1. 引言
最初的数据转换问题(data exchange problem) [1] 是由Fagin等人提出的,他们给出了数据转换的相关定义。文献 [2] 中说明了数据转换通常将源数据作为输入,由一组模式映射的集合(也叫元组生成依赖关系)对源数据进行选择,将其转换为满足给定的模式映射的目标数据集,在此基础上还给出了数据转换过程中通解、核解的概念以及基本求解方法,并将一些相关领域知识转换为约束条件融入到数据转换求解算法中(核解是保留映射语义的解决方案中最小的解决方案,简称核解)。由于在相关研究中核解已被确定为数据转换的最优解决方案,因此在数据集成过程中如何有效快速计算核解非常重要。现有的计算数据转换核解的方法,通常是通过chase方法执行原始的源到目标映射规则生成目标实例,然后应用一些实例选择方法对属于核解的目标实例进行选择。
基于上述研究,已有许多方法对计算核解进行了研究,文献 [3] 从模式映射的角度出发,通过对映射规则进行优化设计,将映射规则转换为可以执行的脚本来计算核解。文献 [4] 在给定元数据约束和数据示例的情况下,给出了一种从潜在映射空间中选择最佳映射的方法。但是这些方法通常不适用于数据源规模较大的大型映射场景,可能导致目标数据库中的数据存在大量冗余数据。文献 [5] 通过弱化目标数据中的约束条件来计算核解,由于该方法只能在特定条件下对有限的数据进行处理,存在一定局限性。关于模式匹配的研究中,大多数研究是关于语义相似性度量方法,文献 [6] 使用WordNet信息引入了一种新的语义相似性度量方法,来处理模式匹配问题。文献 [7] 同样在语义相似性度量方法的基础上提出了一种在半结构化数据和链接数据之间进行模式匹配的方法。关于数据转换的研究中,文献 [8] 提出了一种可伸缩实体保存数据转换(SEDEX)方法,该方法利用在模式级别和数据实例级别的信息解决使用不同方法表示模式间对应关系导致模式映射不准确的问题。为了设计准确的模式映射信息,一些方法 [9] [10] 以交互方式从映射设计器那里获取数据示例,用以设计源模式与目标模式之间的模式映射,并通过将范围较小的多个独立设计的方案映射关联到较大的方案映射构造复杂映射。国内关于数据转换的研究大都集中于ETL技术的研究 [11] [12] [13],ETL技术通常用来描述将数据从来源端经过抽取、转换、加载至目标端的过程。研究过程中的主要问题是解决数据异构性及转换效率提升问题。
传统的模式映射设计中,通常都是通过消除数据值冗余来避免更新的低效性。研究表明,许多冗余的出现都是由于映射规则不完善导致的,因此直接通过重写规则防止在目标中生成冗余数据要比执行不完善的映射规则生成冗余数据后再尝试去删除这些冗余数据更有效。考虑如表1,表2所示场景,表1中的源表A,B,C,D分别代表来自不同web源的源数据库表,表2中的目标表T1,T2是两个不同的目标数据库表。

Table 1. Source database summary data
表1. 源数据库概要数据
Table 2. Target database summary data
表2. 目标数据库概要数据
该映射场景初始给定的模式映射如下:
m1.
m2.
m3.
m4.
