1. 引言
根据《政务信息资源共享管理暂行办法》(国办发〔2017〕39号)要求,要加快推动政务信息系统互联和公共数据共享,充分发挥政务信息资源共享在深化改革、转变职能、创新管理中的重要作用,增强政府公信力,提高行政效率,提升服务水平 [1]。目前政务大数据中心的建设日趋完善,政府部门数据共享也在积极推动,打破信息壁垒,优化政府管理流程和提升协同治理能力成为当务之急 [2]。随着数据共享交换逐步深入,对数据质量的要求也在逐步提升,出现了大量的多源异构政务数据融合的数据治理需求。本文就政务数据多源融合过程中常遇到的编码映射问题,通过尝试统计学的方法,为不同业务场景下产生的异构法人登记状态建立起准确的映射关系。
2. 现状与问题
政务管理工作体系庞大而复杂,相同的实体对象,例如自然人、法人等,在不同的政务场景下都有数据产生。不同的管理层次、管理策略,加上辅助政务的系统由不同的开发商在不同的年代开发,因此对实体数据的记录方式也有着较大的差异,进而产生了大量的政务异构数据。
与此同时,不同政务场景下,不同的政务系统对实体的相同属性建立了不同的策略的数据编码规则,这些编码都是根据场景的需求及当时的管理策略建立的,日积月累而成,因此不同的场景下的相同实体属性编码存在较大的差异 [3]。
政务大数据中心为了满足不同政务部门的数据应用需求,提供质量更高的数据服务,就需要想方设法融合这些多源异构编码,即建立编码映射关系。
常规的方法基本上都是依靠数据来源政务部门的协调来寻求编码的一致性或建立映射关系,但这种方法周期长,难度大,并且难以持续应对实际政务过程中的不断变化 [4]。
因此,在不断追求数据融合质量、效率的目标引导下,政务大数据中心不断探索、寻求更优化的方法来解决多源异构编码融合问题。本文通过一个实际问题的实践,探索运用统计学算法来解决此类问题。
3. 异构编码融合问题实例
在政务大数据中心法人实体数据治理过程中,出现了如下的实际问题。
法人实体(包含法人和其他组织,以统一社会信用编码的管理范畴为准)的数据有两个来源A、B,所包含的法人数据范围有部分重叠,例如都有企业、个体工商户等类别法人实体,同时也都有另一来源没有的类别法人实体。
根据数据融合需求,融合后法人实体数据使用A来源法人实体登记状态编码,因此需要建立B来源编码和A来源编码的映射关系。
通过数据探查发现两个来源的法人实体登记状态有着不同的定义和编码结构,具体的情况如下:

Table 1. A source legal entity registration status code
表1. A来源法人实体登记状态编码表
Table 2. B source legal entity registration status code
表2. B来源法人实体登记状态编码表
从表1、表2中可以发现两种编码的逻辑规则有较大差异,并且发现如下的问题:
1) 一码多义,在A来源的编码中,“0003”的含义是“注销”,而在B来源的编码中,“0003”的含义是“停业”;
2) 一义多码,在A来源的编码中,“注销”的编码是“0003”,而在B来源中“注销”的编码是“0004”;
3) 含义模糊,B来源中,“0002,迁移”、“0007、迁出”,其含义无法确定是指迁出区县、还是迁出城市。
通过对比分析,发现两个来源的相同法人实体登记状态不同,如表3所示,A来源中状态为“确立”的法人实体,在B来源中对应了多种编码,同样,B来源中状态为“确立”的法人实体,在A来源中也对应了多种编码。
Table 3. A and B source legal entity registration status difference statistical sample data
表3. A、B来源法人实体登记状态差异统计样例数据表
