1. 引言
现如今,通过使用数据挖掘技术,我们可以从海量数据中挖掘有趣的信息。其中,关联规则挖掘是数据挖掘技术中较为重要的一种手段。它一般分为两个步骤:一是依据事先设定的支持度阈值找出所有符合条件的频繁项集;二是依据频繁项集及给定的置信度阈值产生关联规则 [1] 。其中,挖掘算法的性能主要取决于频繁项集的生成,因此识别或发现所有频繁项目集是关联规则挖掘算法的核心。随着数据挖掘技术理论研究的深入,各类关联规则挖掘算法也在不断地涌现。传统的算法主要包括Apriori算法、FP-growth算法以及Eclat算法,后续的大部分算法都是在这三类算法的基础上进行相应的优化和改进。
Apriori算法 [2] 使用一种称为逐层搜索的迭代方法,通过项目集元素数目的不断增长来逐步完成频繁项集的发现,核心思想是通过候选集生成和情节的向下封闭检测两个阶段来挖掘频繁项集,该算法设计思想简单,易于实现,但是产生了大量候选集,同时需要多次对事务库进行扫描,计算耗时过长;FP-growth算法 [3] 使用一种称为频繁模式增长的方法,采取分治策略,将代表频繁项集的数据库压缩到一棵频繁模式树(FP树)上,然后把这种压缩后的数据库划分成条件数据库,每个数据库关联一个频繁项或“模式段”,并分别挖掘每个条件数据库,这种方法可以显著地压缩被搜索的数据集的大小,该算法只扫描事务库两次,且无需产生候选集,相比Apriori算法性能有显著的提高,但由于所有项集都压缩在一棵树上,对内存要求较高,且递归算法设计复杂;Eclat算法 [4] 的核心思想是将水平数据库转换成垂直数据库,然后将项集的TID_set进行交运算来得到项集的支持度,该算法由于只扫描一次事务库,且项集支持度是通过交运算得到的,大大减少了计算时间,但Eclat算法存在搜索空间大、连接操作频繁、求交运算耗时的问题。
本文选取上述几类算法中性能较好的Eclat算法,结合近年来该算法的相关研究,针对其普遍存在的问题和不足,从候选集的生成和支持度的计算两个方面对其加以优化和改进,提出了前后剪枝相结合的候选集优化策略以及利用数组索引取值计数的求交运算方法,以达到提高Eclat算法效率的目的。
2. 关联规则相关概念
设D是事务数据库,T是一个事务,
。I是一个项目集,项目集中项目的数量为I的长度。设X是项目集I的一个子集(
),其中包含k个项目,则称X为k项集。每一个事务T都有唯一的标识符(TID)并包含一个项目集。项集X的支持度,记为Support(X),它表示在数据库D中包含项集X的事务数与总事务数之比。如果X的支持度大于等于一个预先设置的支持度阈值(最小支持度,记为min_sup),则称X为频繁项集 [5] 。
关联规则用形如
的蕴含式来表达,它表示两个项目集X和Y之间的某种关系,其中
,
,
。
的支持度,记为
,它表示在D中同时包含项集X和Y的事务数占事务总数的百分比,即
;
的置信度,记为
,它表示在D中同时包含项集X和Y的事务数与包含X的事务数之比,或者说,在包含项目集X的所有事务中含有项目集Y的事务数所占的百分比,即
