1. 引言
随着人工智能以及大数据的发展,卷积神经网络在语音识别、图像处理、自然语言处理等领域取得了突破性的进展 [1] [2] [3] [4] [5] 。目前,手写数字识别技术在CPU和GPU平台上已经实现了部署,但是随着卷积神网络的模型层数以及参数数量增加、模型精度的提高,传统的CPU和GPU已经无法满足对手写数字识别实时性的要求,因此如何提高计算速度,是目前的热门研究方向。
近些年来,采用高层次综合语言HLS加速的方法 [6] 得到了快速发展,虽然降低了开发难度但是也存在综合后面积大,具体电路无法修改的问题。在软件平台,采用ARM处理器(Advanced RISC Machines)的嵌入式平台对卷积神经网络进行处理虽然体积小,功耗低,灵活性高,方便部署和迁移 [7] ,对硬件相关知识要求相对较低,但是传统ARM处理器算力低,在一些应用场景中不能满足实时性的要求。
本文采用赛灵思zynq7010系列开发板设计了基于卷积神经网络的手写数字识别系统,采用MT9V034摄像头实时采集图像,将卷积神经网络中浮点数运算以及串行计算慢等问题,利用FPGA并行加速的优势,采用流水线处理的方法对卷积神经网络的卷积层和池化层进行硬件加速设计,将设计后的IP核通过AXI总线与PS端交互,最后在屏幕上实时显示识别后的数字。
2. 本文CNN模型
本文所采用的卷积神经网络模型结构如图1所示。该结构一共有7层,其中第一层和最后一层分别为输入层和输出层,输入层通过采用MT9V034摄像头实时采集的图像作为测试图像,输出层为检测到的识别后的数字并且通过HDMI显示器输出结果。第二四层为卷积层,步长为1填充为0,采用5 × 5卷积核,第二层卷积核的通道为1卷积核的个数为6,第四层的卷积核通道为6卷积核的个数为16。第三五层为池化层,步长为2填充为0,采用最大池化算子。
卷积神经网络模型的运算大部分集中在卷积层 [8] 。所以对卷积神经网络的加速主要是针对卷积层和池化层进行加速。
3. 系统设计
3.1. 硬件环境
本文选用赛灵思ZYNQ7010平台,由两个部分组成其中可编程逻辑(Programable Logic)即FPGA部分包含:逻辑单元(logic cells) 23k、存储单元(block ram) 2.1Mbit、寄存器35k;处理系统(processing system)由一个双核ARM Cortex-A9处理器组成最大频率为666Mhz。Zynq-7000系列平台可以满足复杂嵌入式系统的高新能、低功耗和多核处理能力等要求。
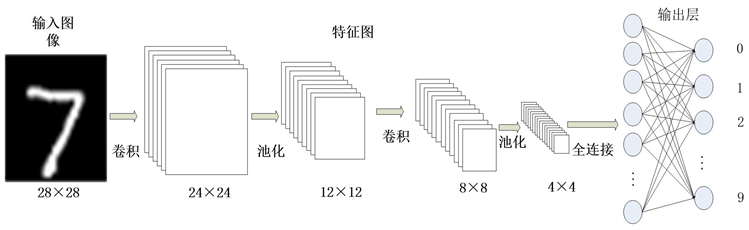
Figure 1. Convolutional neural network model is used in this paper
图1. 本文所用卷积神经网络模型
3.2. 总体系统架构
系统总体设计如图2所示,由MT9V034摄像头完成图像的采集,采集的图像为灰度图像分辨率为640 × 480深度为8 bit并将数据传输到ZYNQ,PL部分接收摄像头采集到的灰度图像,并将其进行二值化处理,然后将处理后的图像数据传输到卷积和池化模块,利用FPGA的并行计算特性进行硬件加速。将处理后的数据通过VDMA传输到PS端口,通过PS端将数据缓存到DDR3模块,之后将图像数据读出使用PS端进行隐藏层和全连接层的数据处理,最后写回VDMA通过PL端的HDMI模块驱动显示屏,将识别后的手写数字通过显示器显示。
3.3. 卷积层硬件加速设计
