1. 引言
风速概率分布对风能潜力的评估十分重要 [1] 。对于地理位置相距较近的临近地区,在相同时间基本处于同一风速带,其风速间具有一定的相关性,研究这种相依关系对合理利用风能以及建设高效输出的风电场都有重大意义 [2] 。
有很多经典的测度二元随机变量相关性的方法,如皮尔逊相关系数、斯皮尔曼相关系数、Kendall秩相关系数、联合密度等,但这些方法延拓到高于二维问题时面临困难。Skla [3] 提出了使用Copula函数从概率角度测度多元变量相关性的方法,广泛应用于经济和金融领域。近来也应用于风能方面。Schindler等 [4] 使用高斯Copula函数估计德国地面以上100米的风能输出。Haghi等 [5] 介绍了基于Copula函数构建电力系统随机变量之间联合概率计算方法,并利用正态Copula函数描述离岸风电场与近岸风电场出力间的相关性。Stephen [6] 将Copula函数应用到风电不确定性分析中,采用Copula函数模拟单个风电场数据。张宁等人 [7] 应用Copula理论对江苏某4个风电场出力分布之间的相依结构进行拟合,验证了相依概率性序列运算在风电场建模与计算上的有效性。
单纯的采用多元Copula函数测度随机变量的相关性具有明显的局限性,比如会忽略两两组合间尾部相关性的差异。为了克服这类局限性,Joe [8] 引入了Vine Copula结构分解多元联合密度函数。随后Bedford和Cooke [9] 作了进一步的研究,引入了Pair-Copula函数,将多元联合概率密度函数通过Vine结构分解为二元条件概率密度函数的乘法,构建了R-vine结构。Cooke [10] 等人详细介绍了Vine这种新的相依随机变量的图形模型,以及D-Vine和C-Vine这两个特殊的R-Vine结构。Barthel [11] 认为Vine结构可以灵活地捕捉多变量的关联性,并展示了选择合适的Vine Copula模型的方法。
Vine Copula的灵活特性,为多维变量的相关性研究提供了新方法。例如,在金融领域,胡月等人 [12] 构建Vine Copula模型研究东盟国家汇率市场的整体相关性。Diszmann等人 [13] 探讨了R-Vine Copula中Copula函数的选择和参数估计方法,并成功地将该方法应用于一个16维金融数据集,不仅探讨了参数的顺序估计方法,还提供了整体的极大似然估计方法。
在地理和气象方面,Guilherme [14] 等使用R-Vine Copula构建了水力发电厂水流的时间和空间的依赖关系模型,证明了该模型可以通过减少参数数量达到降低模型复杂性的效果,并将其应用于一组巴西水电站月径流数据集。为了对不同径流量级和不同预见期下河流短期径流预报的不确定性进行定量评估,刘源 [15] 等人引入R-Vine Copula构建预测模型。结果表明,通过这种模型计算的各统计量与实测数据相差较小,可以有效降低预报的不确定性。曾文颖 [16] 等人基于R-Vine Copula函数构建了河南四个地区极端降水的多因子联合概率分布模型,探讨了R-Vine Copula模型可以较好地保持原序列Spearman和Kendall秩相关系数。
在风速方面,Cai等 [17] 提出用斜正态混合模型和D-Vine Copulas构造风速联合分布研究风电容量信用评价问题。Goh等 [18] 结合主成分和R-Vine方法,研究了风速的统计特性。
目前,关于Vine Copula的理论研究比较完善,在金融和气象等领域应用比较广泛。但在拟合风速数据方面研究较少,特别是对邻近地区间最大风速这种比较极端的气候现象的相关性分析缺少研究。
D-Vine Copula是应用广泛的一类R-Vine Copula,其特点是结构简洁规范灵活。本文利用D-Vine Copula,对位于内蒙古四个近邻地区(呼和浩特市区、东胜、集宁和四子王旗)气象站采集的日最大风速分布以及相关性进行探究,文章安排如下。第2节给出Vine Copula的相关知识。第3节构建四个近邻地区日最大风速分布并探讨相关性。第4节是全文的总结。
