1. 引言
自从苹果公司于2007年发布第一代iPhone以来,智能手机极大地改变了人们的日常生活,手机性能的提升增加了手机的应用场景,伴随着互联网技术的发展,智能手机的作用越来越大。拍照、录像、网络社交、游戏、视频通话等许多功能都依赖于手机来实现。手机配置的提升,要求手机处理器要有相当强大的运算能力。因此人们对软件应用需求的增大也反过来迫使厂商增强手机性能。
董骐瑞 [1] 提出K-means最优聚类数的确定存在不足,从而改进了K-means算法。凌静 [2] 等人提出一种结合模拟退火算法的遗传K-means聚类方法,以此避免聚类陷入局部最优。黄晓辉 [3] 等人发现K-means算法主要考虑簇内距离,而忽略了簇间距离的作用,并提出一种新的集成簇内和簇间距离的加权K-means算法。王巧玲 [4] 等人针对K-means算法随机选择初始聚类中心和K值所导致的精度不高问题,提出了一种基于聚合距离的改进K-means算法。唐泽坤 [5] 等人针对K-means算法对初始聚类中心和噪声敏感的缺点,提出了d-K-means算法,能够更好地选择聚类中心。刘越 [6] 提出了一种改进的K-means以降低算法的时间复杂度。黄继超 [7] 针对K-means中K值的模糊性,提出了使用距离代价函数来确定准确的K值。
处理器对智能手机的重要性相当于大脑对人类的重要性。本文选用了2015年至2019年手机市场主流的51款处理器,涉及到13种指标,利用K-means算法对其进行聚类。旨在将不同年度、不同定位、不同产商的处理器聚合到适合各自的簇中,以此可以对市场上铺天盖地的各款手机性能有更好的理解,对采用了不同簇的处理器的手机定位也能有一个参考。
2. 改进K-Means聚类算法
2.1. 传统K-Means聚类算法
作为一种无监督学习算法,K-means (K均值聚类算法,也称作快速聚类法)由于其简单高效、聚类效果良好等特点,被广泛运用于各种领域的样本聚类。
K-means聚类算法最早是由Macqueen于1967年提出,K指的是类的个数,即聚类簇数。其基本思想是对给定的样本集,先确定聚类簇数K以及K个聚类中心(均值),再计算各样本到聚类中心的距离,将其划分到最近中心点所在的簇。K-means是一种迭代算法,大致步骤如下 [8]:
步骤1:确定K值,在K-means聚类算法中,K是唯一的参数;
步骤2:将样品初步分成K类,一般是从数据集中随机选取K个样本作聚类中心(明显聚类中心为向量);
步骤3:逐个计算样本到各聚类中心的欧式距离,并将其派送到最近的聚类中心所在的簇,直至所有样本都分配完成;
步骤4:重新计算各簇的聚类中心(即各簇内的样本均值),若与上一个聚类中心相同,则算法运行结束,若不同,则用新聚类中心取代旧聚类中心,重复进行步骤3,直至聚类中心相同。
并且一个样本只能属于一个簇,每个簇至少要有一个样本。
2.2. 手肘法改进K-Means算法
设数据集的样本总数为n,K-means算法的迭代次数为t,可知该算法的复杂度为
。对于K值的选取,可以由个人经验所得,也可由手肘法 [9] 计算得出,手肘法是利用SSE(误差平方和):
(1)
以此来得出K值。其中
为各簇中样本的数量,满足
,
为第q个簇里的第l个样本,
为第q个簇里的聚类中心。
手肘法的思想是:随着K值逐渐增大,样本的划分会更加细致,随着各个簇聚合程度的逐步提高,SSE也会随之变小。同时,当K值小于最优聚类簇数时,由于K的增大会较大幅度地增加每个簇的聚合程度,所以SSE的下降幅度会比较大;而当K值到达最优聚类簇数时,再增加K值,簇增加的聚合程度就没有之前高,SSE的下降幅度会大幅变小,逐渐趋于平稳。所以SSE与K值之间的关系图类似手肘的形状,肘部对应K值就是最优聚类簇数。K值是K-means算法中唯一的参数,选取最优K值可以在一定程度上改进K-means算法。
2.3. 计算距离并分配到簇
先将原始数据集标准化,以消除量纲的影响。本文采用的是Z-score标准化:
(2)
是标准化后生成的新数据,
为原始数据,