。如果
大于等于min_sup,同时
大于等于min_conf (预先设置的置信度阈值,即最小置信度),则称
是强关联规则 [6] 。
3. Eclat算法及改进算法
3.1. Eclat算法
3.1.1. 算法主要思想
Zaki在2000年提出的Eclat算法是基于深度优先搜索的策略,采用垂直数据格式、等价类技术、交集运算等等。Eclat算法的主要步骤如下:扫描数据库以获得所有频繁1-项集;从频繁1-项集开始生成候选2-项集,然后通过筛选掉非频繁的候选项集来获得所有频繁2-项集;从频繁2-项集生成候选3-项集,然后通过筛选掉非频繁的候选项集来获得所有频繁3-项集;重复上述步骤,直到无法生成候选项集为止。上述步骤概括起来包括两个阶段:一是通过自连接产生候选项集;二是通过求交运算获得支持度。
1) 产生候选集
与Apriori算法一样,Eclat算法也采用连接操作来产生候选项目集,即通过连接两个k-项目集生成(k + 1)-项目集。两个k-项集连接的条件是它们各自的前k-1个项必须相同。例如,有两个3-项集:
和
,它们各自的前两项都为{I1, I2},因此l31与l32能连接生成一个4-项集:
。Eclat算法通过使用等价类 [7] 的概念将搜索空间划分为多个不重叠的子空间,有相同前缀的项目集被划分为同一个类,而候选项目集的生成只在同一个类里操作。这种等价类的技术显然可以提高候选项目集生成的效率,并减少项目的占用内存。
2) 求交运算
Eclat算法求交运算是通过逐项比较事务tid的方式进行的。设l21和l22是两个项目集,
,
。假设l3为l21与l22连接后生成的,
,
。设P1和P2是两个分别指向TID_set(l21)和TID_set(l22)各自第一个TID的指针。获取l21和l22交集的过程如图1所示。由于生成(k + 1)-项集过程和两个k-项集求交的过程是同时进行的,因此可以立即得到(k + 1)-项集的支持度。
3.1.2. 算法实现过程
下面以具体示例阐述算法的实现过程。给定表1所示垂直数据格式的事务库,假设支持度阈值为0.5,对表中数据进行频繁项集的挖掘,具体演示过程如图2所示。在图2中,每个椭圆内部包含了项集、项集支持度计数以及项集对应的事务集,其中粗体标注的椭圆为频繁项集,其余椭圆为候选非频繁项集。图2显示,对于表1中的数据,共生成了20个候选项目集(除去1-项集),执行了20次连接操作和求交运算,产生了9个频繁项集(除去频繁1-项集)。
3.1.3. 算法主要缺陷
尽管Eclat算法的效率很高,它仍然有以下一些缺陷:1) 由于候选集的产生是在等价类中完成的,没有像Apriori算法一样利用向下封闭性质 [8] 对候选集进行剪枝优化操作,因此候选项目集的数量超过了Apriori算法。2) 项集的支持度是通过交运算获得的,相比Apriori算法通过扫描事务库获取支持度的方式在效率上有很大提高,但是当项目集包含的事务集规模很大时,逐项的求交运算导致效率依然不尽人意。为此,近年来许多人开始关注Eclat算法并提出了一些改进算法。
