1. 引言
随着社会的进步与发展,人们对于科技的要求水平逐步增高。在人们日常生活中,物品识别抓取工作已然成为了新型工业、物流分类、无人车间、快速作业等领域必不可少的重要环节 [1] 。科技不成熟时,工厂普遍使用较为落后的分拣作业方法——利用大量人工进行物品分类堆积。此方法虽然满足了就业需要,但也暴露了效率低、错误率高的弊端 [2] 。赋予机械手更加智能化的操作成为了当今世界国内外研究的热潮,而对物体的目标识别及定位技术更是智能化的重中之重。依赖于计算机算力的提升,深度学习已经逐步取代了传统的机器学习,识别准确率极大地提升,机器视觉也随之得到了更好地发展。
为了提高机械手对于物体的检测能力并能够准确将物体抓取到特定区域,本文选用Yolov5算法进行识别,使用型号为Astro Pro的相机搭建单目结构光系统获取深度信息,实现物体的三维空间定位。工作流程为:对单目结构光相机采集到的数据集进行标注后,搭建PyTorch环境,使用Yolov5模型进行训练,将散斑图与参考平面散斑图使用SGBM算法进行图像匹配获取视差图,将视差图转深度图,深度图转点云图,得到物体三维坐标,最终实现抓取。
2. Yolov5算法原理概述
当今流行的目标识别算法大多分为one-stage与two-stage两类,two-stage算法代表是R-CNN [3] 系列,one-stage算法代表是Yolo [4] 系列。two-stage算法将两步分别进行,原始图像先经过候选框构成网络,例如Faster R-CNN中的RPN网络 [5] ,再对候选框的内容进行分类;one-stage算法将两步同步进行,输入图像只经过一个网络,生成的结果中同时包含位置与分类信息。two-stage与one-stage相比,虽精确度提高,但运算量增大,速度慢。
Yolov5是一种端到端的深度学习模型,可以直接从原始图像中检测和定位目标。它使用卷积神经网络(CNN)来学习图像中物体的特征,并使用多尺度预测和网格分割来检测和定位目标。Yolov5在Yolov4 [6] 的基础上进行了改进,是其工程化的版本。Yolov5给予使用者了10个不同版本的模型,差异点在于网络的深度和宽度,其模型各项参数如图1所示。
我们可以将Yolov5算法的结构划分为四个部分:输入端、骨干网络(Backbone)、颈部网络(Neck)、预测输出(Prediction)。Yolov5算法整体结构如图2所示。
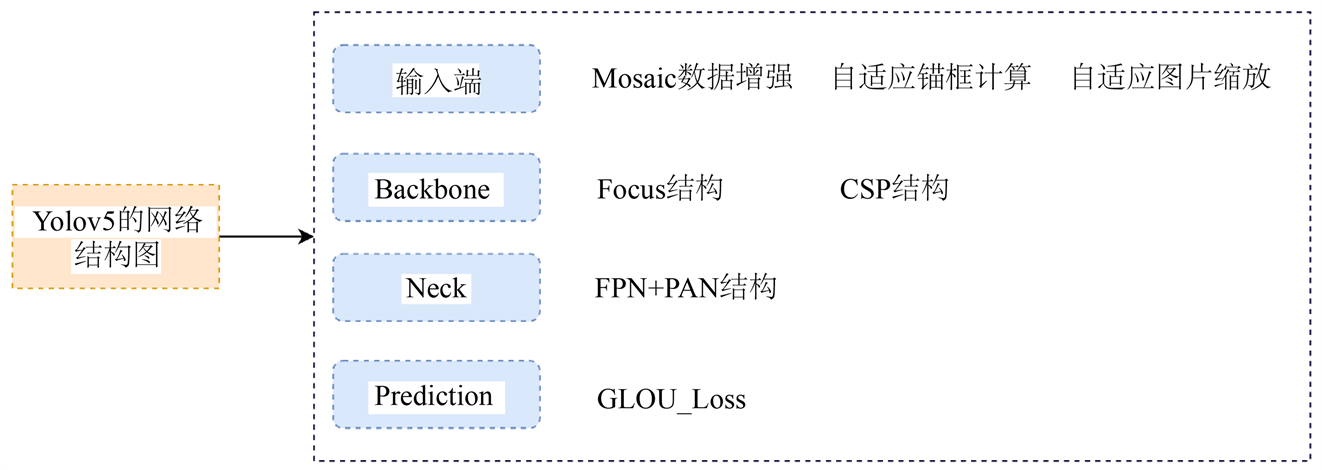
Figure 2. Overall structure of Yolov5 algorithm
图2. Yolov5算法整体结构
