1. 引言
一个国家或者地区的经济发展状况一般用GDP来表示,通过GDP可以掌握一个国家或者地区的经济发展状况,保罗安东尼·萨缪尔森和诺德豪斯曾经将其称为“世纪最伟大的发明之一”。而江苏省的经济发展水平一直都处在国内经济发展的领先地位,其GDP总值更是仅次于广东省,居于第二位。江苏省作为经济发展大省,其每年都为我国GDP的增长贡献了绝大部分,因此分析江苏省GDP的发展状况,并对其发展趋势进行预测显得尤为重要。本文从江苏省统计年鉴上查找1975~2020年GDP数据,对其进行平稳性检验、异方差性检验以及纯随机性检验,之后对序列拟合ARIMA模型,并且利用拟合的模型预测江苏省2016~2020年的GDP数值,并将预测值与实际值进行比较,计算相对误差,以此检验所构建模型的准确性。
2. 文献综述
随着经济的快速发展,国内外学者对GDP发展规律展开了详细的研究。通过梳理文献发现预测GDP的方法大致可以分为四类,分别为:时间序列分析、回归分析、灰色预测和神经网络。
首先关于时间序列分析的研究。瞿海情和何先平(2021)建立1978~2019年湖北省GDP数据的ARIMA(p,d,q)模型,并利用得到的模型进行短期预测,首先利用所建立的模型将2018年以及2019年湖北省GDP数值预测出来,然后和实际值进行比较,发现该模型对数据的拟合程度较好,说明时间序列模型对于GDP的短期预测效果非常好 [1]。潘典雅(2021)和瞿海情以及何先平的思路一样,对吉林省1993~2017年的GDP数据建立ARIMA模型,只是潘典雅在建立时间序列模型之前,首先对GDP数据进行了一个平稳化处理以及检验,并且对模型中出现的参数不仅进行了估计而且还进行了适用性检验 [2]。陈玉霞(2021)也是利用时间序列模型对GDP进行预测,但是不同于潘典雅所采用的年度GDP数据,陈玉霞所采用的是2003年第一季度~2019年第二季度共66个季度的季度GDP数据,因此根据数据的特点,陈玉霞所建立的是SARIMA模型,之后运用拟合的最优模型SARIMA预测了下一年的GDP数值,对比发现利用此模型对GDP进行预测准确性很高 [3]。
其次关于回归分析的研究。除了运用时间序列模型对GDP进行预测之外,还有很多学者借助回归分析法进行GDP预测,并且不同学者所利用的回归方法也不相同。刘浏(2017)在甘肃省统计年鉴中搜寻了其1978~2015年的人均GDP数据,对其建立了一元线性回归模型,并利用所建立的模型预测了“十三五”期间甘肃省GDP以及人均GDP指数,研究发现一元回归模型对于GDP预测效果较好 [4]。魏乐航(2020)基于1996~2019年孝感市GDP数据,对其建立自回归时间序列模型,并预测未来5年孝感市GDP数值,发现孝感市未来5年的GDP会呈现稳步上升的态势 [5]。魏乐航所使用的自回归时间序列模型其实是将回归方法引入时间序列模型的一种方式,而李永娣(2021)不仅使用了ARIMA模型,还使用了主成分回归模型对河南省GDP总量以及增速进行预测,结果显示时间序列模型与回归模型对GDP的预测有不同的作用,时间序列模型更加侧重于对总量进行预测,而回归模型则更加侧重于对引起GDP增加的因素进行分析 [6]。
然后关于灰色预测的研究。石萍和唐俊(2015)基于2004~2012年包头市GDP数据,运用灰色预测法预测包头市GDP数值,并通过检验发现此模型的有效性以及合理性 [7]。之后王传会等(2015)在普通灰色预测模型的基础上,为了在模型中引入经济系统中国的突变现象,将泛函理论引入到灰色预测模型中,之后又运用贝叶斯网络推理技术,建立了灰色泛函预测GFAM(1,1)模型 [8]。而田梓辰和刘淼(2018)不同于王传会引入泛函理论,而是在灰色GM(1,1)模型的基础上,引入改进的朗格朗日插值函数得到灰色GM(1,1)模型,并利用此模型预测新疆近十年的GDP数值,研究表明利用此模型预测GDP的准确性 [9]。