3.1.4. 现有改进算法
Eclat_Diffsets算法 [9] 采用布尔矩阵与差集技术来提高交集计算效率并减少内存占用,该算法采用布尔矩阵存储itemset和TID_set,并通过二进制运算来计算交集,这种方式能明显改善支持度获取效率;熊忠阳等人提出的HEclat算法 [10] 采用散列布尔矩阵来改善交集计算,该算法使用散列布尔矩阵来存储
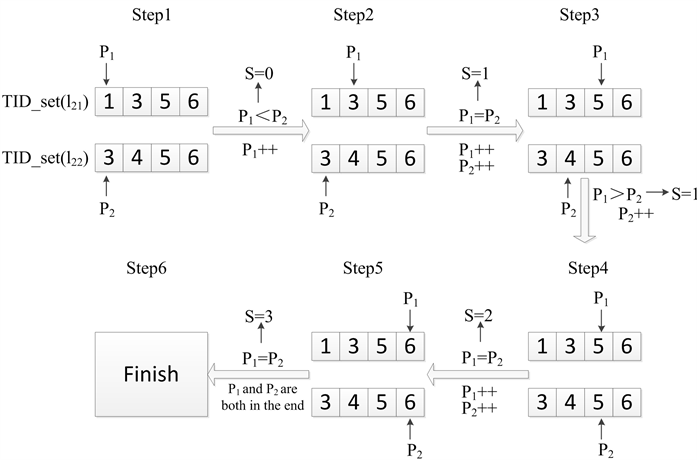
Figure 1. Example of intersection operation process in Eclat algorithm
图1. Eclat算法求交运算过程示例

Table 1. Vertical data format of a database
表1. 数据库的垂直数据格式
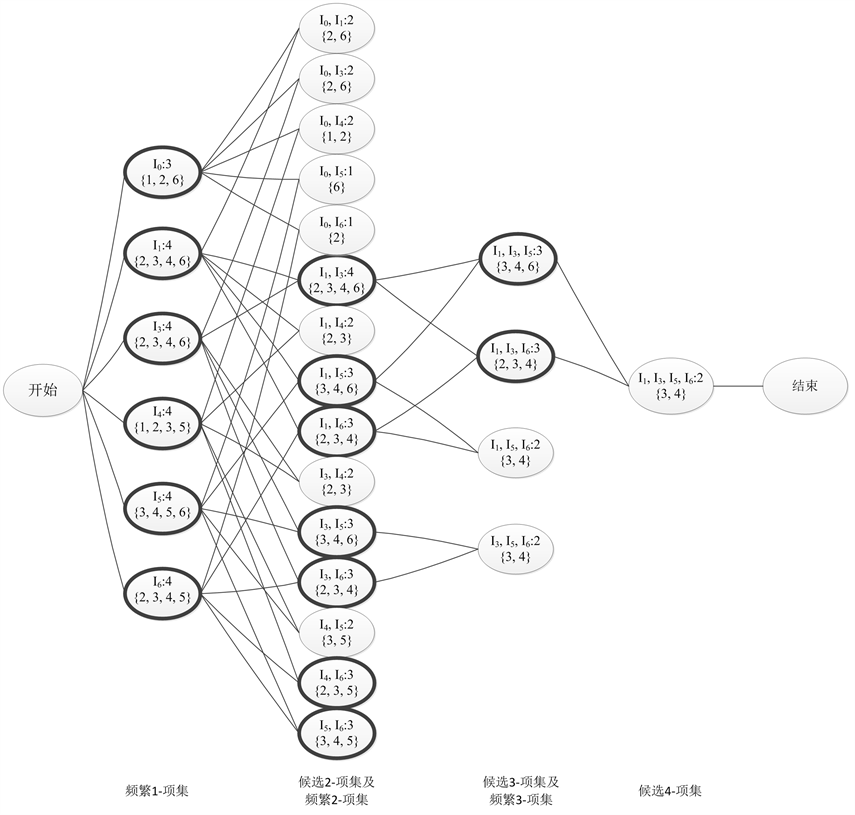
Figure 2. A demonstration of the process of mining frequent itemsets by Eclat algorithm
图2. Eclat算法挖掘频繁项集过程演示
项目集的TID_set,当计算两个项目集的交集时,只需要在两个布尔矩阵上使用位“与”操作,散列布尔矩阵只有在数据库的事务数规模不是很大的时候才能提高效率;Eclat_opt算法 [11] 则采用双层哈希表技术加快候选子集的搜索速度,通过项集集合划分链表技术减少项集连接的比较判断,并利用事务标识(tid)失去阈值技术加快交集计算的速度,这些技术能够对候选3-项集进行充分剪枝,减小搜索空间的同时缩短了生成候选集的时间,此外提高了交集计算的速度。通常情况下,Eclat_opt算法比其他Eclat改进算法更有效。现有的改进算法虽然能够在不同程度上改善原始Eclat算法的效率,但是这些算法仍然有一些缺陷,比如大量无用的候选集产生,耗时的求交运算等。
3.2. 改进的Eclat算法
针对Eclat算法存在的缺陷,本节从候选集的生成和支持度的计算两个方面分别对原始算法进行优化和改进,其具体策略如下:
3.2.1. 候选集生成的优化
为防止大量候选集的产生而导致过多的求交运算,需要在候选集的数量上进行进一步的优化压缩。为此,本文借助Apriori算法中候选集剪枝优化的思想,采用两种剪枝策略相结合的方式对Eclat算法中的候选集进行优化处理。一是在连接生成候选集Ck之前,对Lk−1进行预先剪枝,筛选掉那些在连接后一定是非频繁的项集,以便省去重复的连接操作,即预剪枝优化;二是在连接生成候选集Ck之后,利用频繁项集的先验性质,对候选集再剪枝处理,即后剪枝优化。通过两种剪枝策略相结合的方式,充分压缩最终参与求交运算的候选集规模。
1) 预剪枝优化
