1. 引言
考虑如下非参数回归模型
, (1)
其中
为固定设计点,
为被解释变量或响应变量,
与
分别为未知的均值函数和标准差函数,
为独立同分布的随机误差序列,且
,
,
。
近些年来,国内外学者对非参数回归模型做了大量的研究 [1] - [7]。渐近分布作为估计量大样本性质中的一个重要方面,也引起了一些学者的兴趣。秦永松(1991) [8] 基于加权核估计得到了均值函数的估计量,并研究了其导数的渐近分布;Liang与Jing (2004) [9] 采用加权核估计的方法,基于负相关序列研究了非参数回归模型中未知函数估计量的逐点一致收敛性与渐近正态性;Jin等(2014) [10] 研究了一步Newton-Raphson估计和局部轮廓似然估计,并给出了基于两种方法的估计量的分布;Alharbi与Patili (2018) [11] 提出对响应变量和残差的乘积进行平滑处理,并研究了基于此方法得到的方差函数估计量的渐近分布;Li和Lin (2020) [12] 在没有独立性假设的情形下,推导出了误差方差
的最佳半参数效率约束,并建立了基于残差的
有效估计量的渐近正态性。
本文对非参数回归模型中基于样条方法的均值函数估计量和方差函数估计量的分布问题进行研究,并通过数值模拟验证效果。
2. 估计量及主要结论
根据文献 [7],将区间
进行包括两端点的
等距分割,结点序列为
,
构造相应的v次样条空间
,其基函数记作
。设
,又令
,
则均值函数
的样条估计为
, (2)
这里
为能使
最小化的参数向量,
,它的最小二乘估计为
,其中
,
。
记残差
,令
,
,则方差函数
的基于残差的样条估计为
, (3)
其中
为使得
最小化的参数向量,
,它的最小二乘估计为
。
2.1. 均值函数估计量的分布
本文假定误差序列
来自标准正态总体,即
。不妨记
,
,
,
则模型(1)可简记为
, (4)
其中
。
因为
与
分别为常数向量和常数矩阵,又根据期望与方差的性质可知,
。
定理1均值函数
的样条估计量
服从均值为
,方差为
的正态分布,即
,
其中
。
证明:根据(2)式知,要证
的分布,只需证
的分布,又因为
,那么有
,
故有
。
2.2. 方差函数估计量的分布
本文记
表示随机变量序列X与Y渐近同分布。接下来讨论方差函数估计量
的渐近分布。
定理2方差函数
基于残差的样条估计量
与
渐近同分布,即
,
这里
。
证明:根据(3)式,要证方差函数估计量
的分布,只需证
的分布。
因为
,
则有
,
即
。
由
一致收敛到
(见文献 [7] 中定理1)且
是正态随机变量,可知
,
即
。
因为
为相互独立且服从标准正态分布的随机误差序列,故有
,
因此,要求方差函数估计量
的渐近分布就是求服从卡方分布的独立随机变量的线性组合的分布。根据文献 [13] [14] 的结果,尝试用单个
变量的线性函数近似n个相互独立的
变量的线性组合。
首先,考虑用
作为
的近似分布。采用一、二阶矩拟合的原则选取
,即由方程
确定。从而
应满足方程
解得
。
考虑到
变量的自由度为正整数,故将d修正为
,
这里
表示不超过x的最大整数,若
,则取
。
再用
来近似
的分布,采用上述方法得到
,
于是,可用
作为
的近似。
3. 数值模拟
考虑模型(1),其中
(5)
这里
。
对模型(5)进行蒙特卡罗模拟,利用三次B-样条基函数估计未知均值函数
,基于残差估计方差函数
,并在AIC准则下自动选取等距结点数。
3.1. 均值函数估计量的模拟
为验证理论分布效果,使用MATLAB软件进行模拟运算,选取显著性水平为
,具体步骤如下:
第一步,根据模型(5),计算出
与
;
第二步,生成N个服从
