1. 引言
我国从改革开放以来就加强了与世界上其他国家的贸易往来,而一个国家在贸易方面总规模的大小是通过进出口总额来衡量的。进出口总额是指实际进出我国国境的货物总金额,包含进口额和出口额两个部分。
一个现象某个统计指标在各个时间上的数值,按其发生的先后顺序进行排列,就得到了某个现象的时间序列 [1]。进出口总额就是一组典型的时间序列数据。文献 [1] 说明了进出口总额的研究很有必要且其经济意义显而易见。文献 [2] 是对英美汇率数据进行分析并对模型进行拟合,最后用Bootstrap样本进行了外区间预测。文献 [3] 通过Bootstrap方法改进季节时间序列单位根检验方法。文献 [4] 是对平稳时序数据的Bootstrap辨识及其改进算法研究。文献 [5] 研究了基于Bootstrap方法的回归分析,给出了Bootstrap残差法与成对Bootstrap法的适用范围及区别。
Bootstrap思想是用已知的经验分布代替未知总体分布、根据原始数据进行统计推断的模拟方法,不需对未知总体作任何假定。通过对己有的样本采取有放回的抽样(每个样本被抽到的概率都相同)来产生伪随机数,从而对总体的特征做出推断。
Block Bootstrap方法是在众多Bootstrap方法中应用最为广泛的一种抽样方法,其主要思路是:将序列按一定的规则分成若干“块”,并以“块”为单位进行有放回重复抽样,从而得到新的Block Bootstrap序列,进而生成新的序列值。
本文通过非参数方法Block Bootstrap方法对进出口总额数据进行有放回抽样并运用参数Bootstrap法进行对系数的估计。结论表明,大样本情形下系数并不总是渐进正态分布的。
2. ARIMA模型
时间序列模型 [6] 包括以下几种:
模型:
(1)
其中
,
保证了随机干扰项为零均值的白噪声序列。
保证了当期随机干扰项与过去序列值无关。
是独立同分布的纯随机项。
模型:
(2)
其中
,
,保证了随机干扰项
为零均值白噪声序列。
模型:
(3)
模型:
(4)
当序列不进行差分时,即差分步数为
时,
就成为了
。
3. 时间序列建模、估计和诊断
本文选择1990年到2018年中国进出口总额一共29个数据。数据来源于《中国统计年鉴》。
首先绘制时序图和相关函数图,以便观察时间序列的基本特征。
图1是中国进出口总额时序图,可以看到该组数据不平稳。图2是增长率的时序图。从图2中我们可以看出,不平稳的情况得到很大改善。因此,之后我们就进出口增长率进行研究。接下来继续绘制增长率的自相关函数图(ACF)和偏自相关函数图(PACF)。
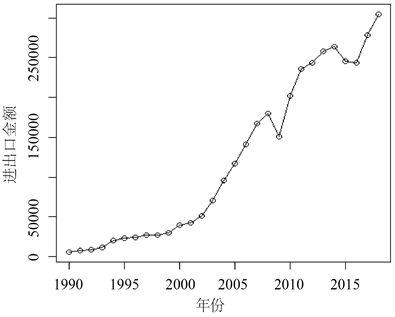
Figure 1. China’s total import and export in calendar years
图1. 我国历年进出口总额
图3和图4分别是增长率的自相关图和偏自相关图。从图中可以看出,自相关图是一阶截尾。偏自相关图是拖尾。所以我们可以根据表1初步判定它是MA(1)模型 [6]。

Figure 2. Growth rate of total imports and exports over the past years
图2. 我国历年进出口总额增长率

Table 1. Order determination principle of ARMA model
表1. ARMA模型的定阶原则
确定好模型后,下一步进行参数估计。这里采用了两种估计方法,分别是条件似然法和精确似然法。结果如表2所示。
Table 2. MA(1) model parameter estimation
表2. MA(1)模型参数估计
对两个模型进行残差自相关诊断。结果如图5和图6所示。
从图5和图6中可以看到,标准化残差基本上在[−2, 2]之间,残差的自相关函数迅速降到两条虚线内,L-B统计量的P值均大于0.5,说明使用MA(1)模型是合理的。因此,我们可以得到最终拟合的模型。其中的Xt为中国进出口增长率。可以得到:

