1. 引言
命名实体识别(Named Entity Recognition, NER)是信息抽取的重要环节之一,其目的是从文本中识别出命名实体的边界并判断其所属的实体类型。传统实体识别任务主要集中在人名、地名、机构名的识别上,但是,由于机构名具有罕见词多、结构复杂、名称差异性较大等问题,和其他类别相比,识别准确率较低 [1]。
机构名在日常生活中覆盖面极广且划分领域细致,通常分为政府机关、医疗机构、科教服务场所、餐饮等多个类型,因此,对机构名进行细粒度实体识别更符合现实世界的知识体系。通过在已有类别基础上进行进一步的类别划分,使得从文本中抽取出来的实体有更为详细的定义,为下游兴趣点搜索、意图识别、面向导航系统等实际任务提供更有力的支撑。
命名实体识别主要有基于规则的、基于统计的和基于深度学习的方法。基于规则的方法通过分析实体的构成特点和上下文结构,人工构造大量的特定规则,再从语料中匹配符合这些规则的实体,人工成本高,可移植性低。基于机器学习的常见方法有隐马尔可夫模型和条件随机场 [2] 等,文献 [3] 采用规则与条件随机场相结合对中文地名、机构名进行识别并取得了不错的效果。但是,这种方法对于语料库的依赖较大,而且需要语料具有一定的特征结构 [4]。
近年来,基于神经网络的方法在实体识别任务中取得了较大的成功,文献 [5] 用双向长短时记忆网络BiLSTM自动学习文本的词级和字符级表示,在CoNLL-2003数据集上取得了F1值90.94%的先进水平成绩,该方法能够自行从数据中学习出文本序列的特征,不需要人工设计规则模板。相比于英文语系,中文词边界不明显,由于分词所产生误差将会影响实体识别的效果 [6],因此,中文命名实体识别可以转化为字符级别的序列标注任务。文献 [7] 表明,基于字符级别未登录字识别效果较词级别提升了11.05%。基于字符的输入虽然避免了引入噪声,但同时丢失了词汇信息、时序信息等特征,无法表示中文语境种的一词多义现象。文献 [8] 将分词模型和实体识别模型进行联合训练,实验证明,关注词汇可以有效提高对社交媒体信息这类不规则文本的实体识别效果。随着词嵌入模型迅速发展,ALBERT、ELMO [9]、BERT等预训练语言模型被运用到序列标注领域,文献 [10] 提出了基于BERT嵌入的中文实体识别方法,在人民日报语料上取得了94.86%的F1值。文献 [11] 基于自建语料,对中文专业术语进行识别,将基于统计文本特征模型、word2vec字嵌入和BERT预训练的字嵌入进行对比,证实基于BERT的字嵌入向量能更好地表征字符的语义和语句特征。此外,BERT模型也被成功应用到地名 [12]、医药 [13] [14]、食品 [15] 等领域的实体识别任务之中。
目前,考虑到机构名细粒度实体识别存在的问题:① 部分实体长度较长,上下文信息存在远距离依赖。② 一词多义现象明显,罕见词较多。③ 细粒度分类后存在实体嵌套情况,例如“王府井商场停车场”错误分词会导致实体被切分,类型判断错误影响模型识别准确率。本文采用一种基于BERT-BiLSTM-CRF的实体识别模型,该模型选择BERT作为获取机构名特征向量的预训练方法,结合BiLSTM对上下文信息的记忆能力和CRF对标签的约束能力,在完整保留语义信息的基础上,提升模型对中文命名实体的识别准确率,并在完成实体识别任务的同时完成了实体分类问题。
2. 机构名语料集特点
本文实验使用的数据来自北京市高德地图POI数据,关注的是POI的名称,即一句话中是否含有POI名称并判断其所属的品类。根据实际应用需求结合POI数据中标签划分类型,本文将传统领域的机构名进一步细粒度划分成了12个类别,分别为交通设施服务、休闲服务、住宿服务、公司企业、医疗服务、政府机构、生活服务、社会团体、科教服务、金融服务、风景名胜和餐饮服务。数据集统计情况见表1。