上述映射场景中,每个映射规则的源模式都不相同,通过这些映射规则可以将源模式上的实例转换成目标模式上的实例。这些给定的映射规则基本满足映射场景的初始映射规则,可以将源模式上的数据转换到目标模式中。但依据给定的映射规则生成的目标实例包含冗余实例,即表2中灰色背景的部分,这些冗余会影响数据转换的准确性。
基于上述问题,本文提出如下方法:
1) 本文将给定映射规则目标模式上的查询定义为扩展,表示满足映射规则的所有查询公式的集合,它们可以作为一阶查询来捕获目标实例。将矩阵之间的同态关系概念应用到扩展中,通过扩展之间的同态关系,查找到目标实例中满足核解特征的目标实例,扩展间的同态关系称为公式同态。
考虑本文例子中的映射规则m1,它的基扩展为
,合并映射规则m2,m3可以得到第二个扩展
。可以看出,存在由基扩展
到
的同态关系,将这种情况称为通过m2,m3生成的扩展覆盖了m1的扩展,就生成核解而言,第二个扩展比基扩展更好,因为其不含存在量词。
2) 每当为给定映射规则确定了一个比基扩展更合适的扩展时,可以根据以下策略执行映射规则来防止在目标中生成冗余元组。首先通过更合适的扩展查找目标实例,然后使用基扩展只生成那些实际向目标添加一些新内容的目标实例。通过这种方式,我们可以从扩展的角度对核解的特征进行计算,这是本文重写算法的基础。
3) 为了将上述研究转化为实际的重写方法,通过将扩展重写为源模式上的查询公式,扩展的源重写会在源数据库上声明一个条件,以生成目标中与扩展
相关的目标实例。在我们的例子中,扩展的源重写如下:
一旦在源上重写了扩展,可以通过在原始映射规则的前提中添加否定来重写它。每当映射规则m有比基扩展更好的扩展
后,通过添加
的源重写的否定来重写他的前提。
4) 通过本文的示例研究发现,并不是所有规则都会导致目标中生成冗余实例。在对原始规则进行重写时,应去除那些不含存在量词并且源到目标对应关系明确的规则,为此我们给出初始规则选择方法,只选择那些会生成冗余元组的规则进行重写。分析给定的映射规则集,为每条规则分配一个冗余度,用来确定生成目标实例冗余程度,以便识别其中的哪条规则可能在目标中生成冗余元组。
5) 最终根据本文方法可以生成以下规则,它们比普通的映射规则更具表现力,允许在前提中添加否定,可以用来表示原始场景的核心模式映射,通过在源实例上执行这些规则能够生成核解,其中r1、r4为重写后的规则,r2、r3为生成目标数据精确度较高的规则,未进行重写:
r1.
r2.
r3.
r4.
2. 相关概念
定义1. 一阶规则(FO规则)
给定源模式S和目标模式T,一阶规则是形式为
的映射关系,其中
是S上的
一阶公式,
是形式为
的原子的合取式,
可以是形式为
的变量,也可以是
上的Skolem范式 [14]。
定义2. 一阶规则的执行
给定一阶规则
,称
为从
获得的S上的一阶顺序查询,将
视为自由变量。用
表示元组
,这样
就是在S上的实例I,对于查询
的结果。给定
,然后用
表示从
获得的原子集合,用相应的
替换每个变量
,并用相应的不确定量替换每个Skolem项 [14]。
定义3. 核心模式映射
给定映射场景
,如果对于任意源实例I,目标实例
是M在I上的核解,一组FO规则R被称为M的核心模式映射。
定义4. 变量
给定公式
中的原子
,其中变量由
表示。如果
,则
中的变量
是全称量词;如果
,它是存在量词。
在下文中,用
表示所有在
中的变量;
,
分别表示全称变量和存在变量。同样,
,
,
将表示给定变量v的所有(通用的,存在的)变量取值集合。
定义5. 公式同态
给定两个合取范式:
和
,公式同态是一个从集合
到
的映射
。
i)
将
中的全称量词映射为
中的全称量词;
ii) 对于每个原子
,在集合
上存在
与之对应;
iii) 对于存在变量
,变量
,
成对出现,在这种情况下,
和
都是常量,或者是在
中相同的存在变量。
如果一个公式同态
把
中的不同的原子映射到
的不同的原子中,则公式同态