输入端:Yolov5算法相较于基本的数据增强方法,改进为将1~4张图片进行随机裁剪、缩放,随后随机拼凑生成一张图片,增加目标数量,提升训练速度,降低内存需求。新增自适应锚框计算、自适应图片缩放的方法,训练时根据所选择数据集的不同,自动调整所需锚框的长宽值,并将其进行更新,填充灰色,预测时缩减黑边,使得特征提取更加快速。
骨干网络(Backbone):骨干网络用于提取特征,并不断缩小特征图,设计了Focus结构 [7] 和CSP结构。对于Focus结构,图片进入Backbone前,对图片进行切片操作,在图片中每隔一个像素取一个值,类似于邻近下采样,通过此操作拿到4张互补的图片,将W、H信息输入通道,即原先图片的RGB三通道模式变成了进行拼接后的12个通道模式的照片,最后将得到的新图片再经过卷积操作,最终获取到没有信息缺失情况下的二倍下采样特征图。相较于Yolov4中只有在骨干网络中使用了CSP结构,Yolov5则设计了CSP1_X结构使用在骨干网络,其外的CSP2_X结构使用于颈部网络中,将原输入分成两个分支,分别进行卷积操作使得通道数减半,通过残差结构再次卷积,将两个分支通过融合后进行正态分布,激活后进行CBS,使得模型学习到更多的特征,增大感受野 [8] 。
颈部网络(Neck):颈部网络通常位于骨干网络与Head模块之间。图形特征来源于卷积神经网络浅层的特征,如颜色、轮廓、纹理、形状等;语义特征来源于卷积神经网络深层的特征,语义性虽强但却丢失了简单图形。Neck结构就实现了浅层图形特征和深层语义特征的融合,使特征图的尺度变大,以便获取更加完整的特征。Yolov5算法中将SPP更换成了SPPF,并在Pan结构中加入了CSP。进一步提升了算法模型对于不同大小图片的检测。
预测输出(Prediction):head层为Detect模块,由三个1 * 1卷积构成。通过升维或降维,增大感受野,增加通道数,获取更多浓缩的特征信息。搜索局部极大值,消除重叠部分,获取最佳边界框。消除gird敏感度,通过CIOU_LOSS损失函数计算损失值,输出预测结果。
3. 单目结构光
随着机器视觉、自动驾驶、无人车间等颠覆性技术的逐步发展,采用3D视觉技术进行物体识别、场景建模等方面的应用越来越多。相机模组部分直接等同于机械手的眼睛,普通的RGB相机所拍摄的图片只能简单获取二维平面的信息,仅仅只能从图像语义中得知距离远近,若想要还原真实场景,增加机械手的智能性及准确性,我们还需要获取到物体距离相机距离的真实数据,从而通过结合图像中每个点的像素信息,获取三维空间坐标。在3D视觉技术中主流的三大类分别是:结构光(Structured-light)、双目视觉(Stereo)和飞行时间法(TOF)。基于结构光的构成如图3所示。
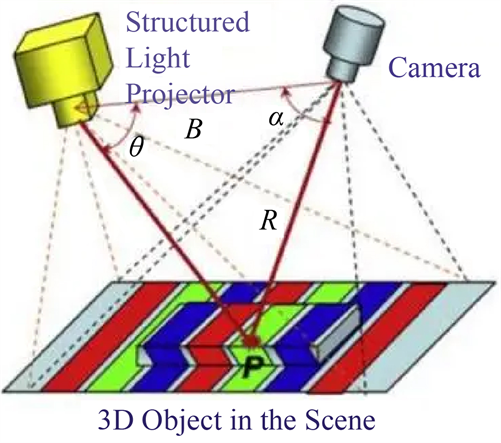
Figure 3. Composition of Structured light
