1. 引言
随着我国全民生活水平逐步提高,消费结构不断优化升级,加上二孩政策、三孩政策陆续放开,人口老龄化程度进一步加深,居民对家政服务业的需求明显增加,在“互联网+”浪潮影响下,家政服务业的市场规模得到了迅速的扩张。服务内容及质量已经成为消费者选择家政公司的重要指标,这对家政服务企业提出了更高的要求。现如今家政行业门槛仍然偏低,服务人员的文化水平普遍不高,企业对服务人员的专业素质和服务质量缺乏有效的监管,这也导致顾客满意度欠佳,难以建立企业与顾客之间的信任度与忠诚度的问题 [1] 。
随着互联网和大数据等信息技术的进步,家政服务企业开始了数字化转型升级。家政员工的接单情况全程通过家政APP操作完成,其个人信息和服务情况也以数字化的形式记录下来,形成了具有一定规模的样本数据,这也为机器学习算法提供了良好的数据基础。因此利用机器学习算法展开家政服务员的顾客满意度预测研究,能够弥补传统研究的局限,深入探讨影响满意度的特征变量关系,并为服务行业和行为管理建立新的理论。
本文围绕家政行业的满意度问题,深入探究机器学习算法在服务行业的运用与创新,基于随机森林算法构建顾客满意度预测模型,实现从“事后打分”到“事前预测”的研究。与以往研究不同,本文基于现实工作流程,将属性划分为服务前和服务后的两个类别,对影响顾客满意度的诸多特征因素进行重要度排序,为家政服务人员的筛选及满意度预警提供必要线索和理论支持。
2. 文献综述
目前顾客满意度理论已经趋于成熟,国内外也逐渐建立起了衡量顾客满意度指数的体系 [2] ,学者对顾客满意度已经进行不同的诠释并展开研究 [3] [4] [5] ,家政服务员的顾客满意度定义为顾客对服务人员提供的家政服务的主观感受,其反映的是消费者心理预期和感知程度的差值。要提升家政行业的顾客满意度,必须加强行业的规划化管理,提升家政服务人员的自身素养 [6] [7] 。越来越多的学者从服务人员本身的胜任素质出发,发现学历、年龄、文化水平等特质对家政从业人员的心理健康具有重要影响 [8] [9] ,此外家政从业人员的胜任力具有共同的特征,主要包括知识技能、个人能力、职业道德、人格特质 [10] [11] [12] ,会对服务质量及顾客满意度产生重要影响。
互联网家政企业意识到家政服务质量的重要性,建立起顾客评分制度,试图规范家政人员的服务质量,但这样的事后打分只能对员工起到一定的约束作用,却对顾客的实际流失无济于事。如果能在员工正式服务前,通过技术或理论提前甄别筛选满意度欠佳的员工,并且加以针对性的培训,能够有效改善服务质量,提高满意度。
要实现从事后打分到事前预警的迈进,需要从家政服务员现有的信息数据以及顾客的评分信息中进行分析,筛选重要度较高的特征变量,从而为提前甄别筛选满意度欠佳的员工奠定理论基础。为此,学者运用logistic模型或结构方程模型,构建影响顾客满意度的测评模型,并验证假设的正确性,从而梳理出影响顾客满意度的关键因素 [13] [14] ,如于小飞结合ECSI和CCSI模型,提出家政服务标准化对顾客满意度影响的指数模型,发现标准化服务预期、顾客感知标准化服务质量、顾客感知标准化服务价值、企业形象这四个潜变量对于顾客满意度有正向影响 [15] 。然而,这类研究主要从服务对象的角度出发,构建专业测评量表,存在研究视角的局限性,且量表测评的准确性受测评对象的主观影响。