4. 基于列联分析构建映射关系
目前关于政务数据方面的异构编码的映射问题,相关的文献介绍较少,而且运用统计学的方法来解决政务数据的实际问题更是少之又少。本文通过多方面尝试,经过分析发现列联相关分析法的适用场景和本文所面对的问题非常接近。
当研究两个属性变量之间是否有联系时,需要用到列联表 [5]。列联表又称交互分类表,所谓交互分类,是指同时依据两个变量的值,将所研究的个案分类。交互分类的目的是将两变量分组,然后比较各组的分布状况,以寻找变量间的关系。
列联表分析主要包括两个基本任务:一是根据收集的样本数据,产生二维或多维交叉列联表;二是在交叉列联表的基础上,对两个变量间是否存在相关性进行检验。通常情况下,在获得列联表数据之后,我们将会通过统计假设检验两个属性变量是否具有独立性,进而进行列联表分析。
根据算法要求,首先构建列联表,在对列联表行列属性各类别进行命名时,如果法人状态为确立,对应的编码为0001,则命名为:1-确立,以此类推。最终我们根据两个来源的编码及其对应的编码数量构建的列联表如表4。
4.1. 列联分析:独立性检验
对于两个分类变量的分析,称为独立性检验,分析过程可以通过列联表的方式呈现,也把这种分析称为列联分析。独立性检验就是分析列联表中行变量和列变量是否相互独立,也就是A来源的法人实体登记状态和B来源之间是否存在依赖关系。
H0:两者之间是独立的(不存在依赖关系)
H1:两者之间不独立(存在依赖关系)
用SPSS进行列联分析的独立性检验,输出结果如表5:
Table 4. A and B source legal entity registration status contingency
表4. A、B来源法人实体登记状态列联表
a. 12个单元格(24.0%)的期望计数小于5。最小期望计数为0.04。
从表6可得,卡方值为2,376,277.06,相伴概率小于0.001,故应拒绝原假设,认为两者之间不是独立的,两个来源的数据之间存在依赖关系。
4.2. 列联表中的相关测量
接下来需要探讨的问题是,如果变量之间存在联系,它们之间的相关程度有多大?
对两个变量之间相关程度的测定,主要用相关系数来表示。经常用到的品质相关系数有以下几种。
1)
相关系数,是描述2 × 2列联表相关程度最常用的一种相关系数。
是之前计算出来的,n为列联表中的总频数,也即样本量。
2) 列联相关系数,又称列联系数,简称c系数,主要用于列联表大于2 × 2的情况。c系数的计算公式为:
当列联表中的两个变量相互独立时,系数c = 0,并且它不可能大于1,这一点从式中也可以看出来。由于其计算简便,且对总体的分布没有任何要求,所以列联表系数不失为一种适应性较广的测度值。
3) V相关系数,鉴于
系数无上限,c系数小于1的情况,格莱姆提出了V相关系数。V相关系数的计算公式为:
当两个变量相互独立时,V = 0;当两个变量完全相关时,V = 1。所以V的取值在0~1之间。
根据这些计算公式,用SPSS来计算列联相关系数,结果如下:
Table 6. Contingency correlation coefficient
表6. 列联相关系数
对于同一数据,系数
、c,V的结果不同,此处只看c,V的结果,从表7可以看出,c = 0.881,V = 0.930,这两个数值相对来说都是很大的,说明A来源的法人状态和B来源的法人状态的数据具有很强的相关度。
4.3. 列联表的对应分析
在得到A、B两来源之间有很强的相关性,继而研究两来源登记状态编码之间的映射关系。运用对应分析方法就能解决这个问题。它们之间的距离越近,表示它们有差不多一样大的“得分”,从而认为它们相互对应。