图3. 结构光的构成
不论是双目算法还是结构光算法,从历史发展角度出发,其基本物理原理都是基于双目三角法。单目结构光法由简单的单目图像处理深入,其发展基于三角测量技术 [9] [10] 。其处理过程为,利用红外线激光机,将不同特征结构的不可见红外光线透过掩膜投影到空间物体上,再根据物体所处位置的深度不同,通过红外相机收集到不同图像的相位信息,最后通过运算单元讲这种结构的变化换算成深度信息。单目结构光优势在于条件成熟,所需硬件体积小,测量视野较大,并且范围内精确度较高。本文采用散斑结构光的方法对邻域内的散斑分布实现空间编码,如图4所示,展示了散斑结构光的数学模型。
其中object为物体表面,reference plane为参考平面,P点为红外激光发射机位置,C为IR相机位置,CP为红外激光发射机和相机所处的平面,C点和P点之间的距离b为基线长度,设定红外激光发射机和
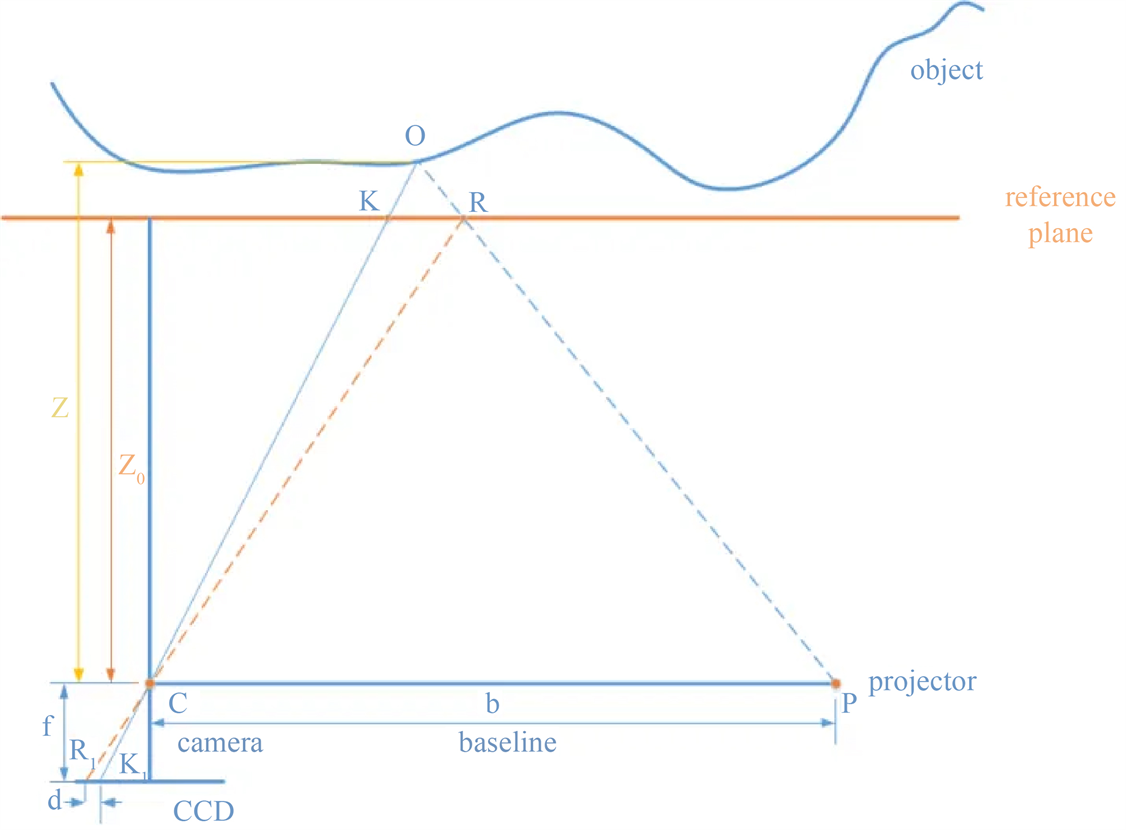
Figure 4. Mathematical model of speckle Structured light
图4. 散斑结构光的数学模型
IR相机的连线与参考平面平行。由红外激光发射机透过掩膜投影到被测空间物体的O点上,处于不同距离的发射的散斑被IR相机所捕获,此时在IR相机光心中拥有两个成像点
、
,
为射线PO照射到被测物体反射的散斑成像点,与参考平面相交与K点,
为发射的同一射线PO在不同距离下反射的散斑成像点,与参考平面相交与R点,
、
两个不同像素点之间的距离d为视差。根据固定可知参数:焦距f、参考平面与基线平面之间距离 、基线长度,以及根据匹配算法求得的视差d,利用三角测量技术可以得到物体上O点到相机平面的深度Z。
运用相似三角形定理,根据△RKC∽△R1K1C,可以得到公式:
(1)
由△OKR∽△OCP,可以得到公式:
(2)
联立公式(1)与公式(2),可以得到深度公式,完成深度测量:
(3)
结构光系统中,系统标定将直接影响测量的准确性。相机标定要完成由像素坐标系–图像坐标系–相机坐标系–世界坐标系的转换,为此,可以利用数学推导公式实现将空间中任意一点的坐标转换为像素坐标,在上述坐标系的基础上,坐标(u, v)就是像素所在的行和列,设点O(u, v)为像素坐标点,代表像素的行数和列数,在世界坐标系中的任意一点P(Xw, Xw, Zw),在相机坐标系中对应点P(Xc, Yc, Zc),P点由像素坐标系转换至世界坐标系的完整推导公式如下:
(4)
公式对应参数:f为焦距,
、
表示图像坐标系原点相对像素坐标系原点的偏移量,R为旋转矩阵,T为偏移矩阵,N为相机内参矩阵,M为外参矩阵,NM为相机坐标系到世界坐标的转换矩阵 [11] 。
4. 实验结果及分析
