1. 引言
随科学技术的发展,信息安全技术对国民经济,国防军事及个人生活的影响性日益增强,引起了研究机构和广大学者的关注。信息安全技术包含:网络攻防,安全协议,信息流保护等多个方面,其中针对信息流的保护有加解密技术、信息隐藏等技术,单独使用加解密技术因其数据显示流异常易被第三方发现,导致秘密信息被敌方破解、破坏,不能完安全有效传递秘密信息的任务。信息隐藏是一种通过人的感知冗余与多媒体数据的统计冗余,将秘密信息嵌入到普通的载体文件中传输已达到不可感知不易检测的目的技术,在当今图像,音频,视频,文本等载体海量产生的信息时代,相对加密技术,信息隐藏技术具有秘密信息传递过程难以发现的优势,常与加解密技术相结合,使用在通信系统中,取得了很好的安全效果 [1] 。目前信息隐写通信采用隐写术基于不同类型数字媒介格式如图片、音频,文本和视频等,其中MP3音频文件因其使用广泛,载体较多,隐藏容量大,强鲁棒性等特点,在信息隐藏技术的被深入研究。
目前,陆续有学者及研究机构针对MP3信息隐藏提出有效算法。宋华等 [2] 深入研究了MP3Stego算法,该算法通过改变part_2_3_length [3] 的奇偶性来隐藏信息,但是隐藏容量小,易被检测;高海英等 [4] 提出了基于Huffman编码的MP3隐写算法,即通过改变部分Huffman码字达到信息隐藏的目的,该算法具有透明性高,隐藏信息嵌入量大,不易被检测等优点;刘秀娟等 [5] 提出了一种大容量MP3比特流音频隐写算法,即按照小值区码对映射规则修改对应码字以嵌入信息。该算法隐藏容量高,透明性好,且能够抵抗对主流隐写分析算法
本文在文献 [5] 算法基础上,采用基于Huffman小值区多位映射编码与大值区经典 [4] 隐藏算法相融合而成的基于MP3 Huffman多位映射隐藏算法,使得改进算法的隐藏容量较原算法提升较大,而算法的透明性和码字的统计特性并无太大的差异,在确保音感质量同时,提高隐写效率。
2. 背景知识
2.1. MP3编解码原理
在研究MP3音频隐藏算法以前我们首先了解一下其编解码原理,MP3编解码及隐藏流程图如图1所示,Huffman结构图如图2所示。
MP3音频编码过程 [6] [7] 第一步首先对其音频信号以pcm进行采样,采样按照帧为单位划分,每帧分为两个颗粒,每颗粒为576个采样值,每帧共计1152个采样值。第二步采样值按两路处理。一路进入32位子带滤波器,均匀的分为32个子带信号,再对各子带信号做mdct变换,完成子带信号由时域样值变为频域样值的变化,另一路采样值经心理学模型计算出MDCT(修正快速傅里叶变化)变换的块类型及PE值等参数。第三步通过心理声学模型处理后的参数对mdct后的频域值进行量化和编码,经过量化后的频率系数分为三个区:ZERO区(位于高频段,值为零不参与编码),小值区(系数值为0,1或−1,四个为一组编码)对应着Huffman码表中的两个表(Tab A和Tab B),大值区(两个系数为一组编码)占用Huffman码表中余下的32个表。最后对其进行比特流封装完成MP3码流输出。解码为编码的逆过程,在此不再详述。
2.2. 大容量MP3比特流音频隐写算法
