1. 引言
张量是描述多维向量和对偶空间的笛卡尔上多重映射关系的几何体 [1] ,是进行多维阵列信号处理的有力工具 [2] 。随着科技的飞速发展,扩展频谱通信技术是现代通信技术的热点之一。因此,国内外学者对张量分解技术在直接序列码分多址(Direct Sequence-Code Division Multiple Access, DS-CDMA)盲数据检测中的应用进行大量的研究。
Sidiropoulos N D等人建立了平行因子分析(Parallel Factor Analysis, PARAFAC)模型与DS-CDMA系统盲多用户分离均衡检测之间的联系,基于低秩三向阵列分解和三线性交替最小二乘回归的唯一性,提出了一种确定性盲PARAFAC接收机,研究结果表明:该接收机具有性能接近非盲最小均方误差的优点 [3] 。Sørensen M等人介绍几种正交约束条件下的PARAFAC的数值算法,这就为不相关信号的接收提供了基础,经过研究结果发现PARAFAC接收机的性能最好 [4] 。Fernandes C A R等人提出了用于上行多用户协同分集系统的新型盲接收机,同时还引入CANDECOMP/PARAFAC (CP)模型,最后通过计算机模拟结果发现各项性能显著提高 [5] 。上述研究表明PARAFAC模型在盲多用户分离检测中的优越性。
在PARAFAC模型的基础上,刘旭和许宗泽研究DS-CDMA系统的盲检测算法,并且提出一种基于正交约束的PARAFAC的DS-CDMA盲接收机,通过研究结果发现具有正交约束的三线性最小二乘算法在处理DS-CDMA比传统的三线性最小二乘算法有更低的克拉美罗界。此外,正交约束–平行因子分析接收机改善了误码率的性能,收敛速度也大大提高 [6] 。Bro R等人提出了复平行因子分析(Complex Parallel Factor Analysis, COMFAC)算法,该算法用于三线性并行因子分析模型拟合到DS-CDMA信号中,同时基于对若干辅助子程序的组合和改进,研究结果表明:算法达到缩短计算时间的目的 [7] 。De Lathauwer L和Castaing J提出了一种基于张量的DS-CDMA信号在天线阵列上的盲分离机制,研究结果表明:相对较高的用户数量,新技术比ALS (Alternate Least Squares)算法计算盲接收机更加准确,并且计算要求更低 [8] 。曾卉露提出基于复平行因子多故障盲分离方法,克服了传统算法在分解的时候运算时间比较长的困难,通过研究发现了方法的有效性 [9] 。于桂晨提出一种基于耦合随机投影和耦合张量分解的大规模张量分解算法,通过对比研究结果表明大规模张量分解算法比传统的算法具有更高的精度;而相对传统张量分解算法虽然有性能损失,但是获得了更少的空间占用和更快的运行效率 [10] 。上述研究表明基于张量分解的算法相对于传统的算法而言,具有提高收敛速度、缩短计算时间等显著的优点。
基于张量分解的技术,蒙特卡洛思想在模拟仿真阶段起着关键性的作用。张珽研究了蒙特卡洛方法在通信系统中采用不同的调制方式下受高斯白噪声信道影响的误码率,并且通过研究证明蒙特卡洛方法的正确性 [11] 。曾璐和谢晓尧通过MATLAB研究不同噪声在直接序列扩频通信系统中误码率与信噪比之间的关系,结果表明:数字信号在复高斯白噪声信道产生的误码率比在高斯白噪声信道中产生的误码率略大 [12] 。
综上所述,国内外相关专家、学者对张量分解技术在DS-CDMA盲数据检测中的应用进行了非常深入的研究。本文就是在DS-CDMA系统中建立PARAFAC模型进行分解,通过蒙特卡洛方法模拟生成多维阵列信号,借助COMFAC算法对模型求解得到误码率的大小,最后在相同的信噪比条件下,将误码率与天线数进行数据拟合来研究在各个信噪比条件下最优天线的个数,在仿真实验中发现规律来达到节约资源的目的。
2. 张量的理论基础