4.1. 目标识别实验
基于Yolov5的目标识别需要创建一定数量的数据集进行训练,利用本文所提出的单目结构光深度相机,通过根据物体摆放位置的不同以及相机支架开合角度的不同,对被测物体进行拍摄,选取1000张图片制作成为所需数据集,利用标注软件进行信息标注,将标注后的数据集按照8:2的训测比分配,训练使用线程数为10,循环次数设为100,输入图片大小设置为640 * 480,选用Yolov5s模型,所用CPU为AMD Ryzen 7 5800H with Radeon Graphics,GPU为NVIDIA GeForce RTX 3050 Ti Laptop GPU,深度学习框架为pytorch。
实验统计量由Accuracy (准确率)、Precision (准确率)和Recall (召回率)组成。最终实验结果由mAP (平均精度均值)进行度量,其数学公式为:
(5)
简单来说,mAP是准确率和召回率构成的PR关系曲线的下方面积,越接近于1,代表模型的效果越好。图5为训练获得的Precision和Recall对比图,可以看出随着训练次数的增加,数值最终归于平稳,并且趋近于1,得到的mAP值达到96.5%,准确性较好。
4.2. 相机标定
利用张正友标定法对相机进行标定,OpenCV对于该算法进行了优化,可直接利用OpenCV使用棋盘格板进行标定,得到本文所使用的相机参数如表1所示。
4.3. 定位技术实验
结构光算法的核心在于将散斑图与参考平面散斑图进行图像匹配,通过匹配代价计算–代价聚合–视差计算–视差优化/后处理四个步骤的技术寻找到像素的视差,使用OpenCV库中的SGBM半全局匹配
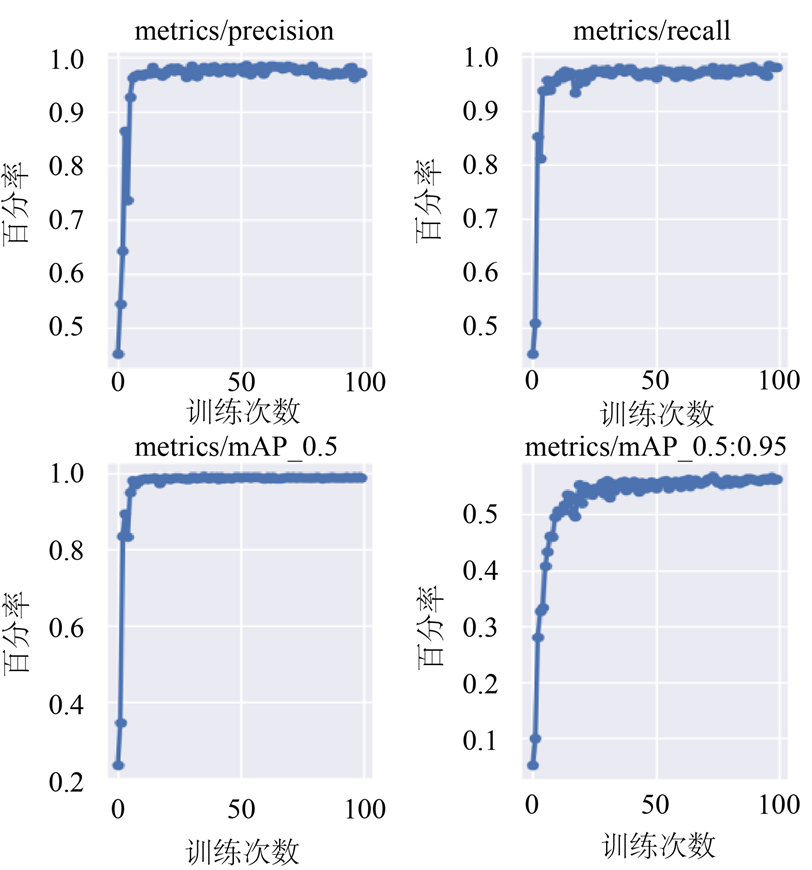
Figure 5. Precision and Recall comparison chart
图5. Precision和Recall对比图

Table 2. Comparison of positioning accuracy between monocular Structured light system and binocular system
表2. 单目结构光系统和双目系统定位精度对比结果
算法最终可以有效地得到Z轴上的深度信息。实验时将物体放置于不同位置,使用单目结构光系统和双目系统定位精度对比结果如表2所示。结果表明单目结构光系统相较于双目系统的定位平均误差更小,定位效果更好,且结果符合抓取要求。
5. 总结
本文提出的基于目标识别与定位技术的机械手的系统,为机械手准确抓取物体提供了支持,利用Yolov5算法提高识别准确率,并在其基础上引入单目结构光系统完成物体的三维定位,最终实现空间物体的识别与抓取,通过实验表明该系统能够较好地满足抓取要求。