是单射的。如果
中的每个原子都是依据
在
中的某个原子的图像,那么
是满射的。
对于关系
和
上的两个查询公式:
和
在以下变量之间的映射中,存在
到
的公式同态
。
,
,
,
可以看出,由于公式同态的影响,它们可以将左侧的相同变量与右侧不同变量相关联。在本文中,
将通过
来引用变量
。
是与
中的
相关联的变量。考虑上面
的例子,
中出现两次的存在变量
被映射到
中不同的通用变量的位置,实际上,
,而
。
定义6. 公式同态的分类
给定两个合取公式
和
,和一个从
到
的公式同态
。
i) 如果
是满射的,则公式同态
是更紧凑的。可以是
或
的情况。即要么
比
小,要么
包括较少的存在变量;
ii) 如果
是单射的而不是满射的,则
被认为是更适当的,即在
中至少有一个原子不是 的原子的图像。
的原子的图像。
讨论“公式同态”和“事实(公式的所有实例的集合)之间对的应同态”的关系是非常重要的。本文研究公式同态,以便检测作为公式事实之间可能的同态。然而,公式同态并不能保证实际同态在事实之间产生,公式之间的同态映射可以将通用变量的值映射为其他通用变量的值。在实例化公式时,这些变量不一定接收相同的值,公式实例之间的同态可能实现也可能不实现,这都取决于通用变量所假设的值。
考虑关于
和
的公式同态
。包含两个公式的实例:
和
。给定变量值的赋值,可以看出,
的事实集实际上比w的事实集更紧凑。如果改变赋值,通常不会这样。
现在考虑一下:
和
。
中没有
的同态,造
成这种情况的原因有两个。i) 首先,公式同态将
映射为
。通过这样做,公式同态对变量
,
的值进行限制:为了实现公式实例之间的同态,两个变量必须接收相同的值;ii) 其次,
将两次出现的
映射到
;这意味着为了实现同态,
的值应等于
的值。
给定一个公式同态
,可以在与
有关的通用变量之间引入几组等式:
表示
和
之间全称量词的一组等价集(等式集合),这组等式必须成立,才能实现这两个公式实例之间的同态。
表示
的全称量词之间的等价集,其具体的值是
中相同存在量词的值的图像。
直观地说,只有满足
的赋值才能实现公式同态。
3. 模式映射重写
3.1. 扩展
给定一个映射场景
,由
表示在
中的所有映射规则结论的集合,由
表示在R中的所有数量≤k的多重原子集合;每当多重集合中出现相同原子的多个副本时,本文假设它们已被正确重命名,以避免变量的冲突。给定映射场景
,本文的目标是在一组表示M的核心模式映射的一阶逻辑规则下重写给定的映射规则,从中生成一个SQL脚本,直接生成核心目标实例。为了执行重写,将依赖于核解的概念。在本节中,我们将介绍映射规则结论中基于扩展的核解概念,并在下一节中使用它来执行重写,使用扩展作为研究映射规则结论之间可能存在冗余的一种方法。
定义7. 映射规则中的扩展
给定映射场景M和映射规则集
,在
中有映射规则
,m的扩展集合用
表示,
是一组包含存在量词的逻辑查询公式:
,其中
是
中带标记的原子(k是
的大小),且存在满射
,
。
在接下来的文章中,假设扩展中
,
,即
是不相交的。注意扩展
也可以被看作是一个含有自由变量
的查询
。接下来会证明,在通解
上进行这样的查询,结果恰好会返回目标实例集合
中的一组目标实例。
给定实例J,并给
赋值
,如果满足以下条件,则称
:
是
的形式。
由于映射规则结论的扩展数量随着结论之间连接的数量而增加,并且它通常是输入映射规则的大小的指数。将
称为
中映射规则的所有扩展集。
3.1.1. 扩展与核解
根据参考文献 [15] 我们可以知道,在目标数据库存储的目标实例中,为了生成核解,需要选择最大的实例,具体步骤是首先选择包含属性更多的实例,再此基础上选择包含信息性更大的实例,最后将能够
满足
关系的实例称之为核解。我们在本节引入核解的概念,
基于扩展给出核解的相似概念,但是这个核解并不是依赖于实例的而是基于本文所说的扩展生成的。
3.1.2. 扩展的分类