机器学习算法能够对多种类型的数据进行学习训练,能够通过属性筛选和参数调优提升模型性能,并给出预测结果;结合SHAP模型,能够分析特征变量的预测能力以及变量间的交互关系,为事前预警奠定良好的理论基础。目前基于大数据算法的顾客满意度预测研究已经覆盖到诸多领域,并证明了机器学习算法的可行性。张蓓蓓等通过使用网格搜索算法对随机森林的决策树数量和候选分裂特征属性数进行优化调参,改进随机森林的不足,有效预测了餐厅的客观满意度评分 [16] 。赵家胤应用随机森林算法建立客观的满意度评价模型,对华为商城手机购物满意度的评价数据进行分类预测,展现了良好的性能 [17] 。Chen等根据能源消费者的历史消费数据对其下一个小时的负荷是高还是低进行了预测研究,采用十折交叉验证和5次运行取平均的方法进行实验,表明随机森林算法在速度和分类精度方面的性能均优于其他常用的机器学习技术 [18] 。过往的研究证明了机器学习算法在满意度预测研究上的可行性和有效性,而随机森林算法拥有诸多优势,因此本文以Y公司的家政服务员为研究对象,从事前角度出发,利用随机森林算法构建顾客满意度预测模型,并结合SHAP模型分析影响顾客满意度的特征。
3. 数据来源与分析
3.1. 数据来源介绍
本文数据来源于Y家政公司后台真实数据,原始数据集共1239条数据,包含20个特征变量,经过数据预处理后,共计15个特征变量,其中主要包含家政服务员的基础身份信息、服务行为信息、心理测评信息等变量,目标变量为服务满意度评分。属性信息描述如表1所示。

Table 1. Description of attribute information
表1. 属性信息描述
3.2. 相关性分析
利用python绘制数值型变量的相关系数热力图。如图1相关系数热力图所示,注册时长、技能数量、请假次数等变量的相关系数强弱会通过颜色的深浅展现出来,颜色越浅说明相关性越弱。如果相关系数过高,会影响特征对模型重要性的判断。根据Pearson相关系数定义,当两项特征的Pearson相关系数大于0.7时,则为高度线性相关,即存在高度共线性关系 [19] 。观察热力系数图可知,注册时长、技能数量、请假次数、准时率等变量的相关系数绝对值均低于0.7,说明大多数变量不存在多重共线性的问题,因此本文选取的变量较为妥当,可以将变量纳入后续的机器学习建模实验当中去。
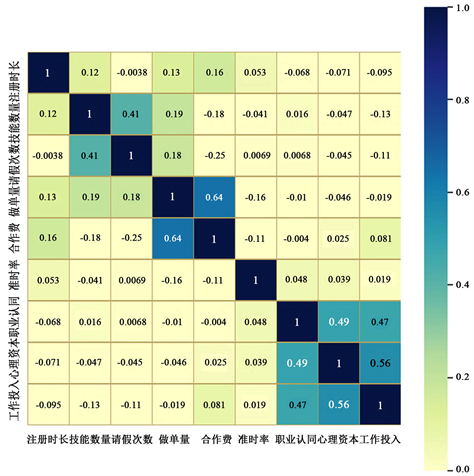
Figure 1. Correlation coefficient heat map
图1. 相关系数热力图
4. 家政服务员的顾客满意度预测模型建立
随机森林是基于决策树而建立的一种集成预测模型,它集成了多个决策树,每一个决策树对于独立取样的随机向量值均具有一定的依赖性,且随机森林中的所有决策树均具有相同的分布 [20] 。许多实验表明,相对于其他机器学习算法,随机森林算法对样本和特征变量随机选择,对数据质量要求低,对异常值与噪音具有高容忍度,更适合具有多维度、多特征和特征值离散的数据 [21] 。因此本文选择随机森林算法构建预测模型。随机森林算法会采用有放回重新采样的方法抽取N个训练集,每一个训练集将会形成一棵决策树,最终根据决策树的多数投票结果,决定最终分类结果,随机森林过程如图2所示:

Figure 2. Process diagram of random forest algorithm
图2. 随机森林算法过程图
根据属性特征将属性分为基础属性特征子集和融合心理行为特征子集。基础属性特征子集只包含了家政服务员的基础身份信息,而融合心理行为特征子集则加入了家政服务员做单后的行为信息与心理测评信息。依次纳入这两种特征子集来构建预测模型,同时选择顾客满意度作为预测变量,从而对比不同属性特征子集的建模效果和性能。两种模型的特征子集如表2所示。
Table 2. Comparison of attributes of the two feature subsets
表2. 两种特征子集属性对比
将经过预处理的数据按照8:2的比例随机分为训练集和测试集,对随机森林算法采用网格搜索法进行参数调优,获取最佳模型效果,依次构建预测模型。测试集中的真实值和预测值均存在正负两种情况,所以,最后得到的分类结果存在四种情况。本文采用准确率、查准率、查全率、F1度量值、特异性、AUC值来对比分析模型性能。
(1)
(2)
(3)
(4)
(5)
