1. 引言
近十几年来,随着互联网的日益普及,拍摄设备如手机、相机的普及以及成本的下降,视频正逐渐成为信息交流的媒介以及大众获取网络信息的重要形式之一,视频的数量每秒正以指数级爆炸形式的速度增长,因此开发一些智能技术来高效地检索,分析大量的视频就变得非常迫切。视频摘要 [1] 就是最有前景的解决上述问题的技术之一。视频摘要目的是将一个视频压缩成一个简短的摘要。与原视频相比,摘要保持主要的语义信息的同时,大大缩短了原视频的长度。
视频摘要首次被Pfeiffer [2] 提出后,由于其巨大的实际应用意义,引发了众多学者的关注。早期的视频摘要技术大多基于手工标准方法 [3] [4] ,随着近年来深度学习的发展,许多基于深度学习的视频摘要方法被相继提出,并且取得不错的效果。这些方法主要可以分为无监督与有监督,由于没有人工注释作为参考,无监督的方法不能很好的代表原视频的内容,因此,有监督的方法往往比无监督方法效果更好。本文将采取有监督的方法。最有代表性的有监督视频摘要是基于LSTM [5] (Long Short-Term Memory)。但LSTM有它固有的局限性,每一帧都需要等待前一帧处理完,不能实现并行化处理以充分利用GPU硬件,并且这种网络结构受视频长度影响,无法捕获长距离的时间依赖性,还存在梯度消失等问题。卷积神经网络(Convolutional Neural Networks, CNN) [6] 是另外一种主要的视频摘要方法,但这类网络中存在大量的下采样和最大池化操作,这将导致大量视频细节信息的丢失,且无法通过上采样恢复。自注意力 [7] 近年来也被用于处理视频摘要问题,得益于其高效的计算效率,取得了不错的效果,但目前基于自注意力的视频摘要方法都忽略了通道间的注意力。受上述工作启发,本文提出一种基于空洞卷积的多维度注意力网络(Dilated Convolutional Multi-Dimension Attention Network, DCMAN)。
该网络摒弃传统的LSTM结构,使用级联空洞卷积网络替代普通的卷积网络,空洞卷积网络不包含下采样与最大池化,通过设置合作的膨胀系数扩大网络感受野,设置padding大小保证原特征图大小不变,设置更多的跳连接结构融合上下不同尺度的信息,此外,卷积网络融合了包含空间与通道的多维度自注意力网络捕获视频的长期依赖性。本文的主要贡献如下:
1) 提出一种级联空洞卷积结构,该网络不包含下采样与最大池化操作,最大限度保留了视频的细节信息,通过设置padding保证原特图大小不变,并且设置合适的膨胀系数扩大网络的感受野。该网络还包含更多的跳连接结构,融合了更多不同尺度的上下文信息,提高摘要的丰富性。
2) 在卷积网络后融入为高质量视频摘要分配重要性分数的注意力感知模块,该模块包含空间与通道注意力,更大程度提高了视频摘要的质量。
3) 在四个公共数据集上进行大量实验,实验结果表明本文的方法优于目前最新的方法。
2. 国内外研究现状
人工智能,机器学习,深度学习是当今学术界的热门词汇,深度学习已经被证实是普适性最先进的技术之一,目前优秀的视频摘要方法大多都基于深度学习。Zhang等人 [8] 使用LSTM建模视频帧之间不确定时间依赖性,并通过行列式点过程增加视频帧的多样性表示。Zhao等人 [9] 提出双层LSTM结构。第一层用来提取和编码输入特征序列,第二层通过第一层编码后的信息选择视频的关键片段。在此基础上,Zhao等人 [10] 新增了一个训练好的组件辨别镜头级别视频的时间结构,并通过这些知识生成关键镜头形式的视频摘要。Ji等人 [11] 引入自注意力机制,自适应地调整当前状态对上下文状态的注意力权重,学习对视频摘要更重要的视频帧,这项工作在文献 [12] 得到提升,在网络中插入了一个语义保留网络。Lal [13] 等人提出带有卷积LSTM的编码解码结构,通过镜头检测机制增强摘要的视觉丰富性。