SPSS软件的Correspondence Analysis模块是专门进行对应分析的模块,下面是用此模块对本文要解决的问题进行分析,可以得到输出结果如下:
a. 对称正态化。
a. 对称正态化
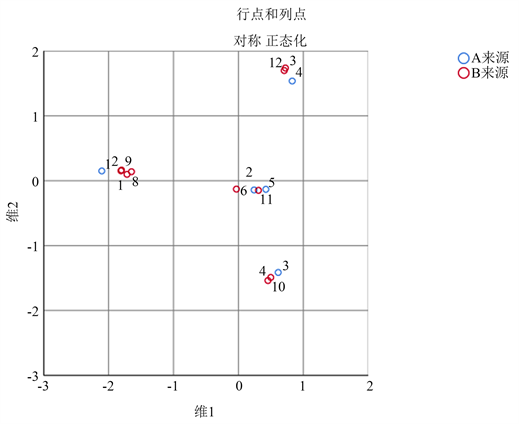
Figure 1. Correspondence analysis diagram
图1. 对应分析图
其中,输出的第一部分如表7对应表是由原始数据按A来源与B来源的列联表,可以看到观测总数n = 686493。
第二部分表8摘要表给出了总惯量、奇异值及每一维度(公共因子)所解释的总惯量的百分比的信息。奇异值反映的是行与列各状态在二维图中分值的相关程度,惯量比例部分是各维度分别解释总惯量的比例及累计百分比。
第三部分(表9)和第四部分(表10)是对列联表行与列各状态有关信息的概括。其中,数量部分分别指列联表中行与列的边缘概率,维得分是各维度的分值,也就是行与列各状态在二维图中的坐标值,惯量是每一行(列)与其重心的加权距离的平方,贡献部分是指行(列)的每一状态对每一维度(公共因子)特征根的贡献及每一维度对行(列)各个状态的特征根的贡献。由此可以更好地理解维度的来源及意义,如第一维度中,A来源的1类型对应的数值最大,为0.773,说明A来源的1状态对第一维度的贡献最大。而对于A来源的2这一状态,两个维度对其贡献度都不是特别大。
输出的最后一部分图1对应分析图是A、B来源的各状态同时在一张二维图上的投影。在图上既可以看到每一变量内部各状态之间的相互关系,又可以同时考察两变量之间的相关关系。可以看出,A来源的五个状态分布较为分散,很明显形成五大类;对于B来源,1、2、8、9被分为一类,3、12被分为一类,4、10被分为一类,6和11各自被单独分为一类。同时考察两变量各状态,可以看到A来源的1状态和B来源的1、2、8、9状态距离较近,A来源的4状态与B来源的3、12状态距离较近,A来源的5状态和B来源的11状态距离最近,B来源的6状态距离A来源的2状态距离最近,A来源的3状态和B来源的4、10状态距离较近。
对此可以绘制对应表格如下表11所示:
Table 11. Legal entity registration status code mapping table
表11. 法人实体登记状态编码映射表
4.4. 映射结果校验
为了验证由此种方法得到的关于异构编码映射关系的准确性,我们利用互联网渠道和信息服务平台,如企查查、天眼查等,采用随机抽样和分层抽样的方法来调查和验证法人实体登记状态数据的拟合度。选取了约400个法人实体,通过互联网渠道和信息服务平台查询核对法人实体登记状态,与通过列联分析法融合后的法人实体登记状态相比,最终的重合度达到96.67%。说明我们构建的映射关系非常准确。
5. 实践小结
本文从政务大数据融合过程中遇到的异构编码问题入手,致力于解决当前典型的异构法人实体登记状态编码映射的难题,通过运用列联相关分析、对应分析等统计学方法,科学、快速、低成本地解决了异构法人实体登记状态编码映射问题,为各部门之间信息共享和业务协同的基础之一,肩负着减少社会负担,提升行政效率的使命,也是建立社会信用体系、企业公信力的重要数据依靠;而且通过第三方公共来源数据验证了该结果的准确性,总体取得了较好的融合效果。
在政务多源异构数据治理融合工作中,类似的情况还有很多,本次实践运用了统计学的部分算法解决了实际问题,为常规的政务多源异构数据治理提供了一种新的思路、方法和参考 [6]。以此类推,人工智能、深度学习等新兴技术,也可以运用到数据治理过程中的某些场景,来帮助数据治理人员解决实际问题 [7]。
在当前大数据技术高速发展时代,政务数据治理工作有必要打开眼界,运用多学科技术不断降低数据治理成本、提升数据治理效率与质量。