卷积层是整个卷积神经网络中计算量最多的一层,因此对卷积层的加速尤为重要。卷积层主要包含输入数据缓存模块、权重参数模块以及乘法和加法模块。数据缓存模块主要用来存储28 × 28的输入图像数据,权重参数模块主要是将5 × 5的卷积核的参数通过coe文件存储到ROM中用来做卷积运算,乘法和加法模块通过读取输入的缓存数据以及权重数据进行加法和乘法运算。具体的实现流程如下:
1) 乘加模块分别读取数据缓存模块中的数据生成5 × 5的卷积滑窗和权重缓存模块中数据;
2) 将得到的5 × 5的卷积滑窗与卷积核做乘法运算得到25个值;
3) 延迟一个时钟周期后将这25个数值以及偏置做加法运算得出卷积后的值。整个过程一共用了25个乘法器和25加法器,第二次的卷积运算可以通过分时复用乘法器和加法器来实现卷积功能减少资源的使用量。结构如图3所示。
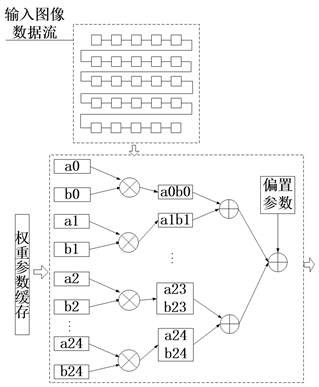
Figure 3. Hardware design of convolutional module
图3. 卷积模块硬件设计
在硬件实现时,卷积滑窗的提取是关键环节,由于输入图像为尺寸28 × 28,在提取5 × 5卷积滑窗时,可以采用流水线的方式提高计算速度。选取输入图像的行作为信号的标志,由于输入的是二值化图像,因此可以将输入图像做拼接处理,比如行标志为1时,将第一到第五行的每一列数据拼接在一起(图4绿色方框部分),一共可以生成28个数据,共使用28的时钟周期,之后将提取的数据做打拍四拍。从第五个时钟周期就依次生成了所需要的5 × 5的卷积滑窗,具体波形如图4所示。乘加模块直接采用25个乘法器和加法器做并行运算,之后将得到数据与权重参数相加,整个流程用了3个时钟周期,提高了计算速度。
第二次的卷积运算可以通过分时复用乘法器和加法器来实现卷积功能,通过分时复用虽然会牺牲部分运算速度但是会减少资源的使用量,适合逻辑资源有限开发平台。
3.4. 池化层硬件加速设计
池化层采用的是最大池化算子,池化窗口的大小为2 × 2,步长为2,通过上一级卷积处理后第一次池化的输入尺寸大小为24 × 24。池化层实现流程如下:
1) 将输入数据的第一行打一拍,把输入数据和延迟一拍后的数据在同一上升沿作比较,将大的数据写入fifo;
2) 由于步长为2,所以采用行列数据计数最后一位以及行有效标志信号作为写入fifo的标志位,即行数据最后一位为1列数据最后一位为0行有效标志信号为高时将比较得到的最大数max1写入fifo;
3) 读取写入fifo的数据与第二行数据作比较取大值max2,在下一个时钟周期时将max2与第二行数据中的下一个数据作比较取最大值max。第三行到第二十四行的操作重复上面的步骤。

Figure 4. Waveform was extracted by 5 × 5convolution sliding window
图4. 5 × 5卷积滑窗提取波形图
池化层硬件实现比较简单,采用了三个比较器在4~5个时钟周期内就可以完成一个2 × 2区域的池化,在进行数据比较时要注意时序对齐,否则将会导致数据比较出错影响系统整体功能的实现。硬件设计框图,如图5所示。
4. 系统测试与分析
本次实验使用VIVADO 2019.2对卷积层和池化层进行设计并完成综合以及布局布线生成比特流,PS部分是使用赛灵思vitis进行编程。采用赛灵思XC7Z010CLG400-1开发板,板卡上有最大数据采样率为1006 Mbpa的512 MB的DDR3 SDRAM。
4.1. 检测结果
