1. 引言
分类是一种重要的数据挖掘技术,其目的为根据数据集特点构造相应的分类模型,过程一般分为训练和测试两个阶段 [1] 。现有的成熟分类算法主要有:以实例为基础的归纳学习算法决策树 [2] [3] [4] ;基于概率论统计的贝叶斯分类算法 [5] [6] [7] [8] ;以实例为基础的懒惰学习算法k-Nearest Neighbor (KNN) [9] [10] [11] ;训练分界函数过程较为简单的逻辑回归 [12] [13] [14] ;训练分界函数过程较为复杂的神经网络 [15] [16] [17] 等。现阶段分类算法研究方面,杜景林提出了一种基于距离权值的C4.5组合决策树算法 [18] ;童先群提出了一种基于属性值对类别重要性的改进算法Entropy-KNN [19] ;这些改进算法都在一定程度上考虑了数据集的分布情况,但仍未能充分利用不同类别不同特征的数据集的分布信息。
本文提出一种基于特征熵权的集群分类算法,它不再以单个样本为分类研究对象,而以不同类别的数据集群为分类研究对象。训练时,根据标签将数据分为若干集群,后使用信息熵权重表示不同类别数据的特征分布情况 [20] [21] [22] 。测试时,若数据已经分为若干集群,则直接通过余弦相似找出训练集群中特征分布最为接近的集群,从而判断类别。若数据未分为若干集群,则先根据训练集群数进行聚类,再按余弦相似找出各个测试集群所属类别。实验证明本算法在不同类型数据分布差异较为明显时,有着较高的准确率,且比起现有分类器,本文所提算法对错误数据不敏感,一定程度上解决了人为标签容易出错的问题。
2. 基于信息熵的特征分布向量表示
熵的概念源于热力学,是对系统状态不确定性的一种度量。1948年Shannon提出“信息熵”的概念,解决了对信息的量化度量问题。信息熵(entropy)是一种描述随机变量分散程度的统计量,信息熵越大,表示变量的离散程度越高 [23] 。
本文利用信息熵对分类问题中,不同类别的数据分布进行度量,从而将各类数据的分布情况量化。
2.1. 信息熵
信息熵是系统无序程度的一种度量,信息熵越小,无序度越低。设X为服从某种分布的随机变量,其信息熵为:
(1)
其中X取值
,
为X取值
的概率 [24] 。
2.2. 熵权与特征分布
基于信息熵的特征分布表示,以最常见的高斯分布为例。设一可分为m类的数据集中,每个样本存在k个特征,且任意特征
均服从位置参数为
、尺度参数为
的概率分布,则其概率密度函数为:
(2)
特征
的信息熵为:
(3)
其中
,n为任一类数据的样本数。
若
,则有:
为增加不同类别样本间各个特征熵值可比较性,本文使用熵权表示数据变化剧烈程度的差异。对于任一类别,特征
的权重为:
(4)
计算不同类别数据所有特征的熵权得特征熵权向量:
(5)
其中
;
。
2.3. 基于熵权的特征分布合理性仿真实验
分类器应尽可能的区分不同类别样本间数据的差异性,对于本文所采用的权重向量表示不同类别样本,应当使不同特征间权值差异尽可能的大。
设
为同一类样本的特征集合,且
服从高斯分布(2)。
令
,生成样点数num = 4000。采用控制变量法,分别研究三种参数变化对熵权变化影响情况。
2.3.1. 位置参数μi对权重分布的影响
令
,v从0~100进行迭代,
固定不变,按2.2中过程生成特征熵权,如图1。
由图1可得,当δ固定时,不同特征间相差较小的μ可以获得较大的熵权差异。
2.3.2. 范围参数δ对权重分布的影响
令
,v从0~100进行迭代,
,按2.2中过程生成特征熵权,如图2。
由图2可得,当μ固定时,不同特征间相差较小的δ可以获得显著的熵权差异。
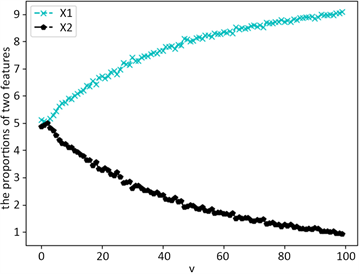
Figure 1. Weight changes with location parameters
图1. 权重随位置参数变化情况