不同属性特征集的随机森林模型性能指标如表3所示。模型在基础属性测试集和融合心理行为测试集上的准确率分别为64.29%和83.21%,两个模型识别的正样本可信度都较高,F1度量值为62.69%和82.13%,基于基础属性的特征集AUC数值为70.45%,远低于融合心理行为属性数据集的AUC数值90.16%。在各项指标上,融合心理行为属性的随机森林模型性能都明显高于基于基础属性的模型性能。这说明在家政服务员的满意度预警问题上,不能仅仅关注基础信息,更要充分考虑员工的心理和行为信息。
Table 3. Comparison of performance indicators of random forest models constructed with different attribute feature sets
表3. 不同属性特征集构建的随机森林模型性能指标对比
5. 顾客满意度预测模型影响特征发现
5.1. 基于全部属性的模型特征重要性发现
Lundberg和Lee提出的SHAP框架计算每个特征对预测的贡献 [22] 。其主要原理为基于博弈论而提出的Shapley值可用于衡量各特征分别对于模型预测效果的作用 [23] ,利用SHAP框架得到的全部特征重要性排序如图3所示,其重要性从第三位和第八位起显著降低,前八位分别是:做单量、合作费、星级、准时率、请假次数、注册时长、来源、技能数量。这说明做单量、合作费、星级、准时率是预测家政服务员顾客满意度的关键特征。
5.2. 基于属性划分的满意度预测特征发现
将全部属性纳入到随机森林模型进行学习后发现,重要程度较高的属性往往是服务后产生的信息,服务前的信息重要性排名靠后,这将导致贡献度低的特征信息将会被掩盖或合并,无法看到其真正的价值和意义。这样的数据处理方式也缺乏对现实工作流程的理解。如果员工没有在家政APP上接单,那么服务后的信息就会处于缺失状态,那就不能为家政公司的管理者提供信息依据和决策支持。因此基于现实和数据层面,本文提出基于工作流程对家政服务员的信息数据进行属性划分,丰富数据刻画维度。根据家政服务员的工作流程和时间节点,本文将一个样本中的全部属性划分为服务前信息、服务后信息和心理测评信息。划分类别如表4所示。
如表5所示,在基础身份信息类,技能数量是预测顾客满意度的最为关键的特征,其次是注册时长、户籍、学历,这三者是重要特征。在考勤薪酬信息类属性中,合作费、做单量的重要性分数值不相上下,是预测顾客满意度的最为重要的属性,这两个属性能够直接反映出员工在服务过程中的投入程度和劳动所得,此外请假次数和准时率均有重要的相关度。
从模型准确率来看,以不同类别的属性依次纳入到随机森林模型中训练学习,对比其他四组实验的模型准确率,以全部属性作为输入变量构建的模型分类准确率最高,为0.83,这能够说明三类属性类别缺一不可,全部属性才能最大化地提升模型性能。其次,考勤薪酬信息类和心理测评信息类的实验准确率紧随其后,其准确率与全部属性准确率仅相差0.01,说明了这两个类别的属性结合对分类实验的准确率有十分重要的影响。
Table 5. Different categories of attributes compare experimental results
表5. 不同类别属性对比实验结果
5.3. 基于SHAP模型的顾客满意度影响特征发现
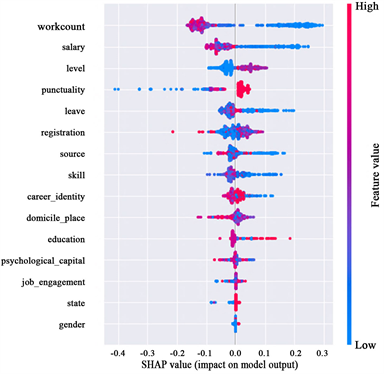
Figure 4. SHAP summary diagram for all samples
图4. 所有样本的SHAP概要图