基于人耳生理声学特点及音频特性,人耳对中低频段声音变化相对高频段声音敏感度低,因而对位于中低频的Huffman小值区系数做较小改变对音质的影响不明显,人耳极难辨别差异,可以很好的满足隐藏系统对鲁棒性和不可察觉性的要求 [8] 。依据这个原理,刘秀娟等提出了大容量MP3比特流音频隐写算法 [5] 。小值区数据结构如下图3所示,Huffman小值区是由HCode位和Sign位组成,其中HCode为
编码后的码值,后接的Sign a,Sign b,Sign c,Sign d是该码值的四个符号位。
在小值区使用的Huffman(Tab A 和Tab B)码表中,我们发现以下特点:
1) 在小值区,汉明重量D相同的四元组{Sign a, Sign b, Sign c, Sign d},其码值HCode长度也相等(tab A中码组0101,1010例外)的特点。
2) 以tab A表为例,符合上述规律的码重值D=1的四元组有四个,记为M={A,B,C,D,}对应码值记为N={Ca, Cb, Cc, Cd,}。
3) 若把A中码字Ca换位B中码字Cb,因码重相同。A,B修改互换不会改变MP3码流级码字的长度和结构,只是把A变成B,对mp3播放无影响。
4) 如若以码字Ca,Cb分别代表秘密信息“0”,“1”,则把Cb变为Ca等同嵌入消息比特“1”;则把Ca变为Cb等同嵌入消息比特“0”;
5) 同理符合汉明重量D=2,3的四元组分别也有对应码组,既可嵌入秘密信息。
3. 基于MP3 Huffman编码小值区隐藏算法
在刘秀娟同学提出对Huffman小值区大容量隐写算法基础上,本文提出对Huffman小值区采用新的映射对应规则后,对每个码字的最后两位数据进行信息位替换隐藏,在保证声音质量的情况下,获得隐藏容量大幅度提升,此方法已在软件上实现,具体思想如下(以Tab A表为例):
3.1. MP3编解码原理
1) 寻找对应码
在Tab A中按照码长长度相同原则,找到两个一对的对应码组,Huffman小值区码表见表1和表2,隐写对应规则见图4。

Table 1. Huffman Tab (Tab A)
表1.Huffman码表(Tab A)
Table 2. Huffman Tab (Tab B)
表2. Huffman码表(Tab B)
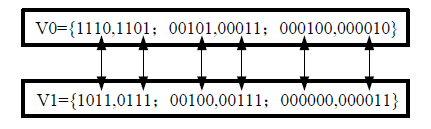
Figure 4. Tab A mapping corresponding table
图4.Tab A 映射对应表
2) 以V0代表值1,v1代表值0,根据嵌入秘密信息替代实现隐藏。
例如以v0=1110,v2=1011两组对应映射为例,若MP3音频连续小值区码值为v0,v0,v1,代表数据为110,若要嵌入的秘密信息为101,根据规则需把小值区数据替换成v0,v1,v0,完成秘密信息的隐写。
3.2. Huffman小值区多位映射隐写算法
该算法,按照码长长度相同原则,找到四个码值为一个对应码组,对应规则见图5。
该原则遵循码长相同,既每组四个码字码字的hlen(码长)必须相同,如载体码字是4 bite长,嵌入信息后的码字也必须是4bite长。以四个相同码长的码字为一组记为Ki={V0[i],V1[i], V2[i], V3[i]},其中的四个码字V0~V3分别代表信息比特00,01,10,11。以码长为4的码组为例,执行嵌入的时候,先找出当前小值区符号的码字V[j][i],然后根据待嵌入隐藏信息转化为二进制编码的比特值是否等于V[j][i],再决定是保存还是修改码字,如若修改,则把V0中的值改成隐藏信息对应V[j]中的值。由于这种修改规