2. Vine Copula相关知识
2.1. 基于Copula函数的相关性测度
对于二维随机变量X和Y,设边缘分布函数为
和
,对应的边缘密度函数为
和
。用定义在空间
上的二元Copula函数
表示X和Y的联合分布函数
,公式为:
其中
为Copula参数,用于度量变量的相关性。X和Y的联合密度函数
为:
(1)
这里
是Copula密度函数。
Kendall
相关系数和
的关系为:
推广到多维情形,设n维随机变量
,对应边缘分布函数为
,边缘密度函数为
,
,则多元联合分布函数和密度函数用多元Copula表示为:
(2)
(3)
这里
为Copula密度函数。
后续为了符号简洁,记
,
,即省略第i个分布函数和密度函数表达式的下标,直接用变量
的下标i表示对应的分布与密度函数。
2.2. Pair-Copula结构
利用多元Copula函数,直接引入参数建立高维相依结构时,难以捕捉到不同变量间的复杂多变的关系,具有一定的局限性。因此在讨论多变量相依结构问题时,Joe提出了构造Pair-Copula结构的方法 [8] ,Bedrord和Cooke进一步的发展,提出了Pair-Copula结构建立多元概率模型 [9] 。这种方法将多元概率密度函数分解为两两一组的条件二元Pair-Copula函数乘以边缘分布函数的形式。X的Pair-Copula表示为:
其中v是一个n维向量,
是v的一个任意分量,
则表示由向量v中不包含
的部分组成的向量。Pair-Copula结构中的条件边缘分布
则由以下公式得到:
2.3. Vine Copula结构
对于高维联合分布,Pair-Copula分解有很多种方法,逻辑结构也不唯一。本文采用Bedford和Cooke引入的R-Vine Copula这种图形结构,将n元概率分布函数通过Vine结构分解为二元Pair-Copula函数的乘积,每对Pair-Copula的选择是独立的,可以用
棵树表示 [10] 。R-Vine Copula的两种特殊结构:C-Vine Copula和D-Vine Copula应用最为广泛。n维随机变量的C-Vine Copula的密度函数为:
(4)
C-Vine Copula结构的特点是每棵树需有一个根节点(变量)与其于各节点相连,这限制了其应用,因为实践中相关的多维变量往往没有主变量。D-Vine Copula结构灵活性强,可以有效克服这个弱点。n维随机变量的D-Vine Copula的密度函数表示为:
(5)
3. 建立四地区D-Vine Copula风速相依模型
本文分析的数据为位于内蒙古西部的呼浩特市、东胜、集宁和四子王旗四个近邻地区气象站2016~2017年两年间日最高风速(单位:m/s)。数据来源为:中国气象数据网(https://data.cma.cn/)。Vine Copula的选择由R软件的RVineCopula程序包实现。
模型的构建采用IFM (即两步极大似然法)计算模型参数的极大似然估计(MLE)。具体来说,第一步是计算各个变量边缘分布参数的MLE,第二步是通过参数估计得到的边缘分布密度函数计算关于Vine Copula参数的MLE,同时在候选模型中基于赤迟信息量准则AIC选择最优D-Vine Copula分布。
3.1. 边缘分布
根据数据,绘制出四个气象站最大风速数据的核密度和柱状图,如图1所示。从图1形状看,拟合四地最大风速的边缘分布,应选择具有正偏态的分布。因此,采用两参数的威布尔分布、伽马分布和对数正态分布这三种常见的右偏分布来拟合四地最大风速的边缘分布,密度函数见表1。分别对四组数据拟合威布尔分布、伽马分布和对数正态分布,参数的MLE结果如表2所示。
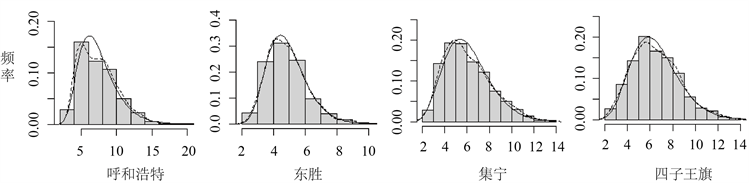
Figure 1. Histogram and fitting density curves (Axis: wind speed (m/s); Sold line: fitting density, Dotted line: kernel density)