为了节约FPGA上的资源和解决FPGA不擅长浮点数运算的问题,本文将权值数据由浮点数字转化成16 bit的定点数,由文献 [8] 可知采用16 bit的定点数可以获得与单精度浮点数相近的运算结果。在zynq平台下摄像头采集手写数字图像经过二值化后如图6中左下角所示,系统正确的将手写数字进行了二值化处理,处理后的二值化图像经过卷积层、池化层、全连接层以及输出层的处理后将识别到的数字通过显示器显示在右上角(如图6),实验表明系统在zynq平台下快速准确识别到了手写数字。
4.2. 资源及功耗分析
实验设计综合后,整体的资源使用情况如图7所示。结果显示LUT、BRAM、MMCM资源使用率比较高。由第三节分析卷积层一共使用了28个缓存ram,池化层使用了一个fifo,卷积核权值的缓存以及检测到结果后用作显示识别的.coe文件占用了比较多的储存资源从而导致了BRAM资源使用较多。MMCM资源使用了100%这是由于整个系统中需要用到2个不同的时钟,包括:摄像头采集时钟和HDMI显示时钟。乘加器采用的是LUTRAM资源所以DSP的资源使用率是0,在LUTRAM资源有限的情况下可以通过vivado软件调用开发板DSP模块实现乘加功能来节省LUTRAM的资源。LUT部分采用的是6输入查找表方式,摄像头驱动、硬件加速模块以及HDMI驱动模块的实现都会通过LUT来布局布线生成电路。LUT一共使用了9260个,占总资源的52.61%。触发器使用8928个,占用25.36%这。IO口等其他资源的使用率均未超过一半。通过以上分析可以得到系统的总体资源使用量较低,主要是由于采用分时复用等方法,实现了速度和面积的互换。
系统的功耗如图8所示,动态功耗占据系统功耗主要地位,其中静态功耗仅为0.130 W,占系统总功耗的7%,动态功耗为1.830 W占系统总功耗的93%,总片上功耗为1.969 W。动态功耗主要是由于逻辑门的开关导致,由图8可知动态功耗主要集中在PS端为1.284 W,占动态功耗的70%,这主要是因为ARM硬核工作频率高于PL端的工作频率。在PL端动态功耗主要集中在MMCM以及IO口,分别占动态功耗的11%和7%。
表1为与其他平台以及FPGA实现卷积神经网络的比较,通过仿真波形可以得到本文卷积神经网络加速模块的预测时间,将预测到的时间与其他的文献进项比较。

Table 1. Performance comparison under different platforms
表1. 不同平台下性能对比
文献 [9] 采用的是赛灵思PYNQ开发板,使用高层次综合语言HLS进行IP核的设计,与之相比本文模型总的使用时间为0.23 ms文献 [9] 的总时间为20.3 us,但是本文采用的工作时钟频率为100 MHZ文献 [9] 使用的时钟频率为200 MHZ,本文为了节省资源牺牲了部分速度换取资源,因此本文LUT资源使用量远少于文献 [9] 。在ARM平台下,采用ARM Cortex-A9处理器最大工作频率为666 Mhz,由于ARM在计算数据时为串行工作方式,因此模型总的预测时间为0.041 s速度较慢,本文速度与之相比提高了178倍,说明经过FPGA并行处理速度得到了较大的提升。与文献 [10] 比较速度以及资源消耗都有明显的提高,这是由于本文所使用的网络模型和文献 [10] 有所不同。
5. 结语
本文在zynq平台下,完成卷积神经网络手写数字识别系统设计,重点介绍了卷积层和池化层硬件描述语言的实现方法。实验结论表明在软硬协同的设计下,识别速度比软件平台下分别提升了178倍,ZYNQ平台下逻辑资源的使用量减少了一半以上,节约了硬件资源,减少了成本。