Rochan等人 [14] 摒弃LSTM结构,在语义分割与视频摘要之间建立了联系,建立了全卷积序列网络-FCSN处理视频摘要问题,实现了网络的并行化处理,但是该网络忽略了潜在的时间依赖性,一样无法捕获长期依赖,并且网络中重复的下采样与最大池化操作导致很多细节信息丢失,且无法通过上采样恢复。Fajtl等人 [15] 提出一种序列到序列的纯注意力网络,对于整个视频序列,通过简单矩阵乘法就可以获得每个视频帧的重要性,大大降低了计算复杂度,取得了不错的效果,但确忽略了通道间的注意力。Gupta等人 [16] 将卷积与注意力结合在一起,Liang等人 [17] 将卷积,注意力,LSTM以生成对抗的方式融合在一起。但他们卷积网络中一样包含了重复的下采样与最大池化操作以及忽略了通道间的注意力。
3. 整体设计
3.1. 模型架构
本文将基于有监督的视频摘要视作为序列到序列的预测问题,并提出DCMAN模型,与传统的编码解码网络不同,DCMAN无需固定长度的中间隐藏层状态,这样对于较长的视频序列不会导致较高的信息丢失。模型架构如图1所示,我们认为视频是帧的集合,每一帧类似于一张图像,因此会包含一定量的冗余信息,因此,本文不是直接处理原始视频,而是先执行预采样,目的是在不丢失任何信息的情况下降低模型的计算成本。如图1所示,模型的输入即预采样后的特征定义为
。其中F表示视频的帧数,d表示视频特征的维度。全卷积以F为输入生成一个中间特征序列
。将原始特征F与得到的中间特征序列P一同输入到空间注意力与通道注意力中,最终产生序列
,代表每一视频帧的重要性分数预测。DCMAN模型整个包含两大模块,首先是空洞卷积模块,之后是自注意力模块。下文将详细介绍这两个模块。
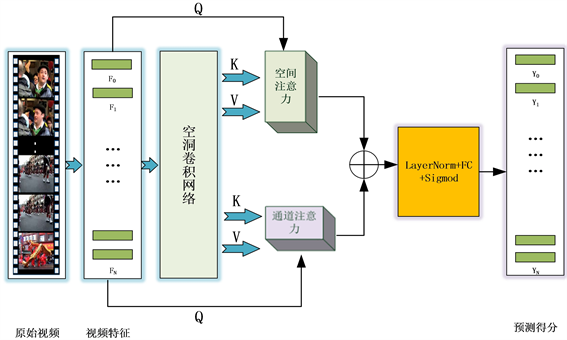
Figure 1. The architecture of DCMAN network
图1. DCMAN模型架构
3.2. 级联空洞卷积网络
本文使用级联空洞卷积网络作为视频特征的全局表示提取器,在时间维度上执行一系列卷积操作。与Rochan [14] 中卷积网络结构不同,首先本文不包含重复的下采样与池化操作,因为这将导致视频特征大量细节信息丢失。本文采用空洞卷积,空洞卷积的优势在于既可以通过设置padding保证原特征图大小不变,又可以通过设置合适的膨胀系数扩大网络感受野。此外,本文在不同的网络层之间添加了比原文更多的残差连接结构,将浅层的粗糙特征与深层的精细特征结合来获取更多视频的时间信息。级联空洞卷积架构如图2所示,首先使用两个三重卷积层对帧特征进行初步提取,三重卷积层由三个3 × 3时间卷积层组成,每个时间卷积层后面都会加一个批处理归一化和一个RELU激活。然后,使用4个三重时间卷积层来扩展网络的感受野。这里的三重卷积层由三个3 × 3时间空洞卷积层组成。类似地,每个时间扩张卷积层之后是批处理归一化和RELU激活。每三个卷积核膨胀系数依次设置为[1] [6] [12] (下文实验部分将验证该数据设置),类似于一种锯齿结构,从而能够从不同尺度提取上下文信息,然后通过元素加法的形式融合多尺度上下文信息,得到更丰富的时间信息。

Figure 2. The architecture of cascaded dilated convolutional network
图2. 级联空洞卷积网络架构
3.3. 多维度自注意力网络