的随机数;
第三步,基于样条方法,通过蒙特卡罗模拟产生N个均值函数的估计值
;
第四步,在给定置信水平下,检验第二步与第三步产生的随机数与均值函数估计值是否来自于同一分布;
第五步,对上述四步进行多次重复模拟,分析所得结果。
图1绘制了
处在
时的直方图和概率密度函数曲线图。
由图1可见,各点处拟合的均值函数的直方图与概率密度函数曲线呈倒U型,直观地可以认为各点处拟合的均值函数估计值来自于正态分布。进一步地,对各点处的均值函数估计量的分布与正态分布进行Two-sample t-test检验,并分别循环模拟
次,检验的P值如表1所示。
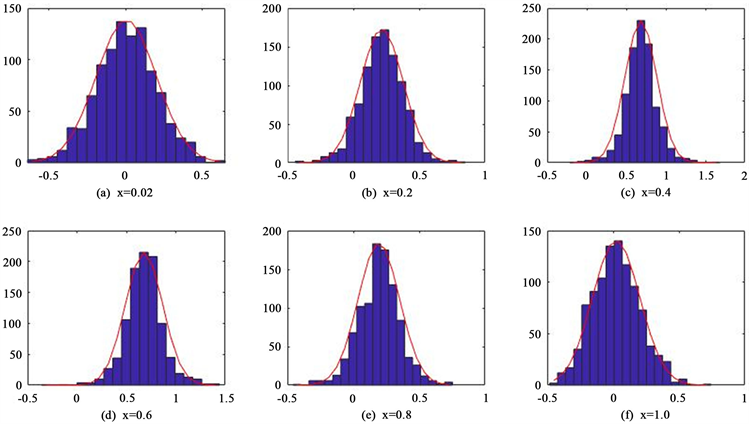
Figure 1. Histogram of the estimates at each point of the mean function and its probability density function curve
图1. 均值函数各点处估计值的直方图及其概率密度函数曲线

Table 1. The P-values of the Two-sample t-test-test for the mean function
表1. 均值函数Two-sample t-test检验的P值
由表1可知,当
时,P值均大于0.05;当N较大时,各点处的P值均大于0.05,说明在给定的显著性水平0.05下,应该接受原假设,即认为检验数据服从正态分布。
3.2. 方差函数估计量的模拟
检验步骤如下:
第一步:依据模型(5)给定x值,计算a,
与
;
第二步:随机生成N个服从
的随机数;
第三步:基于残差样条方法,通过蒙特卡罗模拟生成N个方差函数
的估计值;
第四步,在给定置信水平下,检验第二步与第三步产生的随机数与方差函数估计值是否来自于同一分布;
第五步,对上述四步进行多次重复模拟,分析所得结果。
图2绘制了
处在
时的直方图和概率密度函数曲线图。
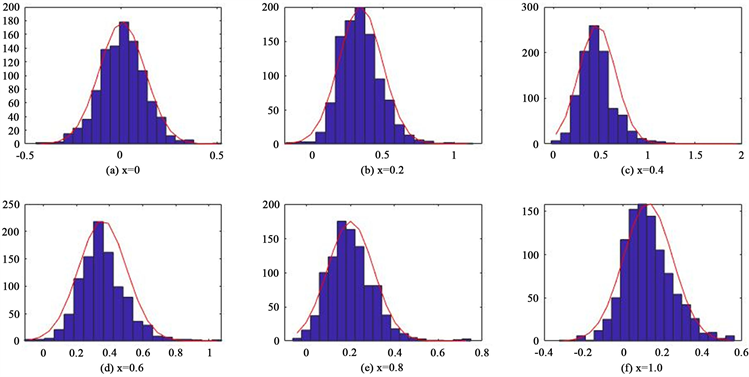
Figure 2. Histogram of the estimates at each point and its probability density function curve
图2. 方差函数各点处估计值的直方图及其概率密度函数曲线
由图2可见,各点处拟合的方差函数估计量的直方图与概率密度函数曲线呈不对称的倒U型,且整体上右偏,直观地可以认为各点处拟合的方差函数估计量近似服从卡方分布。进一步地,对各点处的方差函数估计量的渐近分布与
进行Two-sample t-test检验,并分别循环模拟
次,结果如表2所示。
由表2可知,各点处的P值均大于给定的显著性水平0.05,说明可以接受原假设,即认为检验数据近似服从
。
Table 2. The P-values of the Two-sample t-test-test for the variance function
表2. 方差函数Two-sample t-test检验的P值
4. 结论
本文基于样条方法研究了固定设计下异方差非参数回归模型的均值函数与方差函数估计量的分布,均值函数的估计量服从正态分布,方差函数估计量的渐近分布可由单个
变量的线性函数来近似。模拟结果显示:在给定显著性水平0.05下,分布拟合效果较优。
本文所研究的固定设计下异方差非参数回归模型的均值函数与方差函数估计量的近似分布为生物、医学、地质、经济等领域的研究带来了便利。
基金项目
国家自然科学基金项目(11601126);河南省重点攻关项目(182102210286)。
NOTES
*通讯作者。