1. 引言
水资源是人类赖以生存的必要资源之一,当今时代,水资源短缺问题日益严重,中国人均水资源占有量仅为世界平均水平的四分之一;同时,随着城市的不断发展,供水管网也变得日益庞大而复杂,因此,对水资源的合理规划和对供水系统的优化调度变得越来越重要,其中最为基础的任务就是用水量规律分析及预测。这一任务是供水基础设施建设、供水调度规划的前提和主要依据,对于水务行业的升级和高质量发展具有重要的现实意义。
掌握用水量规律并建立合适的模型对其进行预测,可以更加精确的把控供水管网每个节点的用水需求,有助于在保证水压、水量的前提下降低供水成本减少用水行为波动对管网水质的影响,提升百姓幸福感的同时推进智慧水务建设,实现供水科学调度和低碳高效精细化管理。
已有学者运用神经网络 [1]、灰色预测 [2]、组合模型 [3]、实证分析 [4]、数据挖掘 [5] 等方法进行城市用水量进行影响因素分析和预测,可以发现影响居民用水量的因素主要分为人为因素和环境因素,其中人为因素相关数据不易获得,仅适合进行结构分析和趋势分析,难以用于预测居民用水量,因此本文考虑根据环境因素分析居民用水行为并进行预测。这些文献在模型的解释性、预测准确度和实时预测方面无法兼顾,而且多以城市或地区为单位进行整体分析,预测行为也以年为单位进行。对于居民小区日用水量分析和预测的相关文献相对较少,王锦涛等学者 [6] 探究了气候因素对居民小区日用水量的影响,并结合数据挖掘方法进行预测;但是近年来新冠肺炎疫情起起伏伏,对居民生活包括居民用水行为也产生了较大的影响 [7],周骅 [8] 对新疫情封控期间特大型城市用水量进行影响因素分析,发现城市供水量受疫情封控影响较大,但尚未有研究考虑疫情对居民用水行为的影响。
本文主要是通过智能水表运行历史数据分析城市居民小区用水量规律,并结合气象数据进行回归、时序建模,建立区域居民小区需水预测模型,利用历史用水数据和实时感知数据预测未来一定周期内小区用水量,以指导实际供水运行工作。该模型结合供水设施水泵和水池调蓄能力,在保障供水水质水压稳定的前提下,可实现区域蓄水平峰调控优化和泵组优化辅助决策,保障管网供水输送的水质稳定和供水设施的节能高效运行。
2. 数据描述
本文使用的数据来自Data Fountain (简称DF平台),该数据集包括多个小区数据,本文只选取其中一个小区进行研究,其他小区可参考本文方法进行分析建模,取得较好的预测效果。数据集中包括日用水量数据和小时用水量数据,另外还有气象变量和疫情相关变量的日数据。本文研究目的是预测该小区日用水量、分析每日小时用水量的规律,并据此预测小时用水需求量。
在分析和建模之前,首先对数据进行适当的处理。本文选择2020年2月1日至2022年6月30日的数据作为训练集进行分析建模,以2022年7月和8月的数据作为测试集来检验模型的预测效果。训练集中共有881行数据,其中18行包含缺失值,由于缺失比例较低,对含删失值的行直接进行删除。另外对其中一些自变量进行适当的变换,具体见表1。除数据集原始变量外,考虑用水量是时间序列数据,将前一日用水量作为一个自变量来反映时间序列趋势。同时考虑时间序列的季节效应加入年份、月份两个变量,另外结合实际生活场景加入假期与否、周内日期序数变量。

Table 1. Table of original independent variables
表1. 原始自变量表
3. 理论概述
随机森林模型由多棵分类决策树模型组合而成,各个树模型独立运作,最终进行汇总得出结果。因此,随机森林方法显著提高了预测精度,是当前最好的算法之一。
具体而言,随机森林通过自助采样技术学习训练多个决策树并进行汇总预测。对于回归问题,从原始训练集中有放回地随机抽取k个样本,对k个样本分别进行训练生成k个决策树模型,最后依据简单平均法将k个决策树的结果进行组合形成结果 [9]。
随机森林模型中有两个至关重要的参数(mtry和ntree)会影响模型的准确性,其中,mtry是在决策树生成过程中内部节点分裂对应的变量个数,该数值在随机森林模型形成过程中始终不变,一般选择使得均方误差最小的值;ntree是随机森林中决策树的数量,虽然决策树越多结果越准确,但决策树过多会增加计算量,所以通常的做法是根据模型内误差变化曲线选择误差稳定时对应的值。
本文首先利用随机森林方法建立模型预测小区日用水量,然后根据日用水量的小时变化规律计算小时用水量的预测值。预测效果的评价标准选用均方根误差(RMSE)和平均绝对百分误差(MAPE),其中,
.
