1. 引言
目前语音增强算法技术已经取得了瞩目的发展,语音增强算法极大地提升了语音质量。其中比较经典的算法有维纳滤波器、谱减法、最小均方误差(MMSE)估计器 [1] 等有效算法。但在单一控制条件下,传统的噪声抑制算法会对输入语音产生一定的噪声污染,典型的如维纳滤波。当从均方误差角度进行度量时,纯净语音和增强语音幅度谱之间差值的正负比较容易被忽略。所以用传统的语音增强算法处理被破坏的语音时,经常会由以上原因产生失真。
由Loizou等人根据增强语音与纯净语音幅度的大小关系,把增强之后的语音失真分为三个部分,分别是幅度衰减部分,幅度放大且放大倍数小于等于2倍(即放大上限为6.02 dB),幅度放大超过2倍(放大倍数超过6.02 dB)三个部分 [2] 。目前的数据表明,近一半的数据下降在第一区,其特点是衰减失真,而几乎另一半的数据落在第三区,其特点是放大失真超过6.02分贝。只有一小部分(12%~18%)的数据在第二区域 [3] ,其特点是低放大失真,小于6.02分贝。但是Loizou等人的研究是根据估计的纯净语音与原始纯净语音的幅度谱比较,这在现实中是不可能实现的,因为在实际运用时原始纯净语音信号是未知的。
本文基于loizou等人对第一区域第二区域第三区域的划分,把第一和第二区划归为一个大区域,结合几何相位信息,提出了针对新划分的区域以及第三区域,利用先验信噪比与后验信噪比的判定条件,代替了与原始纯净语音的幅度对比,从而对幅度增益进行约束,具有简便易行的特点。通过MATLAB进行大量实验仿真,将本文提出的改进算法与现有算法进行比较,结果显示具有较好的语音增强性能。
2. 语音增强基本理论
在语音增强技术中,假设t时刻的带噪语音信号为y(t),纯净语音信号x(t)和噪声v(t)互不相关,其时域表达式如下 [1] :
(1)
对上式进行N点DFT变换后,与时域语音对应的语音谱表示如下:
(2)
其中,Ym,k,Xm,k和Vm,k分别表示带噪语音频谱、纯净语音频谱和噪声谱,m,k分别表示帧索引和频率。
经过增强处理过后的纯净语音频谱估计可以由增益因子Gk,m表示为:
(3)
其中,
是估计的纯净语音谱,增益因子
一般来说是先验SNR和后验SNR的函数。
先验SNR的定义为:
(4)
后验SNR的定义为:
(5)
其中,E{.}表示数学期望算子。
一般来说,普通维纳滤波语音增强算法的系统增益因子可以表示仅为先验信噪比参数的函数 [4] :
(6)
目前已经证明,平方根维纳滤波相比其他比较复杂的降噪算法,具有计算量小且易于实现的优点,且在语音质量和清晰度上仍然能够达到同样的要求,本文在实验中决定采用平方根维纳滤波。
平方根维纳滤波增益函数
为 [3] :
(7)
其中
是先验SNR,根据以下方程得:
(8)
其中,
是估计的背景噪声功率谱,
是平滑因子,通常取值为0.98。
最后,通过(2) (3) (7) (8)式,可获得维纳滤波语音增强系统的输出
,再将其通过N点IDFT变换至时域,即可得到估计的纯净语音信号。
3. 本文改进算法
首先,为了分析估计的纯净语音信号与输入纯净语音振幅的大小关系对噪声抑制的影响,根据loizou等人的研究,定义了剩余信噪比 [5] 的概念:
(9)
由上式
与
的比值,可以把语音信号分为三个区间 [6] :
区间I:在此区域,
,表示幅度产生了衰减失真。
区域II:在此区域,
,表示幅度产生了放大失真且放大上限为6.02 dB。
区域III:在此区域,
,表示振幅产生超过6.02 dB放大。
由目前的研究可知,对第I和第II区域可以进行合并,并进行如下限制约束 [7] 时语音质量有所改善:
(10)
把(2) (3)式代入(10)式区域判定条件可得:
(11)
对方程两边同时平方:
(12)
引入几何相位 [8] :
根据图1的极坐标形式可得:
(13)
其中,
表示噪声相位谱,
,
和
分别表示带噪语音、纯净语音和噪声信号幅度谱。