最后关于神经网络的研究。李南(2017)建立江西省2000~2016年GDP的BP神经网络模型,并对2018年GDP数值进行预测 [10]。然后晏荣堂(2018)在李南的基础上,利用遗传算法优化的神经网络对GDP进行预测,得到了一个更加准确的GDP预测模型 [11]。朱青和周石鹏(2021)考虑到传统的时间序列方法预测GDP时,对数据的要去较高,只有当GDP数据为序列平稳时才可以使用,为了解决这个难题,朱青和周石鹏利用机器学习算法Random Forest选取影响GDP增长的重要变量,之后利用深度学习当中的LSTM神经网络预测GDP的增长,得到一个预测精度更高的预测模型 [12]。
通过文献梳理可以发现学者们在对GDP的分析预测上虽然方法各异,但是都取得了非常理想的效果。很多学者通过灰色预测理论以及神经网络分析理论对GDP进行预测,但这两个方法不论是理解上还是建模难度上都比较大,而时间序列模型不仅理解容易,建模轻松,而且在对GDP预测效果上并不比前两种方法差,因此本文考虑选用时间序列分析模型对江苏省GDP数据进行预测分析。
3. ARIMA模型的建立与预测
3.1. 数据来源
本文所选取的数据是1975~2020年江苏省GDP数据,是一个年度GDP时间序列数据,所有的数据均可以从江苏省统计局官方获得,本文在进行建模时,江苏省统计局官网公布的最新的统计年鉴为《2021年江苏省统计年鉴》,因此2020年为目前所获得的最新数据。
3.2. 原时间序列的平稳性检验
首先将1975~2015年的江苏省GDP数据录入到软件R当中,首先画出该序列的时序图,可见图1,对其平稳性进行初步的判断。从图中可以非常明显的看出,江苏省GDP数据具有非常明显的上升趋势。接着利用ADF检验原序列的平稳性,结果显示
,因此不能拒绝序列非平稳的原假设,故可判定该序列是非平稳的。
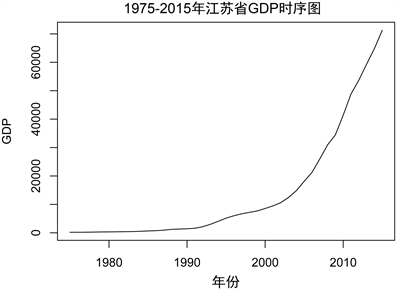
Figure 1. Sequence chart of GDP of Jiangsu Province from 1975 to 2015
图1. 1975~2015年江苏省GDP时序图
3.3. 数据处理
3.3.1. 数据预处理
第二部分通过画时序图以及ADF检验已知该原始序列是非平稳的,因此下面利用ADF检验对一阶差分后的序列进行平稳性检验,检验结果可见表1,从检验结果中可以看出
,同样的不能拒绝一阶差分序列为非平稳的原假设,故判定此序列一阶差分后为非平稳的。

Table 1. ADF test results of original sequence and first order difference sequence
表1. 原序列及一阶差分序列的ADF检验结果
由于原序列以及一阶差分序列都非平稳,因此对序列进行二阶差分处理,并利用ADF检验对两阶差分后的序列进行平稳性检验,下表2为单位根检验结果。从结果表中可知,若给定显著性水平
,任一模型都有
,因此可以得出二阶差分后的序列是平稳的结论。
Table 2. ADF test results for second order difference sequences
表2. 二阶差分序列的ADF检验结果
3.3.2. 序列纯随机性检验
平稳性检验以及异方差检验结束后,下面需要对序列进行纯随机性检验,由于所选取的数据仅仅是1975~2020年共46年的江苏省GDP数据,进行二阶差分后会损失两个数值,因此检验的序列仅为44个,作为一个时间序列数据,相对而言比较短,因此这里的纯随机性检验仅检验到滞后6期,检验结果可见表3。从检验结果表中可以看出,若给定显著性水平
,不论是滞后3期还是滞后6期,其对应的p值都小于
,故有充分的理由拒绝原假设,进而进行模型识别与定阶的任务。
3.3.3. 模型的识别与定阶
为了建立正确的时间序列模型,首先需要知道模型的阶数,方法是通过二阶差分后的自相关图以及偏自相关图进行判断,自相关以及偏自相关的检验结果可见图2。
Table 3. Pure randomness test results