Figure 5. Tab A mapping corresponding table (new)
图5. Tab A映射对应图

Figure 6. Tab B mapping corresponding table (new)
图6.Tab B 映射对应图
则是在集合V[j][i]的四个码字之间间的映射,因而称为“多元码值映射对应规则”。
举例若嵌入两位原始数据为10,对应V0嵌入码值为0101,则变更为V0中的0100,若原始数据为01,则保存V0对应的数据0101。修改等效于把四元组0101换成0111,隐藏不改变符号位信息。
对应Tab B表情况和Tab A类似,符合汉明重量D为1,2,3,4的四元码组各有4个,他们对应的16个码字构成映射,映射方式如上图6所示。
3.2.1. Huffman小值区多位映射信息嵌入步骤
1) 把要隐藏的秘密信息及相关参数二值化处理,获得0,1比特值的码流形式,并对其用合适的加密算法进行加密处理获得二进制流M
2) 打开载体MP3音频文件读取头信息,帧边信息,解码比例因子等获取编解码重要参数
3) 读取系数及参数信息,确定系数值对应的是Tab A还是Tab B
4) 根据码表获取码表中属于V[j]中的码值,以码值映射的方式嵌入信息M1,并移动直至小值区结束。
5) 重复2)到4)步直至MP3文件结束或隐藏信息结束
3.2.2. 信息的提取
信息的提取,为嵌入隐写的逆过程,信息提取步骤如下:
1) 通过隐藏软件打开载密文件,对载密文件进行帧解码,获取帧头数据及主数据
2) 通过帧边信息等解码参数
3) 确定对应系数小值区码表,按照图5和图6对应原则得出秘密信息二进制码流
4) 重复2)到4)步直至接受收秘密信息数据接收完成标志符。
3.3. 基于Huffman大小值区比特流隐写融合算法
文献 [9] 中的算法嵌入容量大,透明度较高。由于大值区和小值区是两个不同频段的区,因此该算法与文献 [5] 中的算法互不影响,可以完美的融合在一起,既可以增加嵌入量,又对透明性和码字统计量不产生明显影响。
改进算法的实现流程如图7所示,下面是嵌入信息的具体步骤:
1) 选定MP3音频载体,设i=0,N=密文比特数+16(其中16表示存放密文的大小)。对秘密信息及必要参数进行二值处理,转化为二进制码流
2) 解码MP3文件,按照大值区经典算法规则,搜索大值区符合嵌入要求的Huffman码字,嵌入1bit信息使得i+1。若i=N,则返回“嵌入完毕”,结束信息嵌入过程,否则,判断大值区是否结束。
3) 如果大值区没有结束,则重复执行步骤2),否则,继续执行步骤4)。
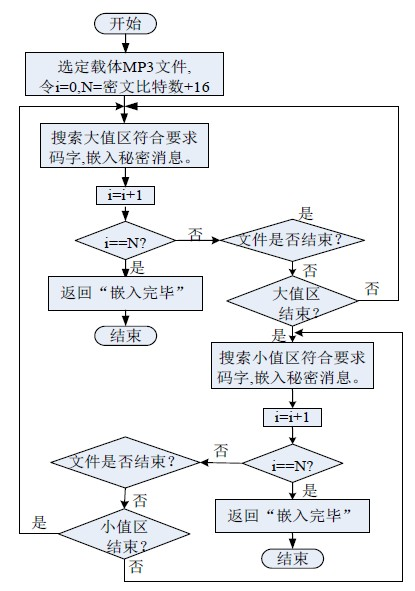
Figure 7. Flow chart of improved algorithm
图7.改进算法的流程图
4) 搜索小值区符合嵌入要求的码字,嵌入1bit信息使得i+1。若i=N,则返回“嵌入完毕”,结束信息嵌入过程,否则,判断小值区是否结束。
5) 如果小值区没有结束,则重复执行步骤4),否则,循环到下一粒度组,重复执行步骤2)到4)直至信息隐藏结束。
4. 改进算法性能分析
4.1. 隐藏容量性能分析