预剪枝优化的思想利用了以下性质:若Lk−1项集中存在项目i,使得i在所有频繁项集Lk−1中出现的次数少于k − 1次,则与项集Lk−1 (i)连接后生成的Ck一定是非频繁的(Lk-1(i)指的是包含项目i的Lk−1项集)。
对上述性质采用反证法:假设现在有个Ck是频繁项集,根据频繁项集先验性质,它的所有子集也都是频繁项集,因此它的所有k − 1项子集都属于Lk−1,任意项目i在该Ck的k − 1项子集中出现的次数都为k − 1次,则项目i在所有频繁集Ck的k − 1项子集中总共出现的次数至少为k − 1次,与性质中的条件相矛盾,故Ck是非频繁项集。
2) 后剪枝优化
为进一步压缩候选集的规模,对Ck进行后剪枝优化处理,其剪枝思想利用频繁项集先验性质 [12] :频繁项集的所有子集都是频繁的,也就是说,若某个项集是非频繁的,则它的超集也一定是非频繁的。
上述性质在Apriori算法中采用的较多,本文将其引用到Eclat算法中,其证明过程不再赘述。后剪枝具体步骤如下:对每个Ck进行k − 1项子集的分解,判断所有k − 1项子集是否在Lk−1的集合中,若存在k − 1项子集不在Lk−1的集合中,则删除该Ck。
下面以
为例,用上述两种剪枝策略相结合的方法阐述C3产生的具体过程。在L2中,只有I4出现的次数小于两次,因此筛选掉{I1I4},
;对L2’自连接,根据等价类理论,只有{I1I2}、{I1I5}和{I1I6}相互间可以连接,连接后的
;对于{I1I2I5},由于子集{I2I5}不在L2中,因此筛选掉{I1I2I5},则最终的
。
3.2.2. 支持度计算的改进
在Eclat算法中交集的计算是最耗时的环节,它需要一个接一个地比较两个项集的tid,当项集的TID_set规模很大时这种方式依然很低效。尽管已有的算法做了相应改进,但是这些算法求交集的基本思想与原始Eclat算法是类似的。为此,本文提出一种基于事务索引的布尔数组取值计数法来计算交集以获得项集的支持度。其步骤如下:
首先,创建一个布尔型的数组,数组的长度由事务的数量确定,数组所有元素初始化为0;
其次,将其中一个项集的tids作为索引,索引对应的数组元素设置为1;
最后,将另一个项集的tids作为索引,取出索引对应的数组元素,如果取出的元素为1,则把该元素的索引加入交集中,并增加一次支持度计数,如果取出的元素为0,则跳过。
下面仍以l21和l22两个项目集为例,用本文给出的求交方法阐述具体过程如图3所示。在图3中,
,
。因为数据库的事务数为6,则初始化布尔数组
。将l21中的tids作为索引,把指向Array中的对应元素设为1,即Array [1] = 1,Array [3] = 1,Array [5] = 1,Array [6] = 1,则
。以l22中的tids为索引,检索Array中相应的元素Array [3] ,Array [4] ,Array [5] ,Array [6] ,其中值为1的分别是Array [3] ,Array [5] 和Array [6] ,因此
,
。