Table 1. Statistical table of the number of organizations and entities in the data set
表1. 数据集组织机构实体数目统计表
不难发现,现实生活中对机构名的实体类别划分通常是细粒度的。当用户搜索“肯德基(王府井大街店)”通常是对“王府井大街附近的餐饮信息”感兴趣,而在常规NER任务中通常粗粒度的划分为“地名类”或者“机构名类”,这并不适用于用户的实际需求,因此,对机构名进行细致的分类可以更贴切的向用户推荐合适的信息。
此外,机构名的语料表述存在着较大的复合性和嵌套性,例如“全聚德朝阳旗舰店”、“肯德基(王府井大街店)”等餐饮服务实体词,可细化为餐饮店名称、餐饮店所在地、餐饮店规模等复合型实体词;或者在表述时具有明显的不同类别实体嵌套特点,如“天安门停车场”、“故宫公交站”等实体前半部分属于风景名胜而后半部分属于交通设施服务,其实体词含义和类别需要结合上下文来分析理解。
同时,机构名表述的结构也多种多样,如“快递驿站”表述为“菜鸟驿站”、“快递点”、“菜鸟”等;部分机构名完全不具有指代作用,如“蚝先生”、“地磅”、“赛科龙”等;同时机构名可能参杂数字、字符及特殊符号,如“colala2号店”、“.com服务中心”等。
综上可以看出,机构名语料在实际应用中存在细粒度类别划分、复合性和嵌套性强、语言表述不规范等特点,给识别及划分类型过程带来巨大的困难。
3. 基于BERT-BiLSTM-CRF的机构名实体识别方法
针对机构名实体对象的特点,本文采用BERT-BiLSTM-CRF模型的实体识别方法解决机构名识别与细粒度划分问题。
3.1. BERT-BiLSTM-CRF模型
本文采用的BERT-BiLSTM-CRF模型分为三部分,具体模型结构如图1所示。
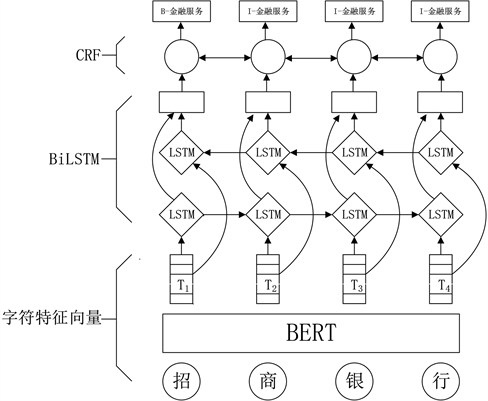
Figure 1. BERT-BiLSTM-CRF model structure diagram
图1. BERT-BiLSTM-CRF模型结构图
假定输入语料
,其中,xi表示语料X中第i个字。模型第一层利用预训练语言模型BERT获取语料X的字符级别特征向量序列
,其中,Ti为字符xi所对应的字符特征向量。在输入阶段,为X中的每个字符xi依次叠加句嵌入Eis、字符嵌入Eic和位置嵌入Eip形成字向量Ei,将其送入模型得到具有全局语义信息的输出序列T。
模型第二层为BiLSTM层,由正向和反向的LSTM组成。第一层获取的n维字符向量作为双向LSTM神经网络各个时间步的输入,经正向LSTM后输出的隐状态序列为,经反向LSTM后输出的隐状态序列为,然后将前后向信息拼接得到完整的隐状态序列
。通过线性输出层将完整的隐状态序列映射到k维(k维为标签类别总数),从而得到特征矩阵Pn×k,其中pij表示字符i被标注为标签j的概率。
模型第三层CRF层接受BiLSTM输出的特征矩阵Pn×k,同时引入转移得分矩阵,通过维特比算法在所有备选标签序列中求得全局最优序列。最终识别“招商银行”应被标注为“金融服务”。
3.2. BERT模型
在进入神经网络训练之前,需要先将语料中的文字表示成向量的形式作为模型的输入。与one-hot、Skip-gram、Word2Vec等静态词向量表示不同,BERT是一种基于微调的双向多层Transformer编码器,它可以更好地捕捉当前字符在真实语境地上下文信息,模型结构简图如图2所示。
由于中文分词技术在准确率方便存在各种问题,错误的分词会误导模型的训练效果,因此,本文BERT模型使用字符级表示作为输入。对于每一个字Wi其输入向量Ei是由三个嵌入向量相加组成的:字符级向量(Tokens_tensor)、位置向量(Positin_tensor)和句向量(Segments_tensor),具体如图3所示。