为第i个指标均值,对本文数据而言,
。
从标准化后的数据中,按照2.2节手肘法确定K值,随机选取K个样本
作为初始聚类中心,计算样本
到各聚类中心的欧氏距离 [10]:
(3)
对于样本
,选取离其最近的聚类中心,并标记
,将样本
划分到簇
中。直至所有样本分配到各簇中,进行步骤4即可。
3. 运用改进的K-Means聚类算法对手机处理器进行聚类分析
目前主流的手机处理器公司有美国高通(骁龙Snapdragon系列)、苹果(A系列),韩国三星(Exynos系列),中国华为海思(麒麟Kirin系列)、联发科(Helio系列)。其中苹果、三星与华为自家都有手机产品,而高通与联发科仅研发处理器,没有手机品牌。
本文选取了全球市场上51款主流手机处理器进行分析,共涉及到5个品牌:高通、苹果、三星、华为海思、联发科;13个指标:CPU单核跑分
、CPU多核跑分
、GPU跑分
、内存带宽
(GB/s)、网络下行速度
(Mbps)、网络上行速度
(Mbps)、制程工艺
(nm)、闪存读写速度
(GB/s)、内存主频
(MHz)、支持摄像头数量
、最大内存容量
(GB)、最高摄像头像素
(万)、屏幕最大显示像素
。
其中CPU单核跑分、CPU多核跑分取自Geekbench官网;GPU跑分取自3D Mark官网;内存带宽、网络下行速度、网络上行速度、制程工艺、闪存读写速度、内存主频、支持摄像头数量、最大内存容量、最高摄像头像素、屏幕最大显示像素取自各产商官网。数据见表1:

Table 1. Indicators of mobile processor
表1. 手机处理器各项指标
利用式(2)对原始数据进行标准化处理,再利用式(1)求出SSE与K值之间的关系,结果如图1所示:
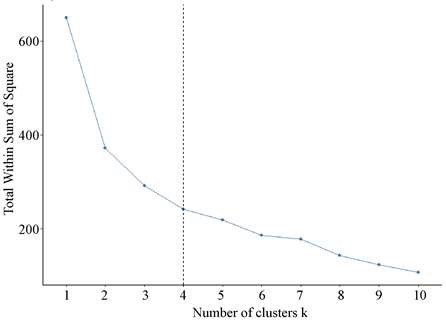
Figure 1. Elbow method to confirm the optimal K value
图1. 手肘法确认最优K值
从图1可以看出,肘部对应的K值为4,最佳聚类簇数为4。利用式(3)计算距离,分配样本到簇,重复进行步骤3与步骤4,得出4个簇以及簇中样本,见图2:
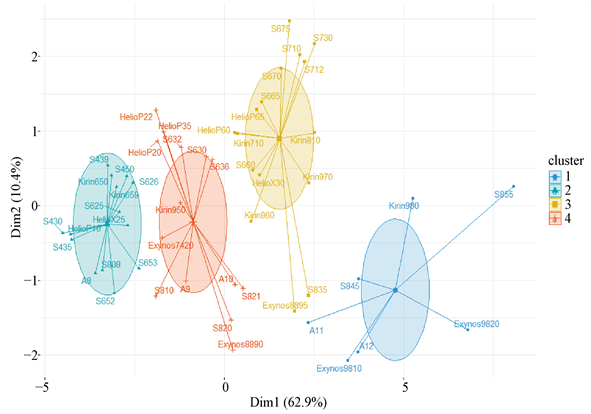
Figure 2. K-means clustering results of mobile processor
图2. 手机处理器K-means聚类结果
4个簇中分别包含了7、16、14、14个样本,其中1类处理器的各项指标大多数领先其他类的处理器,可以看出1类为高端处理器,事实上1类中的A12、Kirin980、S855、Exynos9820分别是苹果、华为海思、高通、三星在2019年的旗舰处理器,而A11、S845、Exynos9810则是2018年的旗舰处理器,符合事实。而2类则是中端与旧高端处理器的集合,它们的CPU多核、内存带宽等方面相差不大,但旧高端处理器(如2017年的Kirin970、S835、Exynos8895)在GPU以及网络上行速度、下行速度方面有着明显的领先;而中端处理器(如2019年的Kirin810、S730)在CPU单核、最高摄像头像素方面则领先。4类则是中低端处理器与年代更为久远的高端处理器的集合。3类处理器的各指标大多数落后于其他类的处理器,是低端处理器的集合。
4. 结论
本文改进了K-means算法中K值的选取,并对2015年至2019年手机市场主流的51款处理器进行聚类,得到了4个类别,并结合原始数据将其分为高端(1类)、中端(2类)、中低端(4类)、低端(3类)处理器。由此可以对市场上不同品牌不同处理器的手机做横向纵向对比,对采用了某款处理器的手机在市场上的定位也能提供重要参考。但是K-means算法只能将样本分为指定的K个类,无法对类别做出分级,因此对于聚类结果的分析,需要依赖人为主观因素,如本文将聚类结果分成不同等级。这也说明K-means算法依旧存在需要改进的地方。
基金项目
贵州省教育厅青年科技人才成长项目(黔教合KY字[2018] 142)。