在本文第2节中介绍的公式同态可以用来确定什么时候扩展能够产生一个比其他块包含更多属性或更具信息性的实例,由此引入了一个更紧凑的和更具信息性的扩展的并行定义。
定义8. 更紧凑和更具信息性的扩展
给定由具体实例组成的扩展:
如果存在一个更紧凑的同态
,则称
比
更紧凑,用
表示;
如果存在更恰当的同态
,称
比
更具有信息性,用
表示;
当根据公式同态
使得
比
更紧凑(或更具信息性)时,可以这样写
(
)。
3.1.3. 扩展的选择
根据上述方法,给定一个扩展
,我们可以基于扩展
生成一个新的查询,叫做
。主要通过向
添加
的否定,
比
更紧凑。有如下等式:
定义9. 更紧凑的扩展:
给定一个映射场景M,以及它的一组扩展
,其中的一个扩展如下:
通过如下方式获得:
1) 初始化
;
2) 对于
中的任意
和任意形如
的公式同态
。即
根据
变得比
更紧凑,向
添加公式
。
本文将用
来表示形式为
的扩展所有重写的集合,其中
。
在第一次重写之后,与通过实例生成核解的方法所述的策略相一致,我们在其他扩展中寻找有利于在目标中生成更具信息性的目标实例的扩展,并且进一步重写
。在这个过程中,产生成了一个在
基础上的公式,叫做
,如下所示:
定义10. 更具信息性的扩展:
给定一个映射场景M,以及它的一组扩展
,其中的一个扩展如下:
的具体操作如下:
1) 初始化
2) 对于
中的任意扩展
和任意形如
的公式同态
,即
由
变得比
更具信息性,向
添加公式
。
我们用
表示
形式的所有重写集。
总之,为了选择最大目标实例,本文考虑映射规则tgd中的每个扩展
:
a) 首先通过添加所有的扩展
否定,将
重写成一个新形式:
,
比
更紧凑;本文期望用这些新的公式选择在与
相关的目标实例中更紧凑的;
b) 然后通过添加
的否定,进一步将
重写为一个新的公式
,扩展
比
更具信息性。
与扩展类似,扩展的重写也可以被视为查询。给定扩展
,以及相关的查询
,
和
都可以看作是带有自由变量
的查询。本文编写这些查询如下:
和
。为了简化符号,本文将省略显式引用变量,仅用
和
来代表查询。
3.2. 规则选择
在前文中,通过对初始映射规则结论进行分析,给出了扩展的概念,进而我们希望通过扩展对初始模式映射规则集进行重写以让他可以直接生成核解。但是分析发现,不是所有的规则都会在目标中生成冗余实例。若对初始规则集中的所有规则都进行重写,会导致运行时间过长,效率低等问题。由于有些规则已经满足核心模式映射条件,不需要进行重写就可以直接生成满足核解的目标实例,我们希望对规则集进行选择,只对不满足核心模式映射条件的规则进行重写。
3.2.1. 规则冗余程度
为了识别不同规则生成冗余的大小程度,必须对规则源模式与目标模式之间的属性相似度进行计算。针对本文研究数据特点,由于数据来自不同的web数据源,在计算属性相似度时选用Jaccard相似系数方法来计算源和目标模式属性相似度。
定义11. Jaccard相似系数
给定两个集合A、B,Jaccard相似系数定义为A与B交集的大小与A与B并集的大小的比值,定义如下:
当集合A,B都为空时,
定义为1。
本文称给定规则源模式与目标模式之间的相似系数大于0.7时,该规则生成的目标实例冗余度较低,不需要进行重写。当相似系数低于0.7时,应进行规则分解,查看规则中全称量词的数量来进一步确定该规则是否会生成冗余度较高的目标实例,是否需要重写。
3.2.2. 规则分解
给定映射场景 以及它的初始规则集,本文将根据文献 [16] 中研究的策略来对冗余度较高的给定规则进行分解,具体方法如下。
分析表级之间映射关系的构成,考虑源和目标模式下包含如下对应关系:
1) 1:1映射关系
1:1映射关系是指web数据源模式与目标数据模式中的表结构是一致的,即标准数据库中的某些表在源数据库中有唯一的一个数据与之对应。对于映射关系为1:1的映射规则,若其目标模式中不含存在量词,则不要进行重写,直接作为核模式映射输出。若其目标模式中包含存在量词,这些规则生成的数据中必定包含较多的变量,说明这些规则是冗余的,直接进入待重写的规则库。