通过查找字符表,将输入中的字符转化为字符向量;位置向量用于标记每个字符在输入序列中所处的位置,为字符添加时序信息;句向量的作用是为语料进行分句,用[CLS]和[SEP]表示一个句子的开始位置和结束位置,如不考虑上下句之间的关系,句向量可忽略不计。与单纯的静态向量相比,BERT模型输出融合了全局语义信息的特征向量,从而可以解决中文表达中“一词多义”的问题,这对机构名的实体分类会有很大的帮助。因此,本文采用BERT预处理模型生成字向量,提高字向量的质量,以期获得等好的分类效果。
3.3. BiLSTM模型
组织机构的命名具有名称多样性、实体长度较长、实体嵌套等问题,在进行序列标注的过程中往往需要利用上下文信息来提高标注效果。LSTM全称是Long Short-Term Memory,即长短时记忆网络,它可以有效学习长期依赖信息。LSTM模型结构如图4所示。

Figure 3. Input vector composition of Bert model
图3. Bert模型输入向量构成
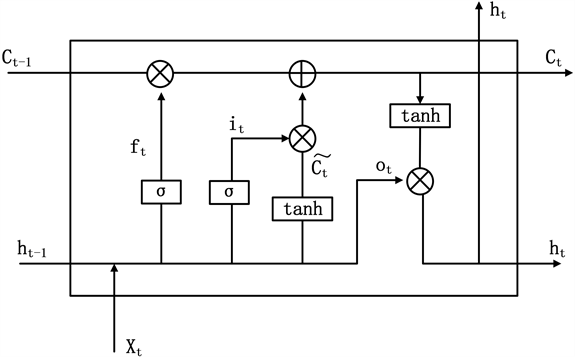
Figure 4. LSTM model structure diagram
图4. LSTM模型结构图
相较于传统循环神经网络,LSTM主要增加了遗忘门ft、记忆门it和输出门ot三个门控单元来控制输入和输出,各个门之间的计算过程如下:
(1)
(2)
(3)
(4)
(5)
(6)
其中,
代表sigmoid函数,tanh代表双曲正切激活函数,
,
,
,
是各个门的权重,
,
,
,
是各个门的偏置项。由于LSTM只能处理一个方向传来的信息,因此,本文采取的BiLSTM模型是一个双向循环神经网络,由前向LSTM和后向LSTM组合而成,每个时刻BiLSTM模型从自左往右
和自右往左
两个方向来记忆上下文信息,然后将双向网络输出的隐状态拼接得到t时刻BiLSTM的输出
,各时刻输出构成完整的隐状态序列
,通过线性输出层将完整的隐状态序列映射到s维(s维为标签类别总数),从而得到特征矩阵Pn×k,其中,pij表示字符i被标注为标签j的概率。
3.4. CRF算法
BERT与BiLSTM层学习到的标签序列只受字符本身及其上下文特征的影响,仅仅依据打分值的高低进行最佳标签的选择,这个结果并不准确。在BIO标注模式中,标签之间存在着一定的依赖关系:1) 句子只能以标签“B-”或“O”开始;2) 标签“B-X1、I-X2、I-X3”中X1、X2、X3应该属于统一类别。条件随即场(Conditional Random Field, CRF)可以通过学习标签之间的转移规则获取全局最优解,进而降低预测结果中出现非法序列的概率。
CRF层的输入为BiLSTM层输出的特征矩阵Pn×k和一个随机初始化的转移矩阵Ak×k,其中k表示标签类别的个数,n表示输入序列的长度。
其可能输出标签序列Y为:
(7)
输入序列X得到输出序列Y的分数计算公式为:
(8)
式中,代表第i个字符被预测为标签yi的概率,代表标签yi-1转移到标签yi的概率。最终选取全部可能的标签序列Y中得分函数值最大的全局最优序列作为输出
(9)
4. 实验结果及分析
4.1. 数据集
本文将细粒度划分后的数据集按照7:1:2划分成训练集、验证集和测试集,数据集统计情况见表2。
Table 2. Distribution of entities in each category in the data set
表2. 数据集中各类别实体分布情况
在获取数据后,需要将数据转化为带标签的格式,本文采用的是BIO标注模式对实体进行标注,标注示例图如表3所示。在该模式中“B”代表实体的开始,I代表实体内部,O代表其他,结合表中的12小类,带识别的小类标签共有25个,例如“B-医疗服务”、“I-医疗服务”、“B-社会团体”、“I-社会团体”、“O”等。
Table 3. Schematic diagram of organization name corpus annotation