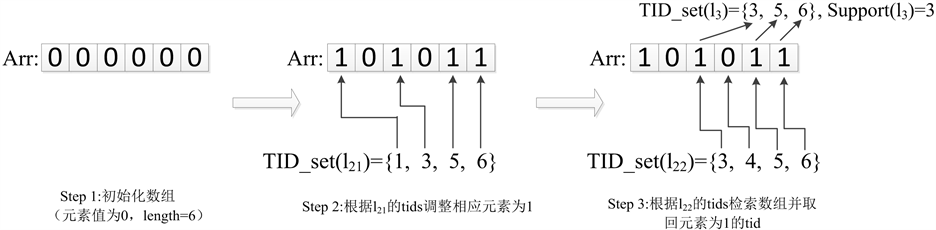
Figure 3. An example of improving the support degree calculation process of Eclat algorithm
图3. 改进Eclat算法支持度计算过程示例
上述示例表明,通过使用新的求交方法,只需要设置和检索布尔数组的元素即可求得交集和支持度,避免了传统方法中逐项比较的过程。
3.2.3. 改进算法的具体实现
综合上述两方面的优化策略,改进后的Eclat算法实现步骤如下:
1、扫描事务数据库一次,为每个项目获取事务标识符(tid),将数据库转成垂直格式;
2、在候选集Ck’产生之前,先对Lk−1剪枝,筛选得到Lk−1’:计算所有项目在Lk−1集合中出现的次数,删除项目频度小于k − 1次的项目集;
3、利用等价类技术对Lk-1’自连接,生成候选集Ck’;
4、对Ck’进一步剪枝,筛选得到Ck:列出Ck’项集的所有k − 1项子集,删除子集不在Lk−1集合内的项目集;
5、利用改进的求交运算方法得到Ck的TID_set和Support,并根据预先设定的阈值确定最终的频繁项集Lk;
6、循环2至5步过程,直到Lk的项集数量小于(或等于)k,终止算法。
改进Eclat算法的主程序伪代码如下:

其中,预剪枝函数Prune伪代码如下:

改进的支持度计算函数New_quick_support_count伪代码如下:

4. 实验设计及结果分析
4.1. 实验设计
为了验证改进Eclat算法的效率,本文通过实验分别将不同优化策略的改进算法与Eclat算法进行比较,并将Apriori作为参照算法进行分析说明。实验平台为Intel Core i5,2.5 GHz,内存8 G,操作系统Windows 10 64位。实验采用UCI标准数据集里的稠密型实际数据集Mushroom和IBM Almaden生成器生成的稀疏型合成数据集T10I4D100K,这两个数据集经常被用于各类关联规则算法的测试。数据集的特征如表2所示。
实验一:将本文的改进算法与Eclat算法以及Apriori算法进行对比实验,测试对象为稠密数据集:Mushroom,测试各算法在不同支持度阈值下产生的候选集数量变化情况。测试结果如图4所示。
从图中结果来看,三种算法产生的候选集数量都随着支持度阈值的增加而逐渐减少,但是在同一支持度阈值下,Eclat算法生成的候选集数量最多,Apriori算法次之,本文的改进算法则最少。此外,三种算法在同一支持度下挖掘的频繁项集数量都是相同的。
实验二:将改进算法与Eclat算法以及Apriori算法进行对比实验,测试对象为稠密数据集:Mushroom,测试各算法在不同支持度阈值下执行时间的变化情况。测试结果如图5所示。
