1. 引言
1.1. 随机森林
随机森林是一种基于分类树的算法,是机器学习的算法之一,最早是由Breiman [1] 提出的。
随机森林是从原始数据中用自助法放回地抽样多次,得到一定数量的自助法样本,对所有样本建立一个决策树,对于各个节点,从每个节点的所有竞争的解释变量中随机选取几个作为竞争拆分的变量,对于回归,默认是选取三分之一的解释变量来进行竞争拆分;对于分类,默认是解释变量数目的平方根来竞争拆分 [2] 。随机森林的每棵树都不剪枝,让其生长,所有决策树的结果取平均值就是回归最终的预测结果,所有决策树的分类结果最多的类别就是分类最终的结果 [2] 。
1.2. 传统经典回归方法
本文使用逐步回归、岭回归、偏最小二乘回归和线性回归四种传统的经典回归对混凝土的抗压强度做预测。
逐步回归方法是在解释变量很多时,选取最重要的变量进行建模,得到既简单,预测误差又小的模型。可以采用向前、后退的方法进行逐步回归分析。
解释变量的数据矩阵为
,残差平方和为
,岭回归 [2] 的系数满足:
。
偏最小二乘回归 [3] 就是在响应变量和解释变量中先分别找到一个因子,这两个因子在任何可能性的成分中最相关,接着在选定的一对因子的正交空间中在选择一对最相关的因子,这样下去直到选定的因子有足够的代表性即可。
线性回归是建立解释变量和响应变量之间线性关系的一种统计分析方法 [4] 。利用线性回归分析预测是当今数据建模领域中最简单、应用最广泛的模型应用。
1.3. 传统经典分类方法
本文使用混合线性判别分析、线性判别分析、logistic回归这三种传统的经典分类方法对乳腺癌进行分类。
首先,假设分类的响应变量一共有K类(K个水平),则一个个体属于第K类的先验概率
由频率
(
:第K类的样本个数;N:总样本个数)来估计。
如果有P个解释变量,则解释变量X对应的响应变量Y属于第K类的后验概率用
(
:属于第K类的观测值向量的分布函数)来估计。
对于混合线性判别分析 [2] ,后验概率为:
.
对于线性判别分析 [2] ,后验概率为:
.
另外,logistic回归 [5] 是假设响应变量
,则
,采用Logit连接函数
,
,这个广义线性模型就是logistic模型。
2. 对回归数据混凝土抗压强度的分析
2.1. 数据说明
混凝土抗压强度数据来自网址:https://archive.ics.uci.edu/ml/machine-learning-databases/concrete/。
数据共有1030个观测值,共9个变量,除了Age其他都是混凝土的原料,其中Compressive.strength作为响应变量,其余作为解释变量。变量代表的含义如表1。

Table 1. The meaning of variable names in the compressive strength data of concrete
表1. 混泥土抗压强度数据变量名代表的含义
2.2. 随机森林和经典回归方法对混凝土抗压强度数据的预测对比
分别使用逐步回归(step)、岭回归(ridge)、偏最小二乘回归(pls)、线性回归(lm)以及随机森林(RF)这五种方法对混凝土的抗压强度做预测,都使用10折交叉验证的方法对预测结果进行比较。10折交叉验证就是把数据随机的分成10份,随机选取1份当作测试集,余下的9份当作训练集,训练集用来训练模型,对模型进行参数估计,测试集用来预测,然后计算得到平均标准化均方误差(NMSE) [2] 。NMSE越小,说明预测效果相对越好。
对五种方法进行10折交叉验证得到的平均NMSE如图1所示。
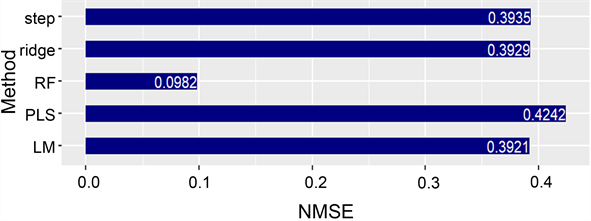