图1. 数据柱状图和拟合最优密度曲线(横轴:风速(m/s);实线:拟合最优密度,虚线:核密度)

Table 1. Densities of the Weibull, the Gamma and the Log-normal distributions
表1. 威布尔分布、伽马分布和对数正态分布密度函数
Table 2. Parameter MLEs for the wind speed marginal distributions and the corresponding RMESs
表2. 风速边缘分布参数的MLE及对应的RMSE
对于这三种分布的拟合结果,通过均方根误差(RMSE),选择出最优的边际分布,其值越小,拟合效果越好,表达式为:
其中,
表示观测值,
表示拟合值,RMSE的计算结果列于表2最后一列。
从表2看,RMSE越小则分布的拟合效果越好,所以选择对数正态分布拟合呼和浩特和东胜两地风速的边缘分布,而集宁和四子王旗两地的风速选择伽马分布拟合为最佳,由此得出的四地风速数据最优边缘分布拟合以及参数估计见表2 (斜黑体)。最优拟合密度曲线添加在图1中。由图1可知,柱状图、核密度图和拟合密度图相匹配,充分说明选择的密度对数据拟合效果很好。
3.2. 变量顺序的选择
拟合Vine-Copula模型首先要确定合适的Vine结构。C-Vine需要确定每棵树的根节点,而D-Vine则需要确定第一棵树的变量顺序。本文使用Kendall
值作为选择变量顺序的标准。对四维风速序列,计算得Kendall
矩阵为:
由
值可以看出,第一列中第三行的元素值最大,第二列和第三列中均为第四行的元素值最大,即呼和浩特和集宁、东胜和四子王旗、集宁和四子王旗相关性最强。显然,四地的风速数据中,并没有和另外三个变量均有强相关性的主变量,因此无法选择根节点建立C-Vine结构,故选择D-Vine。由此得到第一棵树的结构,进而确定整体D-Vine结构如图2所示。在图2中,呼和浩特、东胜、集宁和四子王旗对应站点依次编码为1,2,3和4,目的是为了Pair-Copula结构清晰简洁。后续表4和图3,以及变量下标也是如此。

Figure 2. D-Vine Copula structure plot
图2. D-Vine Copula结构图
3.3. Copula族的选择和参数估计
确定D-Vine结构后,进一步对两两之间的二元Pair-Copula进行选择,并对其参数进行估计。
3.3.1. Copula族的选择
二元Copula主要分为椭圆分布族和阿基米德分布族。椭圆分布族中常用的主要是Normal Copula和t-Copula两种,用于描述对称的尾部相关性。阿基米德分布族中Clayton Copula,Gumbel Copula和Frank Copula是常用的三种Copula函数,分别拟合上尾、下尾和对称相关性。这五种Copula函数代表了变量间常见的关联特性,因此本文选择这五种Copula函数作为候选的Pair-Copula,分布函数以及对应的参数列于表3。通过计算每种Copula拟合结果的AIC值选择最优的Pair-Copula,AIC值越小则说明拟合效果越好。
Table 3. Five bivariate Copula probability functions
表3. 五种二元Copula函数分布
3.3.2. Copula参数估计
确定了D-Vine结构和选择的Copula族后,对每组Pair-Copula,采用逐树和联合密度两种方法对参数做MLE。设
是维数为n,容量为N的样本。首先,按顺序逐树对每组Pair-Copula参数计算MLE。由公式(5),第
棵树的似然函数为:
由此计算出第m棵树候选Pair-Copula函数参数θ的MLE,然后根据AIC准则选择第m棵树的最优Pair-Copula函数。本文中,
。表4中列出了逐树计算得到的最优Pair-Copula函数以及对应参数的MLE。