Figure 5. Model diagnosis diagram (CSS)
图5. 模型诊断图(CSS)

Figure 6. Model diagnosis diagram (ML)
图6. 模型诊断图(ML)
条件似然法:
(5)
精确似然法:
(6)
尽管这个模型是合理的,但是两个估计方法对于系数的估计区间都包含0,这意味着我们的系数显著为0。显然不可信。时间序列的理论只是论证了在大样本情况下,模型的系数会渐近正态,但是样本达到何种程度才会渐近正态,是不可知的。所以,我们通常估计的标准误差未必可信,加上我们的样本量不多,所以最后的结果保持怀疑。另一方面,由于Bootstrap法可以通过大量的模拟来得到我们需要的,而不局限于理论,因此接下来通过Bootstrap法来估计标准误和系数估计的置信区间,进而解决系数标准误的理论分布不易得到的结论。
4. 对时序数据模型的标准误进行Bootstrap估计
在对时序数据进行Bootstrap模拟之前,要首先检验残差的相关性。由上面的残差相关图我们得知,数据序列不相关。
下面我们对运用两种不同的估计得到的模型进行Ljung-Box检验来确定残差是否为白噪声。原假设为残差序列是白噪声序列。
Table 3. Ljung-Box test of MA(1) model
表3. MA(1)模型的Ljung-Box检验
从表3我们可以得知,P值均大于0.5,不能拒绝原假设。与自相关图得出的结论一致。下面采用Bootstrap法对系数的标准误进行估计。由于时间序列与随机序列不同,前者存在时间趋势,故不能通过原序列进行构造。因此本文运用块抽样即Block Bootstrap法进行有放回抽样。
定理1 [7]:对于序列MA(1)模型:
(7)
当
时,
依分布收敛于正态分布
进而可得到大样本情形下
的标准误渐进
Bootstrap [8] 估计标准误的基本步骤:
1) 从原始样本中使用块抽样方法进行抽样。这些样本称为Bootstrap样本;
2) 用这些Bootstrap样本建立时间序列模型,并计算
的标准误;
3) 计算所有
的标准误作为Bootstrap估计的
的标准误;
按照上述方法分别模拟1000次,5000次,10,000次,结果如表4所示。
Table 4. Bootstrap standard misestimates and 95% confidence intervals
表4. Bootstrap的标准误估计和95%置信区间
最后画出基于条件似然法的10,000次Bootstrap的系数估计的qq图。qq图可衡量系数分布的准确情形。如图7所示。我们从图中可以看到在大样本情形下系数估计渐进服从正态分布是不可信的。所以,基于大样本正态的推断是不可信的,而基于Bootstrap方法估计的系数和置信区间才更有效。
5. 总结
本文通过对1990~2018年进出口总额数据进行分析,首先由于原数据的时序图可判断数据不平稳,通过观察其增长率的时序图可发现数据增长率是平稳的,通过了平稳性判别。其次通过自相关图和偏自相关图对进出口总额增长率的模型进行判别,利用定阶原则可知是MA(1)模型。运用了极大似然法和条件最小二乘法两种方法给出了它的系数估计值和其置信区间。又通过对其进行残差检验,显示模型拟合得很好。
由于上述方法得到的置信区间包含0,从而其结果不太可信。之后运用了参数Bootstrap方法对系数进行了估计,考虑时间序列数据的相依性,通过运用块抽样方法对其进行有放回抽样,分别进行1000,5000,10,000抽样得到了更大样本情况下,系数并不渐进服从正态分布。从而通过Bootstrap方法得到更可信的结论。因此在小样本情况下,可以用Bootstrap方法进行抽样变成大样本,并对其进行参数估计,与理论方法进行比较,前者获得更准确的结果。