本小节主要介绍有关张量的数学理论知识,包含张量的数学表示和基本的运算。张量是一个定义在一些向量空间和一些对偶空间的笛卡尔积上的多重线性映射 [13] ,是多维数组的简称。本文研究的重点是张量在通信领域中的应用问题,因此,本小节主要以三阶张量为主展开介绍。
2.1. 张量的表示
1) 三阶张量
三阶张量通常用花体符号表示,记作
,它的元素表示为
。
表示三个不同的维度,结合不同的实际问题就是代表三个不同的物理意义。
2) 张量纤维
三阶张量的三路阵列称为张量纤维,即改变一个下标,固定其他下标不变得到每一路阵列。三阶张量可以用不同的模式来表达。模式-1表示三阶张量的行纤维,记作
;模式-2表示三阶张量的列纤维,记作
;模式-3表示三阶张量的管纤维,记作
。对于高阶张量,模式-n表示N阶张量有N种不同的纤维。
3) 张量切片
张量切片是指将三阶张量按照指定单个索引将产生一个特定方向的矩阵。模式-1表示水平切片,记作
;模式-2表示侧面切片,记作
;模式-3表示正向切片,记作
。
4) 张量的矩阵化
张量的矩阵展开是对高阶张量进行降维的过程。对张量
进行n模展开,记作
或者
。按照Kiers水平展开方式 [14] 进行矩阵化,可以得到模式-1、模式-2、模式-3的水平展开分别为如下式所示:
(1)
(2)
(3)
如图1所示是具体描述了三阶张量
的Kiers水平展开模式。
2.2. 张量的运算
1) 张量的外积
对于N阶张量
和M阶张量
,上述二者外积定义为
,其中
,具体如下所示:
(4)
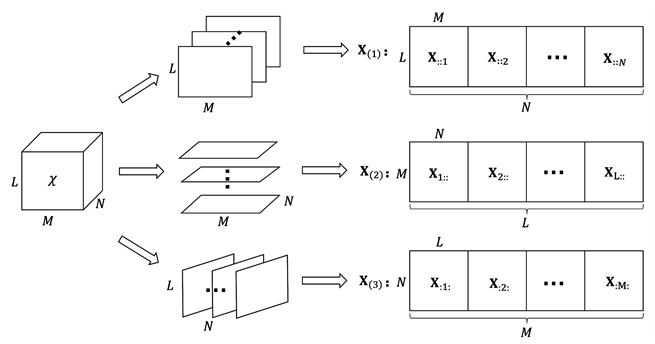
Figure 1. Kiers horizontal expansion of third order tensors
图1. 三阶张量的Kiers水平展开图
2) 张量的内积
对于N阶张量
和张量
,它们的内积定义如下所示:
(5)
3) 张量的Frobenius范数
定义张量
的Frobenius范数为:
(6)
4) Kronecker积
对于任意二维矩阵
和矩阵
的Kronecker积是一个
的矩阵,记作
,具体运算过程如下所示:
(7)
5) Khatri-Rao积
任意两相同列数的矩阵
和
的Khatri-Rao积记作
,具体如下所示:
(8)
其中Khatri-Rao积还有如下的运算性质 [15] :
(9)
(10)
其中
表示
的对角矩阵,其中的元素表示矩阵
中的第j行中的元素。
6) Kruskal秩
任意一个矩阵
的Kruskal秩,记为k-秩或者
,它表示矩阵的任意r个列向量都是线性无关的最大整数 [16] 。矩阵的k-秩小于等于矩阵的秩。如果由列向量构成的矩阵
,并且这些列向量是从绝对连续分布中独立提取出的元素,矩阵不仅满秩而且满足k-秩,即
[16] 。
7) 秩一张量
如果一个三阶张量
当且仅当它能表示成三个向量的外积的形式,即
(11)
称此张量为秩-1张量。对于N阶张量,以此类推。
3. 模型的建立
3.1. PARAFAC模型(Parallel Factor Analysis)
PARAFAC (Parallel Factor Analysis)模型中文解释为平行因子分解法,又被称作CANDECOMP、PARAFAC或者CANDECOMP/PARAFAC (CP)。它实际上是对高维张量进行拆分的方法,其核心思想是用有限个秩1张量的和来近似某一个张量,使其误差达到最小的目的。PARAFAC模型在统计学、信号处理中得到广泛应用。
任意一个
三阶张量
,其中的每一个元素记为
,
,
,
。
、
和
表示三阶张量在三个不同的方向上的切片,其中元素的对应关系如下所示:
(12)
得到PARAFAC模型如下式所示:
(13)
其中
、
和
都是要估计的参数,而
残差项,
表示成分的求和数量。
表示三阶张量按照第k个模式展开得到
的矩阵,那么可以得到PARAFAC模型:
(14)
其中矩阵
表示含有元素
的
阶矩阵,同理矩阵
是
阶矩阵,但是
表示对角矩阵,包含
阶矩阵