为了探究多个因素共同作用下对顾客满意度的影响,运用SHAP模型计算了多变量交互作用下的SHAP交互值,并分析了变量对模型的影响方向。如图4所示,做单量和合作费对模型的影响最大。两项特征的红点主要位于Y轴的左侧,这表明这两项变量特征值较大时,其SHAP值为负值,反之特征值较小时,其SHAP值为正值,这说明做单量越大,合作费越高,越可能获得不佳的顾客满意度,这一点看似不寻常,会在做单量和星级的交互关系上进行探讨。星级和准时率对模型的影响次之,这两项特征的红点主要位于Y轴的右侧,这表明星级和准时率的特征值较大时,其SHAP值为正值,对于模型的影响也较大,蓝点主要位于Y轴的左侧,这说明星级和准时率的特征值较小时,其SHAP值是负值,对模型结果产生正向影响。注册时长的红点更多集中在右侧,特征值较大时,SHAP值为正,这说明注册时长越长,员工越有可能获得更高的满意度评价。
特征与特征不是互相割裂的关系,彼此之间也存在交互效应,从而会共同影响预测结果,交互效应即两个特征变量同时影响模型输出的方式 [24] 。为了进一步地探究变量间的交互关系,本文筛选出星级和做单量两个特征变量来绘制依赖图。家政公司管理层依据其专业水平和能力,依据星级将家政服务员主要分成一星、二星、三星服务员。如图5所示,星级较低的家政服务员,红色样本主要落在SHAP值为负的区域,星级较高的家政服务员,红色样本主要落在SHAP值为正的区域,这说明低星级的家政服务员,做单量越高,越有可能获得较低的顾客满意评价,而高星级的家政服务员,做单量越高,越有可能获得较高的顾客满意评价,这也解释了做单量对顾客满意度的影响。家政公司需要着重关注低星级且做单量高的家政服务员,针对性提供培训服务,提高其顾客满意度评价。
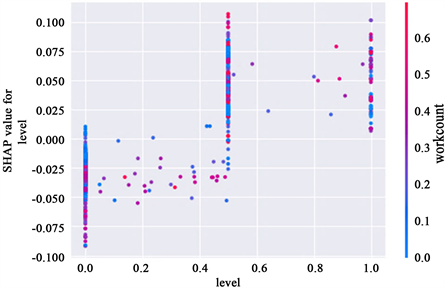
Figure 5. Interaction diagram between level and work count
图5. 星级与做单量的交互图
6. 结语
本文基于随机森林算法,针对基础属性特征子集和融合心理行为属性特征子集,依次构建了家政服务员的顾客满意度预测模型,并提出了基于工作流程的属性划分方法,探讨了在服务前后的不同阶段,预测顾客满意度的重要特征,并引入SHAP框架分析了特征对模型的影响以及特征间的交互关系。
从理论贡献的角度来看,过往的研究从事后测评的角度出发,通过结构方程模型或相关性分析来论证假设,梳理影响满意度的因素,本文从事前预警的角度出发,构建顾客满意度预测模型,论证了融合心理行为属性的必要性,并结合可解释性框架对特征变量的重要程度进行排序,并基于工作流程,将属性划分为不同类别,依次归纳出影响顾客满意度的重要特征变量,提供了新的研究思路,拓宽了家政服务业的顾客满意度领域的研究方法。
从实践意义的角度来看,本文分不同阶段探究了影响顾客满意度的不同因素,为服务行业管理提供理论支撑和实践价值。通过家政服务员顾客满意度的预测模型特征重要性排序可知,做单量和合作费、星级、准时率等属性是预测顾客满意度的关键特征。而在服务前阶段,技能数量是预测顾客满意度的最为关键的特征,在员工接单前,家政公司可以根据家政服务员的技能情况来衡量工作情况,并重点关注员工的技能培训情况;在员工接单后,家政公司需要关注低星级且做单量高的家政服务员,提供针对性帮扶情况,改善顾客满意度评价。家政公司后台系统精准详细地记录了员工的信息数据,管理层可以依据做单量、合作费、准时率、星级这些重要信息特征,建立预警机制,从而对满意度欠佳的员工展开针对性的培训,提升培训效果,减少客户流失,建立顾客忠诚度,提高企业的核心竞争力。
随着人工智能的发展,大数据算法的应用领域越来越广泛,本文结合机器学习算法和SHAP模型,更全面地衡量不同阶段内属性特征的价值意义,帮助企业识别筛选满意度欠佳的家政服务人员,改善培训效果,提高顾客满意度,也期望未来的研究能够聚焦于更多的数据,结合不同的算法来提升模型性能,从多个角度探究影响顾客满意度的特征因素,从而为服务行业的管理和发展持续赋能。
基金项目
上海市哲学社会科学规划一般课题“考虑数据伦理的入户服务人员行为风险状态分类研究”(项目编号:2020BGL007)。