4. 模型分析
对训练集数据建立随机森林模型,共有20个自变量,最小均方误差对应的mtry为16,模型内误差稳定时对应的ntree为200,构造相应的随机森林模型,其方差解释率为61.37%,即20个解释变量对响应变量(日用水量)有关方差的整体解释率为61.37%,尚可接受。
自变量重要性得分图(见图1)中,“%IncMSE”即increase in mean squared error,通过对每个预测变量随机赋值计算模型误差变化,若该变量重要,那么其值被随机替换后模型预测的误差会增大,反映了各解释变量对模型预测效果的影响。“IncNodePurity”即increase in node purity,以残差平方和度量了每个变量对决策树每个节点上观测值的异质性的影响,反映了各解释变量对模型拟合效果的影响。从拟合的角度来看(IncNodePurity),对响应变量影响最大的解释变量为前一日用水量、当前重症人数、当前危重人数、月份、年份;从预测的角度来看(%IncMSE),对预测效果影响最大的解释变量为前一日用水量、气温、气压、月份、当前隔离治疗人数;整体来看,对日用水量影响较大的解释变量为前一日用水量、月份、当前重症人数、当前危重人数、气温、年份、当前隔离治疗人数,而新增死亡人数、风速、风向、新增确诊人数对日用水量的影响都相对较小。
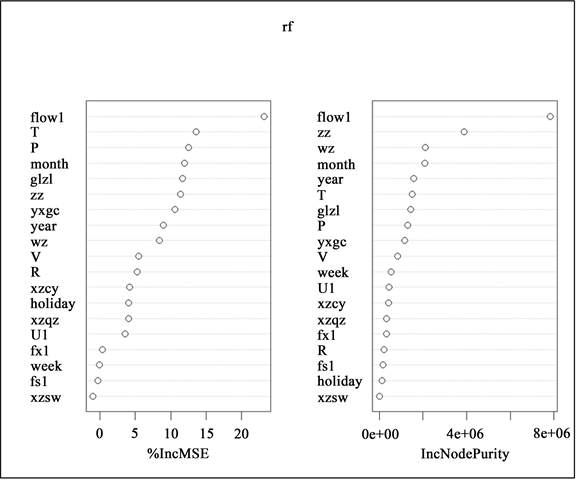
Figure 1. Score chart of the importance of independent variables
图1. 自变量重要性得分图
接下来用构造出的随机森林对测试集进行预测,结果显示均方根误差为81.99,平均绝对百分误差为4.66%,预测效果较好。
分析训练集对应的小时用水量数据发现,每日小时数据变化趋势基本一致,每天晚高峰都出现在22时,工作日全天早高峰出现在早上8时,周末全天早高峰出现在10时,每天各小时用水量占全天用水量的比例基本不变。因此我们用训练集数据计算每天各小时用水量占比,并用随机森林模型得到的测试集日用水量预测值乘以该比例计算测试集中对应的所有小时用水量预测值,最后得出均方根误差和平均绝对百分误差分别为9.2%和15%,较日用水量预测效果有所下降,但尚可接受。
5. 结论
本文模型中将时间序列分析和多元回归结合起来建立的随机森林模型在预测居民日用水量时具有较高的准确度,且有很好的解释性。在此基础上对小时用水量预测的误差也尚可接受。通过模型可以发现,居民日用水量与前一日用水量相关性较强,具有较强的时间序列趋势,气象因素对深圳居民用水量影响较小,相对而言,疫情相关因素影响较大,这种情况可能是由于深圳市气象因素较为稳定导致。因此,对于深圳市供水系统,在气象发生一定变化时,供水量无需做出较大变化,但疫情形势发生明显变化时,建议及时调整供水量。