表3. 机构名语料标注示意图
4.2. 评价指标
在测试过程中,只有实体边界与实体类别完全匹配时,才判断该实体类型预测正确。由于本实验数据集中的标签具有不平衡性,为了能够客观地衡量模型在各类别上的分类性能,实验主要用F1值作为评价标准,并以准确率(Precision)和召回率(Recall)作为参考:
(10)
其中,F1的值越大,模型的实验效果越好。
4.3. 实验结果
为验证本文构建的BERT-BiLSTM-CRF模型在细粒度组织名识别的效果,分别使用BERT-CRF、BiLSTM-CRF以及CNN-BiLSTM-CRF的三种命名实体识别模型与本文构建的BERT-BiLSTM-CRF模型进行对比实验。实验结果如表3所示。
BERT-CRF:BERT模型在海量文本数据集上进行了预训练,其动态文本表示方法相较于传统静态文本表示方法在文本数据上表现出优异性能示,加入BERT验证其在命名实体识别上的性能。
BiLSTM-CRF:该模型是经典的命名实体识别模型,由BiLSTM层学习输入序列的上下文信息,再通过CRF层对标签之间的转移规则进行约束。
CNN-BiLSTM-CRF:CNN可以学习各级别的输入特征,因此,加入CNN验证其有效性。
通过表4可知,增加了BiLSTM的效果比基于BERT-CRF的实体识别模型F1值略有提升,这是因为部分组织机构名长度较长或存在实体嵌套现象,例“中共共青团拱辰街道建人外语艺术幼儿园支部委员会”等,BERT-CRF会错误的将其标注为“科教服务”而不是“政府机构”。作为经典的实体识别模型BiLSTM-CRF模型的F1值为88.48%,在引入了BERT模型之后,模型F1值提高了3.93个百分点,这说明使用BERT对输入语料进行向量化之后,句子中的字、词表达更为准确,语义信息也更加丰富。CNN可以学习语料间的语义相关性,和BERT具有相似的作用,但卷积核池化层可能会丢失某些输入的局部信息,因此,加入CNN的效果不如加入BERT好。
Table 4. Comparison of experimental results of different models
表4. 不同模型的实验结果对比
4.4. 不同实体实验结果对比
表5列出了不同模型对机构名数据集上各类实体的识别结果。由实验可知,交通设施服务实体在不同模型上的识别率都较高,因为这类组织名称具有较明显的指向性特征(例如:“富恒停车场”、“中山公园停车场”、“天安门地铁站”等)。而休闲服务、社会团体和风景名胜的分类效果均低于0.88,部分原因是该类别的实体名称形式多变,神经网络难以捕捉到其特征信息;语料标注存在部分的错误和混乱,例如“故宫博物院观众休息厅”被标注为“生活服务”而“故宫博物院”被标注为“风景名胜”,高度相似的实体名称却被标注为不同实体,影响实验分类效果。由表中可以看出,BERT-BiLSTM-CRF在各类实体上的识别效果都较好。
Table 5. Recognition effect of different models on various entities (F1 value)
表5. 不同模型在各类实体上的识别效果(F1值)
5. 结论
本文构建了机构名数据集,标注并划分了不同类型的12类实体,共计67,224个,在此基础上完成细粒度机构名的识别分类。本文构建的基于BERT-BiLSTM-CRF的神经网络模型,利用BERT解决中文文本特征表示时存在的一词多义问题,结合BiLSTM充分学习语料的上下文信息,通过CRF方法约束标签转移规则,最终提取全局最优的标注序列,完成机构名的细粒度实体识别分类任务。最后,在构建的数据集上对比了其他三种实体识别模型,进行实验验证。实验结果表明,本文采用的BERT-BiLSTM-CRF模型在不同实体类型上都可以保持较高的准确率。
参考文献
NOTES
*通讯作者。