表3. 纯随机性检验结果
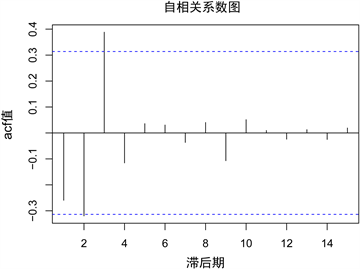
Figure 2. Sequence autocorrelation and partial autocorrelation graphs
图2. 序列的自相关以及偏自相关图
从acf图以及pacf图可以看出,自相关图3阶截尾,而偏自相关图2阶截尾,因此可以拟合模型ARIMA(2,2,3)、ARIMA(0,2,3)、ARIMA(2,2,0),由于以上模型均通过了残差的白噪声检验,因此用上述任一模型对江苏省的GDP进行预测都是合理的,但是为了选择最优模型预测江苏省GDP走势,下面借助信息准则AIC辅助,判断三个模型的拟合结果可见表4。
Table 4. Comparison of fitting results of different models
表4. 不同模型拟合结果比较
根据AIC指标数值最小的原则,最优的拟合模型是ARIMA(0,2,3),通过观察acf图以及pacf图可以看出,acf图滞后2阶和滞后3阶显著不为0,只有滞后1阶是显著为0的,同理,pacf滞后1阶显著为0,滞后2阶显著不为0,因此可以建立疏系数模型ARIMA((p1),2,(p2,p3)),通过R软件得到疏系数模型所对应的AIC准则值为625.19,小于ARIMA(0,2,3)模型的AIC值,因此采用ARIMA((p1),2,(p2,p3))模型更优,所得到的最优模型为:
3.3.4. 模型的显著性检验
最后一步检验模型的显著性,检验结果可见图3,检验结果显示残差序列是白噪声,因此可以说明此模型拟合较优,将序列的所有信息都充分提取到。
3.3.5. ARIMA模型的预测
下面利用上述得到的拟合模型,预测江苏省2016~2020年的GDP数据,之后用实际值与预测得
到的拟合值进行比较,并且设定误差公式为:
,其中test代表真实值,fore代表预
测值。
Table 5. GDP forecast results of Jiangsu Province from 2016 to 2020
表5. 2016~2020年江苏省GDP预测结果
从表5中可以看出,将2016年至2020年这五年数值带入到预测模型中,所产生的预测误差都在5%之内,因此可以说明该模型用于拟合江苏省GDP数据的合理性。图4展示的是江苏省GDP未来的走势,从图中可以非常明显地看出,江苏省GDP在未来仍然将保持高速增长态势。

Figure 4. GDP forecast chart of Jiangsu Province
图4. 江苏省GDP预测图
4. 结论与展望
4.1. 结论
本文建立了江苏省1975~2020年的ARIMA疏系数模型,通过时序图发现GDP原序列非平稳,故将其进行一次普通差分,通过时序图发现差分一次的GDP数据仍然不平稳,故对其进行二阶差分处理,通过图示法以及ADF检验得出二阶差分后的数据平稳的结论。其后观察两次差分序列的acf以及pacf图特点,对模型进行定阶处理,比较各个可能的拟合模型,基于AIC准则最小化原理选出最优拟合模型,即疏系数模型ARIMA((p1),2,(p2,p3)),并利用拟合模型预测江苏省2016~2020年GDP数值,并将实际值和预测值进行比较,并计算二者之间的误差,结果这五年的预测值与真实值之间的误差均较小,说明模型的拟合效果较好。最后通过图示法展现江苏省GDP增长趋势,发现江苏省近几年的GDP一直保持稳定的速度持续上涨,说明江苏省的发展态势较好。
4.2. 展望
本文在研究江苏省GDP发展特征时,采用的1975~2020年的年度数据,是从一个比较宏观和笼统的方面对江苏省GDP数据进行研究,其实还可以查阅江苏省GDP月度数据,更加细微地研究其增长变化情况。此外本文采用的是时间序列模型对GDP进行预测,而关于预测的模型还有很多,比如灰色预测模型,神经网络模型等,后续工作还可以利用这些模型对江苏省GDP数据进行预测分析,并且比较选择最优预测模型。