Figure 1. The geometric relationship between pure speech, noise and noisy speech spectrum
图1. 纯净语音、噪声和带噪语音谱之间的几何关系
根据三角函数法则很容易得到以下关系:
(14)
等式两边同时除以
可得:
(15)
其中,
表示瞬时的先验信噪比,
表示瞬时的后验信噪比,
由MS噪声估计算法可得 [9] 。
把(15)式代入(12)式,可得:
(16)
最后,综合幅度约束为:
(17)
其中,β由多次试验结果取0.68。
4. 仿真实验结果分析
为了检验改进算法的性能,本文运用MATLAB软件进行实验仿真,选取多种来自语音库的纯净语音sp01.wav~sp10.wav,噪声来自于噪声库的white,babble,pink,F16座舱,Destroyrengine噪声,输入信噪比分别取5 dB,10 dB,15 dB,20 dB。所有信号的取样频率均为8 kHz/s,仿真实验中语音信号帧长K = 256,重叠率为50%,系数β = 0.68。
首先根据语谱图进行对比分析:
图2是纯净语音信号的语谱图,图3是的带噪语音信号的语谱图,图4基于幅度判定条件约束的语音增强语谱图,通过对比,可以看出此算法虽然能够在一定程度上消除背景噪声,但产生了语音失真,并且在可行性上有较大难度。图5是基于本文算法的语音增强语谱图,与其他算法相比,降低了语音失真和背景噪声的影响,体现了较好的语音增强性能。
另外,通过对数谱距离(LSD),分段信噪比(SegSNR),短时清晰度客观测度(STOI)来 [10] [11] 对比分析基于本文提出的算法与幅度判定条件约束语音增强算法的性能:
从表1中可以看出在输入信噪比分别为5 dB,10 dB,15 dB,20 dB时输入噪声为的White,Pink,Babble,F16座舱,Destroyrengine五种噪声环境下,对数谱距离(LSD)是表示增强语音与原始语音之间接近程度的测试,LSD测度的数值越小,说明语音的失真的程度越低。本文的改进判定条件算法LSD值小于现有幅度判定条件约束算法,其中五中不同的噪声在输入SNR为15 dB和20 dB时的改进效果最突出,能达到大约1.9的提升效果,由表1可以明显得出本文提出算法输出的语音与纯净语音更接近,语音的增强效果更好。
分段信噪比(SegSNR)反映出每一帧信号中估计语音与原始语音之间的差距的大小,算法的分段信噪比越大,说明估计的增强语音与纯净语音之间的差距越小,语音质量也就越好。从表2中可以看出在以上五种噪声环境下,本文改进算法的分段信噪比要优于目前的幅度判定条件约束算法,在输入SNR为15 dB时效果最佳,最高可达到大约1.4的改进数值,表2比较直观的说明本文算法具有较好的语音增强性能。
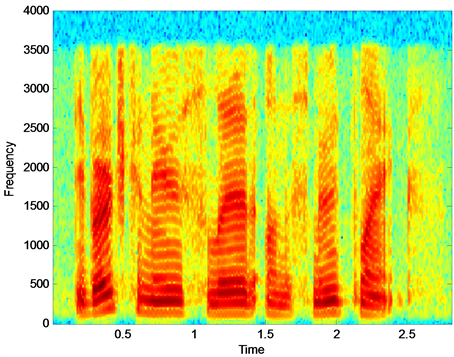
Figure 2. Speech spectrogram of pure speech signal
图2. 纯净语音信号语谱图

Figure 3. Speech spectrogram with noisy speech
图3. 带噪语音语谱图
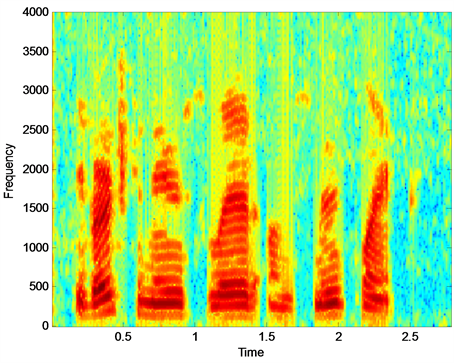
Figure 4. Speech enhancement spectrogram based on amplitude decision condition constraint
图4. 基于幅度判定条件约束的语音增强语谱图
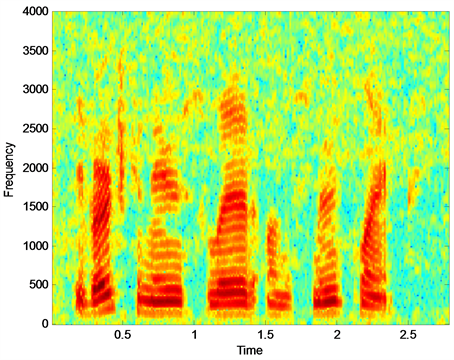
Figure 5. Speech enhancement spectrogram based on improved condition algorithm in this paper
图5. 基于本文改进判定条件算法的语音增强语谱图
短时清晰度客观测度(STOI)是表征语音增强算法在语音可懂度方面性能好坏的测度参数,STOI测度的数值越大,说明该算法增强后语音与原始语音之间的偏差越小,语音可懂度就越好。从表3的可知本文改进判定条件算法的输出语音的可懂度有所提高,增强效果大于之前幅度判定条件约束。因此可以认定为,本文提出的改进算法在一定噪声环境下,相比目前的算法不仅在可行性上有很大的进步,而且在语音增强性能上有提升。
5. 总结与展望
本文主要研究了一种通过融合几何相位信息,使幅度失真与先验信噪比和后验信噪比建立数学关系的噪声抑制算法。根据loizou等人目前所做的研究,其大多采用估计的纯净语音与原始纯净语音的幅度谱进行比较,实际运用起来可行性较差,本文通过引入几何相位信息,推导出与先验信噪比和后验信噪比有直接联系的约束条件,实施起来简单易行。实验结果表明,新算法在LSD,STOI,SegSNR评价标准下具有较好的性能,有效地提升语音质量,提高语音的可懂度。

Table 2. SegSNR data contrast table
表2. SegSNR数据对比表
Table 3. STOI data contrast table
表3. STOI数据对比表
虽然本文提出了融入几何相位信息的噪声抑制算法,但本文研究仅局限于理论和算法层面,与达到实际工程上的运用还有一定的距离。未来本文还应对噪声的估计算法进行深入研究,这势必会对实验结果的精度造成一定的影响,下一步应该深入研究噪声估计算法,以进一步提高算法数据的精确度。