从图中结果看,三种算法的执行时间都随支持度阈值的减小而增大,但在同一支持度阈值下,本文算法执行效率要优于传统的Eclat算法和Apriori算法。其中,在支持度阈值较大时,三者在时间效率上区别不是很大,但随着支持度阈值的逐渐减小,三种算法执行时间的差距将越拉越大,改进算法的效率优势将体现的更加明显。此外,从min_Sup = 0.25开始,Apriori算法在执行时间上有一个大幅的跃升。
实验三:将改进算法与Eclat算法、仅采用剪枝策略的Eclat算法以及仅改变求交运算的Eclat算法进
Table 2. Test data set related information
表2. 测试数据集相关信息
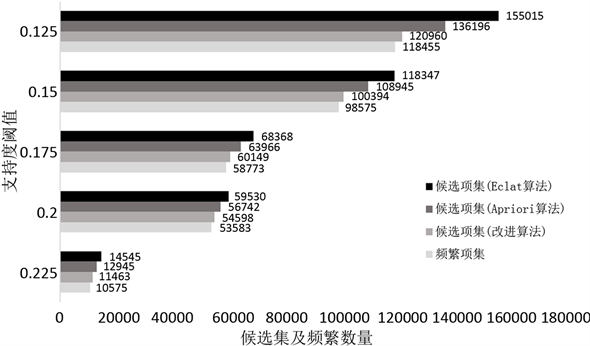
Figure 4. Number of candidate sets under different support thresholds on Mushroom dataset
图4. Mushroom数据集上不同支持度阈值下候选集数量
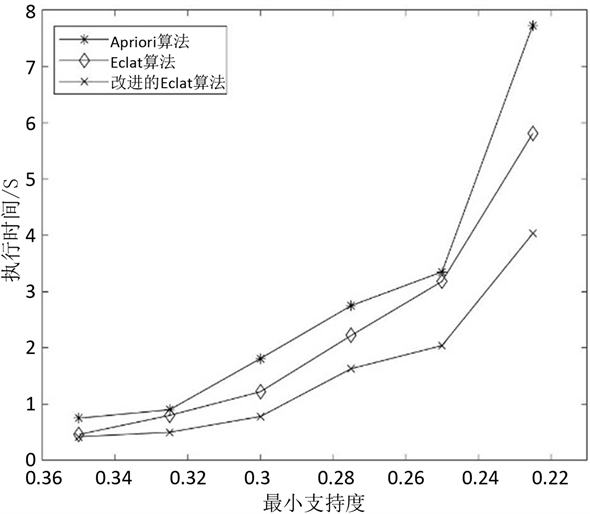
Figure 5. Number of candidate sets under different support thresholds on Mushroom dataset
图5. Mushroom数据集上不同支持度阈值下候选集数量
行对比实验,测试对象仍为稠密数据集:Mushroom,比较Eclat算法在不同优化策略下执行时间随支持度阈值变化情况。测试结果如图6所示。
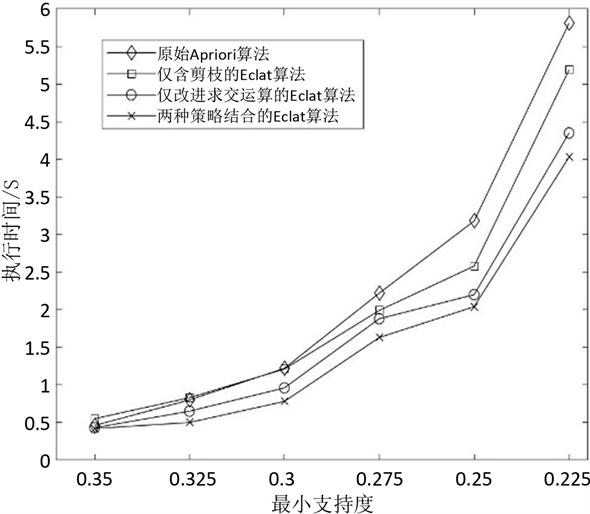
Figure 6. Execution time of Eclat algorithm under different optimization Strategies on Mushroom dataset
图6. Mushroom数据集上Eclat算法在不同优化策略下执行时间
从实验结果来看,不同优化策略的Eclat算法执行时间都随支持度阈值的减小而增加,在同一支持度阈值下,候选集优化和支持度计算改进相结合的算法时间效率要优于原始算法以及仅采用单一优化策略的算法。其中,在两种单一优化算法中,改进求交运算的优化方式要比剪枝优化方式算法运行效率更高,而没有采取任何优化策略的Eclat算法执行效率最低。
实验四:将改进的Eclat算法与原始Eclat算法进行对比实验,测试对象为稀疏数据集:T10I4D100K,测试在支持度阈值一定的情况下两种算法运行时间随事务规模变化情况。其中,事务规模从20,000到100,000变化,最小支持度为0.01。测试结果如图7所示。
从实验结果来看,在给定的支持度阈值下,两种算法的运行时间都是随着事务集数量的增加而增大,但在同一事务集规模下,改进算法的运行时间要比原始算法更低,运行效率更高。
4.2. 结果分析