虽然上文中经过改进的全卷积序列网络可以捕获视频的全局表示和短期依赖,但是考虑长期的时间依赖关系对于生成一个高质量摘要来说也是至关重要的。因此,本文在卷积网络后融入自注意力机制来弥补这一缺陷。与前人研究不同,本文不仅融入空间注意力机制,而且将通道注意力也考虑其中。通道注意力在图像领域已经被证明具有重要作用,而在上文中阐明了图像数据与视频数据之间的相似性。因此,我们认为通道注意力对处理视频数据也
应具备相当的益处,下文实验部分也将证明此观点。
自注意力机制计算过程可以分为三大步,如图3所示。首先根据网络的输入初始化查询向量,键向量以及值向量,与大多数研究有所不同,本文不直接将卷积网络的输出作为初始化查询向量的前提,而是通过原始特征F初始化查询向量,这样可以获取关于整个视频更加完整的信息,这一观点也将在下文实验中证实。接着对于网络的每一个输入,通过查询向量与其余所有键向量做乘法得到注意力权重。最后,把值向量与权重相乘后求和,得到每个向量对应所有向量的权重。
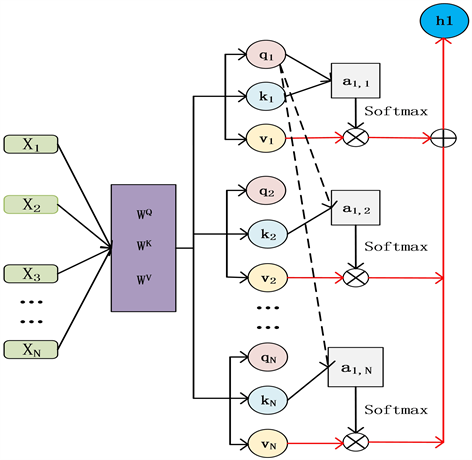
Figure 3. The calculation process of self-attention
图3. 自注意力计算过程
由前文可知,首先我们需要获取查询,键以及值向量,模型输入为
,卷积网络的输出为
,则查询向量Q,键向量K,值向量V可以表示:
(1)
(2)
(3)
其中
,
,
分别是网络优化时待学习的权重矩阵,F表示视频的帧数,d表示视频特征的维度。
接着需要计算注意力分数。第一步利用得到Q和K以及缩小的点积计算任意某个时刻t的输入特征Fi与整个序列之间的相关性,第二步将得到的相关性乘以o,o是一个缩放参数,目的是削弱查询向量与键向量之间的点积值,这样做利于网络的反向传播。空间与通道注意力分数的计算过程分别如式(4),式(5)所示,其中<.>表示点积计算。
(4)
(5)
然后根据得到的注意力分数计算注意力权重,空间与通道注意力权重分别如式(6),式(7)所示,其中都使用softmax函数进行归一化操作。
(6)
(7)
将得到的权重进行求和之后,使用两层神经网络对求和结果进行回归操作,计算如式(8)所示。与原始的transformer结构一样,第一层神经网络对求和的结果施加层归一化(Layer Normalization),避免模型过拟合。接着使用两个线性层分别是1024个神经元和1个神经元从而可以得到我们想要的维度。第二层使用Sigmoid预测最终的视频帧得分。
(8)
最后,我们选择均方误差(MSE, Mean Squared Error)损失函数作为网络的目标函数。MSE通过计算网络预测分数与人工注释分数的差值的平方和后最后再求平均,如式(9)所示,通过反向传播算法使得目标函数损失值达到
最小,得到最优解。
(9)
4. 实验设计与验证
4.1. 视频摘要数据集与数据集设置
我们在两个常见的公共数据集上进行了实验,即SumMe和TVSum。SumMe由25个视频组成,涵盖如体育和假期等主题。每个视频持续时间为1.5到6分,这些视频由15至18名人类以帧级重要性得分形式进行注释。TVSum包含50个不同主题的视频。每个单独视频的持续时间为1至5分钟,注释形式为帧级别重要性得分,鉴于这两个数据集的小规模不足以训练神经网络,我们还使用OVP (50个视频)和YouTube (39个视频)来加强训练数据集。OVP数据集包含纪录片和其他不同类型的视频。YouTube的数据集视频有不同的主题,如新闻和体育。这两个数据集以关键帧进行注释。四种数据集信息如表1所示。