2) 1:N映射表关系
1:N映射关系是指web数据源模式与目标数据模式的表结构并非是一致的,即源数据库中原始数据的一个表映射到目标数据库中的多个表。首先将其分解为1:1类型的映射,然后根据其包含存在量词的数量来确定其冗余程度的大小,判断是否需要对其进行重写。
3) N:M映射表关系
N:M映射关系是指web数据源模式与目标数据模式的表结构并非是一致的,即源数据库中原始数据的多个表映射到目标数据库中的多个表。当规则中的映射关系为M:N时,可以首先将其转换成M个1:N的映射关系;然后再将1:N的映射处理为N个1:1之间的映射;最后对M * N个1:1的映射关系进行判断处理即可。在其中若不包含存在量词,则作为核心模式映射输出;若其中包含存在量词,则其冗余度较大,需要按照本文方法进行重写,转换成核心模式映射来计算核解。
3.3. 重写方法
3.3.1. 源重写
扩展作为目标模式上的公式,在本节中表明可以根据源模式上的关系来重写扩展,我们将其称为扩展的源重写。虽然扩展是一个用于在目标模式中选择原子的查询,但它的源重写说明了这些原子存在的“前提条件”。通过引入标签技术 [2],在源上重写扩展的策略得以实现。事实上,扩展是从映射规则结论中得到的标记原子的合取范式。对于每一个原子,都用一个前提联系起来(前提就是相应的规则的左侧)。通过连接其所有原子的前提,能够获得扩展的源重写。注意到标签系统在这一步中起着核心作用:通过查看每个扩展的原子的标签,可以立即知道它的出自哪一个映射规则,因此也就知道了它的前提。
定义12. 映射规则的前提
给定映射规则
和原子
,
的前提
实际上是由映射规则的左侧公式
构成的。
给定一个查询公式
,其具体前提由如下公式表示:
定义13. 源重写
给定映射规则
和扩展集合
中的扩展
,它的源重写
是下面的公式:
注意到,虽然tgd的扩展
可以看作是一个查询
,
包括映射规则m的全称量词和存在量词,它的源重写
,也是一个查询
,但其中所有自由变量都是映射规则m的全称量词。
3.3.2. 源重写的否定
给定扩展
,它的源重写
说明了产生其所有实例的前提条件。本文只想选择关于信息量最大的,最具代表性的实例。因此,需要生成新的表达式,分别为与扩展相关的最紧凑和更具信息性的见证块集提供前提条件。
为了进行上述操作,给定扩展
,引入公式
和
,类似于
和
,但是在源上重写了。为了生成
,每当扩展
比
更紧凑时,在
的源重写中加入
的否定。
定义14. 重写源上的mostComp()
给定场景M,以及M上的一组扩展
,他们的重写是
, 对于扩展集
中的每个
,其公式
生成的方式如下:
i) 首先初始化
ii) 然后对于扩展集
中的任何扩展
,若
是比
更紧凑的,称
为从
到
的更紧凑的同态;向
添加一个公式:
定义15. 重写源上的mostInf()
给定场景M,以及M上的一组扩展
,对于扩展集
中的每个
,其公式
生成的方式如下:
i) 初始化
ii) 然后对于扩展集
中的任何扩展
,若
是比
更具信息性的,称
为从
到
的更恰当的同态;向
添加一个公式:
3.3.3. 重写算法
现在准备介绍本文的最终重写算法。主要介绍一个映射场景M中扩展规则的概念,由于希望规则被规范化。因此,使用公式
为每个规范化的扩展
都建立一个规则,其中将只有全称量词出现作为前提条件。在
不是规范化的情况下,生成一系列规范化规则,由
表示,
中每个规范化分量对应一个规则。
定义16. 扩展规则
对于扩展集
中的每个扩展
,都生成一组扩展规则
,其形式如下:
其中
是
的规范化分量。映射场景M的扩展规则集如下:
正如前面几节所讨论的,一个简单的优化是由仅为原子集为核解的扩展生成的扩展规则组成。
为了处理非标准化块,我们在规则结论中寻找适当的同态:我们将公式同态的概念扩展到Skolem公式,将Skolem项考虑为存在量词;然后进一步的进行重写,如下所示:
