分类效果较好的分类算法。但是由TPR和FPR形成的点对构成的ROC曲线中,Lasso-CatBoost算法最靠左上方,说明所有实际就是正例,也能预测为正例的比例最大,而所有实际就是负例,然而错误得预测为正例的比例较小。越靠近左上方,分类器越完美,显然Lasso-CatBoost算法的分类效果最优,相比其他五种算法,能更加有效的预测银行客户违约情况。
4. 总结
本文将Lasso算法与CatBoost算法融合在一起,提出了一种新的算法:Lasso-CatBoost算法。为了验证该算法在分类模型上的简单有效性,文章基于某信用数据集,与logistics回归算法以及RandomForest、Adaboost、XGBoost、LightGBM等集成分类算法相比研究,通过几种重要性指标的结果对比,说明本文提出的Lasso-CatBoost算法在该数据集上所构建的个人信用评估模型是简单有效的,提高了评估预测风险的能力,对信用贷款风险起到有效的防范作用。除此之外,本文还得到以下结论:
通过对特征重要性的分析得出2005年9月的还款情况排第一、客户个人及家庭信用额度排第二、2005年9月的账单记录是第三,再对类别型变量进行分析后得出贷款的男性女性中,男性违约率高于女性违约率、而研究生及以上学历人群的违约率略高,因此并不是学历越高,违约率越低、已婚人群的相比之下违约率较高、年轻人的违约率较高。给出的实际性建议为银行在考虑是否给客户发放贷款时,应着重关注这几个变量因素。
在建立模型时,选择正确及合理数量的变量是至关重要的,本文利用Lasso算法进行变量筛选,对变量进行降维处理,挑选相对重要的变量,剔除系数为零的变量,最终剔除了6个系数为零的变量,剩余17个作为Lasso-CatBoost算法的输入值。其余5种分类算法均用23个变量建立模型,相较而言,本文提出的Lasso-CatBoost算法在该数据集上的分类效果最佳。
AUC值是金融风控中常用的评估指标,因此模型的性能评价以AUC值为主,Lasso-CatBoost算法模型的AUC值为0.7838,是6种算法中最高的。除了AUC值,还通过常用的评估指标:准确率、精确率、召回率和F1进行验证,Lasso-CatBoost算法模型准确率为0.8268,精确率为0.8447,召回率为0.9548,F1值为0.8964,Lasso-CatBoost算法在这些指标上相比其他算法模型都是最好的。
本文验证了所提出的Lasso-CatBoost算法在个人信用评估方面是有效的。而如今金融信贷发展迅速,信用数据量大、数据维度高,因此个人信用评估研究不能仅仅局限于现有的数据集上,应该对更广泛的数据集进行研究。
致谢
衷心地感谢我的研究生导师李东喜老师以及统计所有老师,在三年的研究生学习中,认真的指导;在生活中,也会给出很多关爱,让我在漫漫学涯中感受到了温暖和肯定。其次,感谢给予转载和引用权的文献及研究思想和设想的所有者们,正是借助你们的肩膀,我才能够更好地完成论文的撰写。