的第k行,对角元素为
。为了在最小二乘中拟合模型,应该最小化损失函数,如下所示:
(15)
3.2. 模型的唯一性分析
PARAFAC模型具有模糊性问题,即不确定性问题,具体就是排列模糊和尺度模糊问题 [3] 。对于上一小节中的三阶张量
和因子矩阵
、
和
,排列模糊问题 [2] 具体如下式所示:
(16)
其中
表示多线性乘积,
表示
列交换矩阵,
,
,
。
尺度模糊问题 [2] 为:当满足
,即
(17)
针对PARAFAC模型的排列模糊和尺度模糊问题,Kruskal在1977年提出了PARAFAC模型唯一性分解的充分条件 [17] :
(18)
其中
表示三个因子矩阵的列向量数。满足式(17)的时候,张量分解唯一,此时只存在排列模糊和尺度模糊问题。排列模糊和尺度模糊表示如下所示:
(19)
其中
为列交换矩阵,
表示对角模糊矩阵,并且满足
。
在2.1中介绍如果由列向量构成的矩阵
,并且这些列向量是从绝对连续分布中独立提取出的元素,因此矩阵不仅满秩而且满足k-秩。矩阵
、
和
的列向量是从绝对连续分布中独立提取的元素,式(17)就可以写成:
(20)
由式(19)可知:PARAFAC模型可以通过调整因子矩阵的行数来使其分解唯一。在实际应用的场景中就可以改变系统的相关参数来使模型分解唯一。
4. 模型的求解
PARAFAC模型最传统的求解方式是三线性交替最小二乘算法(Trilinear Alternating Least Square, TALS)。它的基本原理是首先更新一个矩阵,然后对其余的矩阵进行最小二乘算法进行更新,如此迭代更新矩阵直到收敛,最终算法结束。由于TALS算法的缺陷是要花费大量的时间来计算,因此本文主要借助一种提高TALS收敛速度的算法来对PARAFAC模型进行求解,称为COMFAC (Complex Parallel Factor Analysis)算法 [7] 。该算法的原理框架如图2所示。
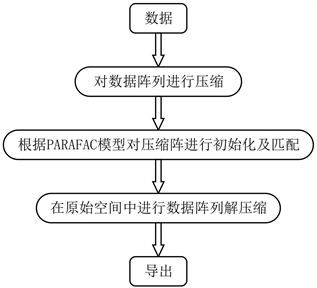
Figure 2. COMFAC algorithm flowchart
图2. COMFAC算法流程图
首先是对数据阵列进行压缩。数据阵为三阶张量
,分别在这三个维度上新定义三个压缩矩阵
、
、
,值得注意的是
。因此,三阶张量
被压缩成
。在压缩过程中使用的是Tucker3-ALS算法,它的步骤如图3所示。
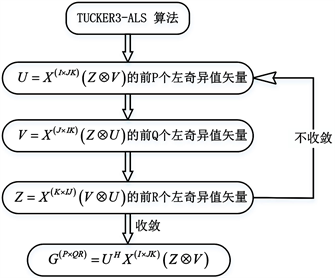
Figure 3. Tucker3-ALS algorithm flowchart
图3. Tucker3-ALS算法流程图
根据
可知,只需要进行矩阵的逆变换就可以得到原始矩阵
,即
(21)
对数据进行压缩之后,接着对矩阵
的PARAFAC模型进行初始化,主要是对
、
、
进行奇异值分解。
PARAFAC模型是从三个不同的维度来展开数据阵,经过压缩后的矩阵
可以表示为:
(22)
其中
、
、
。
表示经过奇异值分解之后取得前
个左奇异值矢量,即因子的个数。
表示误差矩阵。在PARAFAC模型的框架下,三阶张量可以重构成二维矩阵形式。同样在COMFAC分解中,压缩阵
可以表示为:
(23)
等价于:
(24)
为了简化计算,忽略矩阵上标,将(24)代入(21)中,得到:
(25)
根据运算性质(10)可得
(26)
定义
,最终得到
(27)
最后再根据实际应用背景来计算误码率大小。
5. 应用
本文只考虑上行DS-CDMA系统,其中用户数量
,传输的数据是采用随机二进制相移键控(Binary Phase Shift Keying, BPSK)符号,扩频码长度为
,符号快照的块长度为
。在观测接收到张量