根据数据集介绍可知有两种数据集设置:未增强与增强。未增强模式下仅对SumMe与TvSum数据集进行训练,将其中80%数据集作为训练集,其余作为测试集。增强模式下是在未增强的基础上增加了其余三个数据集扩充了原先的训练集。本文按照80%训练集,20%测试集比例随机划分5次,并将5次结果的平均作为最终的模型的表现分数。具体设置信息如表2所示。
4.2. 评价指标与环境
为了与其他方法公平比较,本文采用其他大多视频摘要方法采用的指标F_Score作为评判标准,同时,F_Score能够评估模型摘要与用户摘要的相似性。假设S0是模型预测摘要,S1是用户打分摘要,然后通过S0和S1的时间重叠部分计算精确率P和召回率R。其中P表示预测正确的摘要占整个算法预测摘要长度的比例,R表示预测正确的摘要占整个注释摘要的长度的比例。P和R的计算方法如下:
(10)
(11)
则F_Score可以定位为:
(12)
与其他研究一样,本文采用五折交叉验证的测试方法。并且对每个视频的下采样率设置为2 fps,下采样后每一视频帧维度为1024维,该过程是通过从ImageNet训练的GoogLeNet网络的倒数第二层提取出来的。训练过程中,采用ADAM优化器以及L2的正则化,epoch设置为300,学习率rate设置为5 × 10−5。本章实验的软硬件配置为:PyTorch 1.10.1,python3.6内存为16 GB的NVIDIA GeForce GTX 3090 GPU的计算机。
此外,视频经模型处理后产生序列化的重要性得分。在评估时,本文采用KTS [3] 算法把这些帧级别的分数转换为镜头级别的分数,再由这些镜头级别的分数作为依据挑选出重要镜头形成最终的摘要视频。
4.3. 实验结果与分析
为了验证本文DCMAN模型的有效性,将DCMAN模型与最新的5个模型进行比较,包括基于注意力机制的,基于LSTM以及改进RNN的,以及基于全卷积序列网络的。因DCMAN模型是基于有监督的,而一般无监督的方法的结果会比有监督方法差,所以本章只挑选有监督的方法作为对比对象。1) Zhang [8] 等人是第一个运用LSTM捕获视频中前向和后向信息,并提出DPP结构提升关键帧之间的差异性。2) Fajtl [15] 提出一种纯注意力机制,序列到序列的网络——VANSNet。3) Ji等人 [11] 提出A-AVS和M-AVS,都是基于注意力编码解码,其中M-AVS是乘法形式注意力,A-AVS则是加法形式注意力。4) Rochan [14] 阐述了语义分割任务与视频摘要之间的联系,并将主流的语义分割网络改造后应用于视频摘要中,取得了不错的表现。5) Mahasseni [18] 提出基于生成对抗网络(Generative Adversarial Network, GAN)的方法,目标是最小化重建摘要于人工注释之间的距离,本文只引用其中有监督的方法。这5种方法的实验结果均取自于原文。
表3展示了DCMAN模型与其他方法在SumMe和TvSum数据集上的结果对比,涵盖了增强与未增强两种数据集设置。显而易见,DCMAN模型在两个数据集上的表现领先其他方法。M-AVS略领先A-AVS,说明乘法形式的注意力更为有效,且运算速度方面更有优势。VANSET略优于FCSN。FCSN虽然获取到视频的全局表示与短期依赖,但视频的长期依赖性的捕捉没有VANSET完善。VANSET明显优于DPP-LSTM与GAN (sup),因为LSTM也无法捕获视频的长期依赖,且运算速度慢,生成对抗方法会给摘要结果带来巨大的不稳定性。在SumMe数据集上,本文提出的DCMAN优于VANSET,在未增强设置下比VANSET提升了1.87%,在增强模式下提升了1.38%,在TvSum数据集上,在未增强设置下比VANSET提升了0.88%,在增强模式下提升了1.14%,这证明通道注意力对结果提升是有益处的。此外,与FCSN比较,DMCAN提升效果更加明显,因为DMCAN中级联空洞卷积网络保留了视频大量的细节信息,而且还融合了注意力模块以及更多的跳连接结构,前者捕获了视频的长期依赖性,后者融合了更多的上下尺度信息。