Figure 2. Weight changes with range parameters
图2. 权重随范围参数变化情况
2.3.3. 范围参数δ对权重分布的影响
固定
、
,
、
。随机生成样本数num = 500,且num = num + 10 * v,v从0~2000进行迭代,并按2.2中过程生成特征熵权,如图3。
可以看出,当随机生成样点数较少时(500左右)权重有较大随机性,相对容易出现误判,但不同特征之间权值依然有较大差别。对于不同类别的样本集群,仍将具有良好的分类能力。且随着数据量增加这种随机误差将不断减小。
从以上的仿真实验可以看出,用熵权表示不同类别数据之间的分布差异是合理的。
3. 集群分类器
现有分类器多利用单个数据的信息进行训练与测试,而忽略了不同类别、特征数据集之间的分布信息。本文所提出集群分类器以不同类别、特征之间熵权差异为基础,进行数据集的分类。
集群分类算法,首先根据标签将训练集划分为不同类型的集群,再按2中所述计算出各类样本特征熵权向量。测试时,若数据已经分类,则直接计算测试集群特征熵权向量;若未分类,则根据训练集标签类数进行聚类。随后将训练集群的特征熵权向量与测试集群的特征熵权向量进行余弦相似匹配。整体算法流程如图4。
3.1. 高斯混合聚类
当测试集未能分为集群给出时,首先需要对测试集进行聚类。由不同类别的特征分布之间的差异性可知,集群分类的主要误差产生于聚类过程,本文中采用高斯混合模型(GMM)完成聚类。对GMM进行简要介绍:
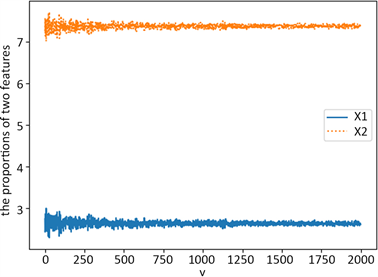
Figure 3. Weight changes with the number of samples
图3. 权重随样点个数变化情况

Figure 4. The Algorithm flow of cluster Classification Algorithm Based on Feature Entropy Weight
图4. 基于特征熵权的集群分类算法
设随机变量X服从
,则混合高斯模型可以用下式表示:
(6)
其中,
是系数,
;
是高斯分布密度,
且:
(7)
3.2 集群间的余弦相似匹配
假设根据标签将训练集数据分为m个集群,且特征数为k。对训练集群求特征熵权得矩阵
:
(8)
其中行为不同的集群,每列为不同的特征熵权;
为第p个集群,第q个特征的熵权;
为第p个集群的特征熵权向量。
求m个集群特征熵权向量的模向量得:
(9)
同理,求测试集群的特征熵权矩阵
:
(10)
特征熵权向量的模向量b
:
(11)
定义向量
和
间的余弦相似度为:
(12)
从而可得训练集群与测试集群的余弦相似矩阵:
(13)
其中cos为一个
的矩阵。每一行代表一个训练集群,每一列代表一个测试集群。要求测试集群与训练集群的余弦匹配只需求cos中每一列的最大值对应的训练集群即可。
3.3. 算法步骤
基于特征熵权的集群分类算法步骤如下:
Step 1:将数据分为训练集与测试集,假设数据类别数为m,特征数为k。训练集中根据标签,将不同类别的样本划分为m个集群;
Step 2:根据
计算m个集群k个特征的信息熵。对m个集群求各特
征熵占比
,得m个特征熵权向量
。并以行为集群,列为特征,由
组合成特征熵权矩阵
,并计算每个集群特征熵权向量的模,放入特征熵权向量的模向量
;
Step 3:输入测试数据,并判断测试数据是否已经分成不同集群,而只需要判断集群所属类别,若是转Step 5;若否,则转Step 4;
Step 4:使用聚类算法,将测试数据聚成m个集群。
Step 5:根据熵权计算测试数据m个集群k个特征各自分布,得m个特征熵权向量
。并以行为集群,列为特征,由
组合成特征熵权矩阵
,并计算每个集群特征熵权向量的模,放入特征熵权向量的模向量
;
Step 6:由
得训练集群与测试集群的余弦相关矩阵。找出每一列中余弦相似的最大值,即得该列所代表测试集群对应的训练集群类别。
4. 仿真结果及分析
4.1. 实验设计及参数设置
为了增强与其它分类器的可对比性,在此仿真实验中不考虑测试数据在采样时已经分为不同集群的情况。以二维特征为例,按正态分布生成两类数据集:
第一类
、
;
、
;第二类
、
;
、
。
随机生成两类数据各500个,如图5。
按上述分布再次生成两类测试数据集各500个,如图6。

Figure 5. Two types of training set data
图5. 两类训练集数据

Table 1. The comparison of different algorithm
表1. 不同分类算法对比结果
本实验基于PyCharm Community Edition 2017.1,且各种成熟算法均直接调用自sklearn库。
4.2. 实验结果与分析
由于本算法基于集群的大量数据之间的分布特征进行分类,故本算法对异常数据不敏感。为了体现本算法的优势,在测试数据中引入错误标签数据,并与现有成熟分类器:决策树、贝叶斯、KNN进行分类精度对比,结果见表1。
从实验结果可见本文所提出的算法性能更为稳定。面对数据分类中,经常出现的人为标签错误问题拥有更优越的分类能力。
5. 结束语
本文首先论证了基于熵权的特征向量表示不同类别数据的可行性。在此基础上提出了基于特征熵权的集群分类算法。经实验验证,该算法对特征分布差异明显的数据集具有相当高的分类精度,且比起现有分类算法对异常数据更为不敏感,一定程度上解决了人为标签容易出错的问题。
基金项目
中国国家自然科学基金国际青年科学家基金(NSFC Grant No.61550110248);西藏自治区重点科研项目(批准号:Z2014A18G2-13)。
致谢
这项工作由中国国家自然科学基金国际青年科学家基金(NSFC Grant No.61550110248)和西藏自治区重点科研项目(批准号:Z2014A18G2-13)资助。同时,作者要感谢编辑和审稿人的认真负责。