在实验一中,由于支持度的阈值不断提高,导致满足最小支持度的项集数量减少,即频繁k-项集数量逐渐减少,从而连接产生的候选(k + 1)-项集数量也逐渐减少,因此可以看到算法的候选集数量是随着支持度阈值的增加而减少的。同时,由于Apriori算法本身利用了先验性质采取后剪枝策略,其候选集数量相比未采取任何候选集优化策略的Eclat算法要少,而本文的改进算法不仅利用了后剪枝策略,而且在连接之前还采取了预剪枝策略,前后剪枝策略的结合进一步压缩了候选集数量,因此在一定支持度下改进算法能够产生最少的候选集数量。
在实验二中,由实验一的分析结果可知,支持度阈值的减小会使候选集规模逐渐增大,大量的候选集数量需要更多的连接操作和求交运算,大大增加了时间开销,因此算法的执行时间会随着支持度的减小而增大。同时,虽然Apriori算法的候选集数量要比Eclat算法少,但执行效率反而要比Eclat低,这是由于算法的大部分时间开销都发生在获取支持度的阶段,前者支持度的计算采用的是重复扫描数据库事务的方式,这种方式占用的时间开销很大,尤其在事务规模庞大的情况下,而后者采用了逐项求交的方式,避免
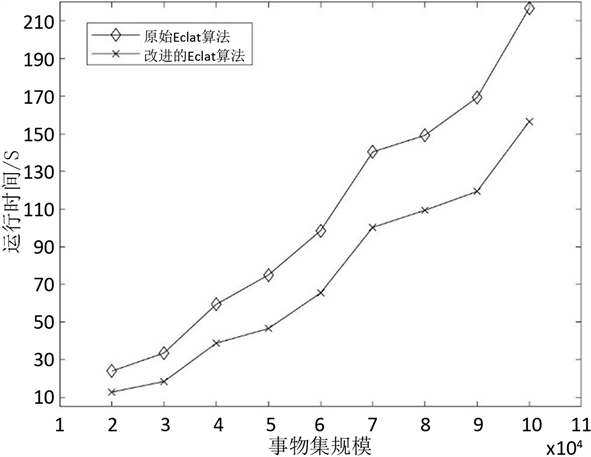
Figure 7. The running time of two algorithms on the T10I4D100K dataset under different transaction set sizes
图7. T10I4D100K数据集上两种算法在不同事务集规模下运行时间
了对数据库的重复扫描,所以Eclat算法效率要比Apriori算法高。本文的改进算法不仅对候选集的产生做了进一步优化,还对求交运算做了改进,时间开销进一步降低,从结果来看确实能够起到提高算法效率的目的。
对于实验三,不管是候选集优化还是改进求交运算,都能不同程度的提高Eclat算法的效率,候选集的前后剪枝在减少了连接判断操作的同时压缩了后续求交运算的项集规模,改进的求交运算则避免了逐项比较的问题,但对提高算法效率的贡献程度来看求交的优化方式比候选集的优化方式效果要好,这也验证了影响Eclat算法运行效率的主要因素在于求交运算过程。
对于实验四,由于事务集数量的增加,导致项集的TID_set规模越来越大,事务的tids越来越长,在求交运算时不管是原始的逐项比较还是本文的索引方法所耗费的时间都将会越来越久,因此随着事务数的增加算法运行时间也在增加。
5. 结束语
本文通过分析Eclat算法中普遍存在的候选集数量大、项集求交效率低的问题,提出了一种新的优化和改进思路,即利用前后剪枝相结合的策略来减少项集连接操作并压缩候选集规模,同时采用基于事务索引的布尔数组取值计数方式改进求交运算。实验表明,不管是稠密数据集还是稀疏数据集,该方法都能在一定程度上减小Eclat算法的时间开销,提高算法的挖掘效率,特别是在支持度阈值小、事务数规模大的情况下。此外,本文的改进算法由于减小了项集的搜索空间,内存占用更小,空间开销也得到了一定的降低。后续的研究工作将集中在算法的具体应用上,以验证本文算法在解决实际问题时的适用性和有效性。
基金项目
国家自然科学基金(61501513)。