综合表3的结果,DCMAN优于其他方法的原因可以总结为以下几点:
1) 一维卷积对处理序列问题更具优势,提取视频帧之间的时间信息,而且无需关注相关的位置信息;2) 一维卷积网络中丢弃了最大池化和反卷积操作,保留了更多的细节信息,同时空洞卷积网络保证感受野不受影响,此外,更多的跳连接结构提供更多不同尺度的信息,有效提升了分类正确率;3) 注意力机制保证了网络不受序列长度的影响,并且通道注意力的加入对建模视频长期依赖性又提升了一个高度。

Table 3. Comparison of DCMAN model with other methods
表3. DCMAN模型与其他方法对比
4.4. 消融实验
本节评估DCMAN模型相关的变种模型的表现,以证明相关组件的影响。为了简捷起见,只在未增强数据设置下进行实验。探究了三种变体模型DCMAN (FSCN),DCMAN (w/o-CA),DCMAN (Q = P)。第一个代表使用文献 [14] 中的FCSN模型替代DCMAN中的空洞卷积结构。第二个代表去除DCMAN中通道注意力结构。第三个代表使用空洞卷积网络的输出P作为初始化查询向量Q的网络结构。三个变种模型的效果如图4所示。DCMAN (FSCN),DCMAN (w/o-CA)的表现都没有DCMAN好,证明了DCMAN模型空洞卷积网络结构和通道注意力能更好提升模型性能。DCMAN (Q = P)的表现不如DCMAN说明本文用原始特征F初始化查询向量Q确实能获得更完整的视频信息。

Figure 4. Comparison of the effect of DCMAN’s variant models
图4. DCMAN的变种模型效果对比
4.5. 参数分析
本节针对DCMAN设置不同膨胀系数的情况下,对模型的表现的影响进行了实验。为了简捷起见,只在未增强数据设置下进行实验。结果如表4所示,刚开始随着膨胀系数增大,效果也越好,这得益于模型能提取到更丰富的上下不同尺度的信息,但当膨胀系数进一步增大时,如表4第四行所示,模型表现下降,本文分析这是由于随着膨胀系数增大,为保证输入特征图大小尺寸不变,padding也要随之增大,导致模型提取到许多无效的信息。最终实验结果表明当膨胀系数为[1] [6] [12]时,取得最佳表现。
Table 4. Effect of different expansion coefficients on the model
表4. 不同膨胀系数对模型的影响
5. 结束语
本文提出一种级联空洞卷积的多维度注意力视频摘要网络DCMAN。其中级联空洞卷积结构提取视频的全局表示以及捕获了视频数据的短期依赖,该网络不包含了重复的下采样以及最大池化操作,最大程度保证了视频的细节信息的保留,同时通过设置合适的膨胀系数扩大网络的感受野。在级联空洞卷积网络后融入了空间与通道注意力机制,捕获了视频信息的长期依赖。最后在四个公共数据集上验证DCMAN模型的性能,实验结果表明,优于其他最新方法以及基线模型。
本文设计的模型仍有不足之处,模型结构过于庞大,导致训练时间长,在未来的工作中需要考虑在不影响模型性能的前提下,缩小模型的结构。同时考虑应用更多先进的语义分割模型在视频摘要领域。