定义17. 最终重写finalRew()
对于每条属于
的规则r,规则
通过如下方式获得:
将在规则选择过程中冗余度较高的规则r称为分解规则。
若r不是分解规则,
。
若r是形式为
的分解规则:
i) 首先初始化
;
ii) 对于
中的任意规则
,根据同态
说明
是比
更具信息性的,向
增加一个前提公式
。
最后构成了一组新的一阶逻辑规则,具体表示如下:
4. 实验结果
4.1. 数据集
本文采用的数据集是从中国土地网、链家网等房产信息网站爬取的500多万条数据,经过垃圾清理、无意义信息删除两个预处理过程,数据信息属性如表3所示。
Table 3. Real estate information data sheet attribute description
表3. 房地产信息数据表属性说明
为了评估本文提出的模式映射优化方法的可行性和有效性,我们从数据集中筛选出部分高质量房产信息数据构建实验数据集,现实世界中的真实数据很难全面的展现所有问题,因此,采用上述数据集构造了人工数据集,表4显示了构建数据集的关键特征。针对个本文构建数据集模式及目标数据模式即S和T构建模式映射,选取其中12个作为基本映射集,这些模式映射可以满足源和目标模式的基本要求。
Table 4. Property description of the Weibo data table
表4. 实验用评测数据集
4.2. 实验设置
本文将按照以下两种策略来衡量本文算法的有效性以及与同类工作相比的优越性。首先比较不同数据集下的信息准确率,信息准确率是指映射规则能描述完整的源模式及目标模式信息,包括文档结构信息以及语义约束信息等。映射规则中的每一个分量都不可再分,任意两个属性不能完全相同。映射规则的完整性代表着规则的完善程度,也标志着根据其生成的目标实例存在少量冗余信息。在本文节中,信息准确率是根据本文方法重写规则后生成的满足核解特征的实例数量占总目标数据库中存储实例数量的比例,如下列公式所示:
接下来本文将根据优化后的模式映射生成的数据中冗余缩小程度来评估本文方法的可行性,冗余缩小程度即结果生成的数据包含冗余数量占总数据的百分比与之前数据集中重复率大小的比值,如下列公式所示:
4.3. 实验结果
图1比较了本文方法SMO与其他两种方法TKM [17],SRMIS [18] 的比较结果。如图所示,在三个数据集的测试中,本文方法都能保持较高性能,信息准确率始终高于80%,TKM方法性能表现次之,这主要是由于其固有的缺点,即它的基于语义逻辑的映射选择策略,这可能导致不同应用场景的模式映射结果存在巨大差异。SRMIS的信息准确率仅达到70%左右,在本文数据集中的表现结果最差。
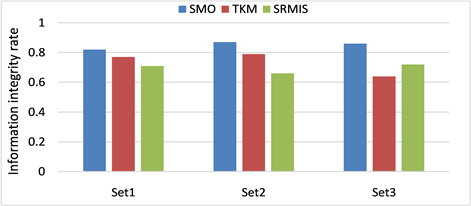
Figure 1. Information integrity comparison
图1. 信息完整性对比
图2显示了随着数据规模的增大,本文方法与其他两种方法的冗余程度。如图所示,当数据数量为100 k时,当源实例数据量小于500 k时,三种方法都具有较好的处理性能。当源实例数据量增加到1 M时,SRMIS,TKM两种算法对冗余的缩小程度明显下降。当源实例数据量增加到5 M时,本文中提出SMO方法可以将冗余缩小程度维持在85%以上,其他两种方法在处理数据量较大的数据集时,表现不佳,但很明显本文方法在降低大型数据集冗余程度时性能更好,效率更高。
5. 结论
本文首先分析了传统的数据转换核解计算方法的不足之处,继而对上述现有的核解计算方法提出改进,并针对模式层数据转换问题提出了模式层数据转换映射重写方法,进而对本文方法的查询效果做了理论分析,在真实数据集中验证了本文方法的有效性,证明本文方法在很大程度上减少了冗余数据数量,降低了转换成本。本文方法需要在已有研究的基础上,进一步研究包含连接情况的映射处理的问题,分析映射关系之间的依赖性和数据的分布特性,优化转换效率,以进一步降低转换成本,提高算法的转换效率。