后,首先加入不同信噪比条件下的高斯白噪声,其次进行模糊去除,接着执行COMFAC算法来对DS-CDMA系统进行盲数据检测。它们的性能通过误码率(Bit Error Rate, BER)来体现,这是通过平均1000次蒙特卡洛独立实验得到的平均值。最后,本文在相同的信噪比条件下,得到天线根数范围取4到20对应的误码率,这是由于根据PARAFAC模型的唯一性可知天线根数至少为4,否则误码率的大小脱离实际意义。在此基础上将误码率与天线根数进行数据拟合,取合适的拟合方式,拟合函数中最小的极小值点进行四舍五入得到不同信噪比条件下的最优天线的根数。如图4和图5所示是信噪比1~30条件下误码率与天线根数的拟合曲线。拟合函数如式(28)~(57),具体见附录。
通过观察拟合曲线并且结合拟合方程来求函数的最小的极小值点,结合实际意义进行四舍五入,得到结果如表1所示。通过观察结果可知拟合方式主要有三种:Sum of Sine、Fourier、Polynomial。它们的拟合优度都达到90%以上,高信噪比的最优天线数少,并且比较稳定;低信噪比的最优天线数多,并且随着信噪比变低,它的最优天线数量不稳定;当信噪比为负数的时候,误码率趋于稳定的速度非常慢进而导致研究最优天线数失去实际意义。

Table 1. Optimal antenna statistics table
表1. 最优天线统计表
6. 结论与研究展望
6.1. 总结
本文在DS-CDMA系统中基于张量分解技术建立PARAFAC模型,固定用户数量、扩频码数、符号快照的块长度数,改变信噪比和天线数量,接着执行COMFAC算法得出误码率,将误码率与天线数量进行数据拟合,最后观察拟合函数曲线和拟合方程得出最优天线数。根据蒙特卡洛模拟和数据拟合发现拟合方式主要有三种:Sum of Sine、Fourier、Polynomial,同时拟合优度都在90%以上。此外,最优天线受信噪比的影响,高信噪比的最优天线数少,并且稳定为5根天线;低信噪比的最优天线数多,并且随着信噪比变低,它的最优天线数量不稳定;当信噪比为负数的时候,误码率趋于稳定的速度非常慢,得到的结果也失去研究意义。
6.2. 研究展望
第一,本文并没有考虑负信噪比,因为误码率趋于稳定的速度非常慢,甚至误码率的大小一直脱离实际意义,这是受算法的影响。虽然PARAFAC模型只是张量分解的一种形式,执行COMFAC算法的时候虽然极大提高了运算时间,但是算法精度和收敛速度可以进一步提高。
第二,本文只是取的离散的正整数信噪比,此外信噪比为负数的时候并没有考虑。因此,如果信噪比范围扩大,并且是连续的情况,最优天线的数量可以进一步深入研究。
第三,本文只是在DS-CDMA系统中固定用户数量、扩频码数、符号快照的块长度数来进行仿真模拟,实际生活中的问题更加复杂,误码率和用户、扩频码、天线数量等的其他函数关系可以进一步研究,甚至误码率的其他影响因素也是不容忽视的。
未来的工作聚焦于上述三点,并且模型和算法的优化更是研究的重点。
附录
当
的时候,拟合函数:
(28)
当
的时候,拟合函数:
(29)
当
的时候,拟合函数:
(30)
当
的时候,拟合函数:
(31)
当
的时候,拟合函数:
(32)
当
的时候,拟合函数:
(33)
当
的时候,拟合函数:
(34)
当
的时候,拟合函数:
(35)
当
的时候,拟合函数:
(36)
当
的时候,拟合函数:
(37)
当
的时候,拟合函数:
(38)
当
的时候,拟合函数:
(39)
当
的时候,拟合函数:
(40)
当
的时候,拟合函数:
(41)
当
的时候,拟合函数:
(42)
当
的时候,拟合函数:
(43)
当
的时候,拟合函数:
(44)
当
的时候,拟合函数:
(45)
当
的时候,拟合函数:
(46)
当
的时候,拟合函数:
(47)
当
的时候,拟合函数:
(48)
当
的时候,拟合函数:
(49)
当
的时候,拟合函数:
(50)
当
的时候,拟合函数:
(51)
当
的时候,拟合函数:
(52)
当
的时候,拟合函数:
(53)
当
的时候,拟合函数:
(54)
当
的时候,拟合函数:
(55)
当
的时候,拟合函数:
(56)
当
的时候,拟合函数:
(57)