Figure 1. 10-Fold cross-verification of average NMSE by five methods for compressive strength prediction
图1. 五种方法对抗压强度预测的10折交叉验证平均NMSE
由图1可以看出,经典回归中的逐步回归、岭回归、偏最小二乘回归和线性回归的NMSE远远大于随机森林的NMSE,说明随机森林对混凝土的抗压强度预测效果最好。另外,对混凝土抗压强度的预测,线性回归虽然没有随机森林的预测效果好,但是在经典的回归方法中,线性回归的预测效果最佳,逐步回归、岭回归的预测效果微次于线性回归,偏最小二乘回归的预测效果最不佳。
3. 对分类数据乳腺癌的分析
3.1. 数据说明
乳腺癌数据来自https://github.com/cystanford/breast_cancer_data/。
数据共有569个观测值,共31个变量,其中diagnosis作为响应变量,其余作为解释变量。变量代表的含义如表2。
Table 2. Meanings of breast cancer data variable names
表2. 乳腺癌数据变量名代表的含义
3.2. 随机森林和经典分类方法对乳腺癌数据的分类对比
分别使用混合线性判别分析(mda)、线性判别分析(lda)、logistic回归(Logit)以及随机森林(RF)这四种方法对乳腺癌进行分类,也是使用10折交叉验证的方法对分类结果进行比较。通过计算10折交叉验证的平均误判率来判断分类的效果。误判率越小,说明分类效果相对越好。
对四种方法进行10折交叉验证得到的平均误判率如图2所示。
由图2可以看出,和上述回归结果一样,对乳腺癌的分类,经典分类方法中的混合线性判别分析、线性判别分析和logistic回归的误判率远远大于随机森林的误判率,说明随机森林对乳腺癌的分类效果最好。另外,混合线性判别分析对乳腺癌的分类效果虽然没有随机森林的分类效果好,但是在经典的分类方法中,混合线性判别分析的误判率最低,分类效果最佳,logistic回归的分类效果最不佳。
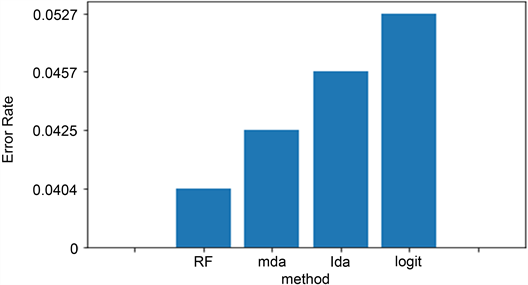
Figure 2. Average false positive rate of 10-fold cross-validation of breast cancer classification by four methods
图2. 四种方法对乳腺癌分类的10折交叉验证平均误判率
随机森林在决定类别时,会评估变量的重要性,做变量选择,可以更好地处理多重共线性的问题。对于缺失值较多的数据,随机森林仍然可以维持较好的准确度,而传统方法需要对缺失数据进行填补,一定程度降低了准确度。
4. 结束语
本文以一个回归,一个分类的数据为基础,比较传统经典回归和分类方法与随机森林的预测效果,两个数据的结果都显示,随机森林的预测效果优于传统经典方法。另外,使用传统经典方法分析此回归数据,结果显示线性回归的预测效果最佳,逐步回归、岭回归的预测效果微次于线性回归,偏最小二乘回归的预测效果最不佳。在此分类数据中,混合线性判别分析的分类效果最佳,logistic回归的分类效果最不佳。
如今,机器学习成为热门的学习课程之一,人们对多种机器学习的模型进行了比较,通常随机森林的效果最好 [6] 。随机森林 [2] 处理高维数据非常高效,也能处理观测值很少的数据,还能处理高阶交互作用和多重共线性问题。随机森林采用了集成算法,它的精度比大多数的单个算法要好,所以准确性高。相信会成为数据分析方法的首要选择。