本隐写算法的原理是在Huffman大小值区进行进行码字替换嵌入秘密信息进行实现的,由于MP3音频载体不同,大小值区码对数目不同导致其隐藏容量的不同,因而需在隐藏前MP3音频载体进行隐藏容量判断,若秘密信息大小小于MP3音频隐藏容量,则另行处理,载体MP3文件的隐藏容量的计算等价于求MP3文件中上述映射码对数目。表3为不同MP3文件使用大容量改进算法前后隐藏容量分析,平均隐藏容量较原算法增加40%:
4.2. 算法透明性分析
从量化角度衡量隐藏前后MP3载体音质好坏的标准的性能指标是分段平均信噪比SNR [10] ,通过实验求
个帧(每帧1152个采样数据)的携密语音的平均信噪比(dB)≈66.43 dB,大于人耳的可察觉信噪比阈值为66dB,因而在接受范围之内。
具体的过程如下:
设MP3数据段长度为N,原始MP3采样数据为
,嵌入隐蔽信息后的MP3采样数据为
,则
(1)
(2)
(3)
(4)
上式中
为采样信号的均值,
和
分别是信号隐写前的采样信号的方差和信号隐写后的采样信号的方差,根据计算出平均信噪比SNR来分析该算法的透明性。
4.3. 码字统计量分析
从大容量改进隐藏算法原理来看,本算法的隐藏是利用小值区映射码组得到的,因而肯定对以前的码字结构和码字分布有改变,造成鲁棒性降低,但降低程度较小,远在接受范围之内,通过对10首MP3音频歌曲嵌入隐蔽信息前后Huffman小值区码字统计进行对比,如图8和图9所示。
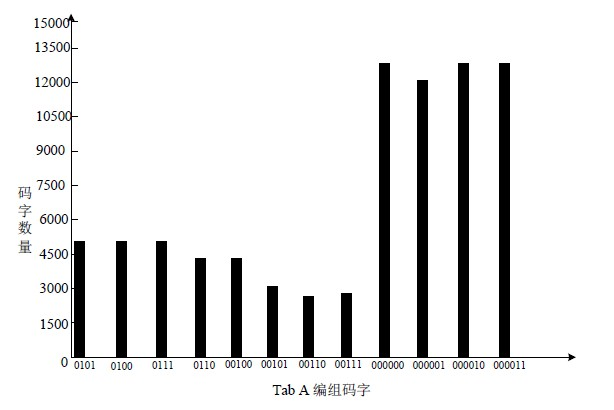
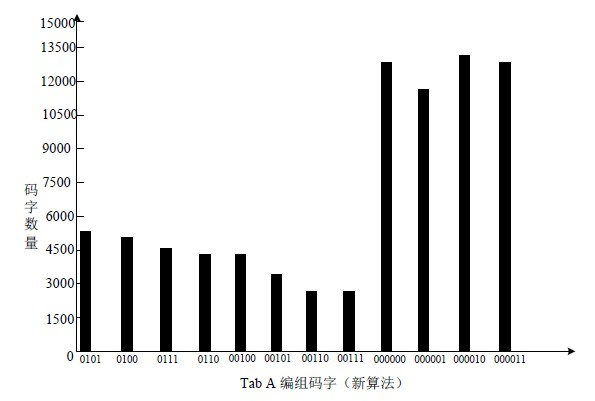
Figure 8. Codeword distribution before and after Tab A encryption
图8.Tab A加密前后码字分布图
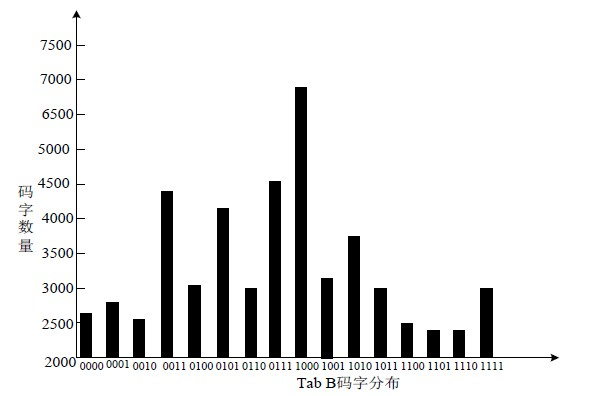
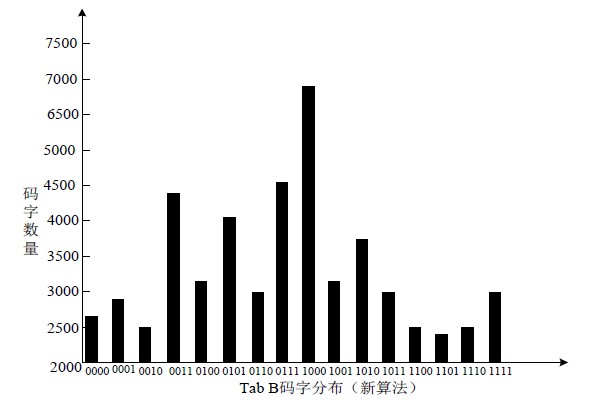
Figure 9. Codeword distribution before and after Tab B encryption
图9.Tab B加密前后码字的分布图
经过码字统计对比可知,嵌入前后Huffman码字分布较小,论证了该算法的抗检测能力较强。
4.4. 不可感知性分析
由于Huffman小值区,主要位于人耳不敏感的中高频段,因而本算法理论上对不可知性影响不是很
大。本文以44.1khz采样,64kbs的单声道五个MP3文件文样本行试验,根据对10位同学测试,在不知情的情况下,通过对根据本算法嵌入数据的mp3文件进行ODG(Objective Different Grade)辨别 [10] ,没有同学听出差别,见表4。
5. 结语
本文通过对MP3编解码原理,Huffman编码规则等学习,在大容量改进算法基础上提出了基于Huffman码表新的映射算法,该算法融合Huffman大值区的经典算法组成基于MP3 Huffman多位映射隐藏算法使得在确保音质的情况下,隐藏容量得到大幅提升,通过对新旧算法进行的实验对比表明所新算法在隐写容量、隐写效率及保持音频感知质量方面取得了很大提高。由于该算法使用码字对替换原理嵌入秘密信息,因而会对码对结构和分布造成变化,如何把这种不足进一步降低,还需要进一步研究思考,另一方面,本文基于Huffman模块的算法可以同其他模块隐藏算法进一步结合(例如小波隐藏算法等等),值得进一步考虑!
参考文献