Table 4. Pair-Copula functions and the parameter MLEs based on the tree by tree method and joint density method
表4. Pair-Copula选择及参数逐树估计和联合估计结果
其次,由公式(5)中得出的n维随机变量的D-Vine Copula联合分布密度函数计算D-Vine Copula参数的MLE,其似然函数表示为:
联合密度方法计算D-Vine Copula的相关参数后,得出的D-Vine Copula的Pair-Copula选择类型没有变化,参数估计结果仍列在表4。
计算得到逐树拟合与联合拟合的似然值分别为324.87和352.39,对应的AIC值为−637.74和−692.78。
3.4. 模型分析与讨论
由3.1节以及对应的表2可知,基于RMSE值,集宁和四子王旗的风速边缘分布选用伽马分布拟合,呼和浩特和东胜风速则用对数正态拟合。尽管威布尔分布常用于拟合风速 [19] [20] [21] ,但对本文讨论的日最大风速数据而言,并不是最优的选择。
根据秩相关性,建立了四地日最大风速D-Vine Copula相依模型,获得了Pair-Copula结构。表4可知,每对Pair-Copula对应不同的二元Copula函数。这充分说明,四地风速相依概率模型不适于用常规的联合概率(3)拟合,因为(3)难以捕捉到不同变量之间相异的关联性,缺乏灵活性。D-Vine Copula则能够较好的捕捉到多个变量之间不同的关联性。
在所选择的二元Copula函数中,联合拟合和逐树拟合得到的Pair-Copula参数MLE有差异,但Pair-Copula选择一致,见表4。从AIC值看,联合拟合效果优于逐树拟合,这是因为联合拟合是全局最优估计的结果。但是,D-Vine Copula分解的待估计参数的个数随着变量的增加而成倍增加。例如,n个维度的变量,增加一个维度得到
个变量,即使每个Pair-Copula函数均采用单参数模型,联合拟合参数估计方程也增加n个,而逐树拟合在每棵树上参数只增加一个。众所周知,MLE往往依赖于初值。因此,如果建立联合密度计算参数MLE,建议逐树拟合得到的MLE作为其初值,以降低初值选择的困难。
依据表4构建了关于四个站点间日最大风速的四维D-Vine Copula风速相依模型,Pair-Copula参数采用联合估计的结果,联合密度函数的Pair-Copula的分解表达式为:
(6)
其中,
分别表示Normal Copula,Clayton Copula,Gumbel Copula,Frank Copula的密度函数,该函数由表3分布函数对
求混合二阶偏导即可得到;
和
分别表示对数正态密度和伽马密度以及对应参数估计见表1和表2。由此,我们完整构建了测度四个站点间最大风速相关性的D-Vine Copula相依模型,轮廓图如图3。
由图3发现,两两近邻的最大风速具有较为明显的上尾和下尾相关性。四子王旗和集宁,以及在已知四子王旗最大风速的条件下,东胜和集宁的两两下尾相关性较强一些,其他地区相关性呈对称状态。如前面所讲,针对高维相关的随机变量概率分布问题,如果用多元Copula函数,无法反应不同地区风速的相关性差异,而D-Vine Copula方法可以灵活清晰的反应多元变量之间的不同的关联关系,如对称相关、非对称相关和尾部相关。
4. 结论
本文用D-Vine Copula方法建立了内蒙古近邻四地日最高风速的多元联合分布。该方法是将联合分布分解为边缘分布和Pair-Copula函数乘积的形式。使用两阶段法得到了边缘分布和Pair-Copula函数的最优选择和参数的极大似然估计。其中,Pair-Copula参数的极大似然估计采用了逐树估计和联合估计两种方法,拟合结果表明联合估计方法优于逐树估计。模拟表明风速间存在关联性,多元联合分布的D-Vine Copula分解方法灵活清晰的反应了不同地区的关联性差异。
NOTES
*通讯作者。