1. 引言
云计算服务,指的是基于互联网的相关服务的增加、使用和交互模式,通过互联网技术来提供可扩展以及可虚拟化的资源。但由于其服务架构日渐庞大,系统相对应的性能指标数据也会随之增多,都需要大量的运维人员来对系统环境进行部署和维护,González等人 [1] 曾指出一个简单的异常可能会带来无法想象的连锁反应。
然而,异常目前还没有一个统一的定义,不同的应用场景和领域发生的异常也会有不同的定义。著名统计学家Hawkins等人所定义的异常值 [2] 是指偏离整体样本的观察值,是在所有样本中偏离大多数正常数据的极端值。经过长年的发展,异常检测的相关工作分成了不同类型。基于规则的异常检测方法主要包括Cohen等人 [3] 提出的RIPPER和Quinlan [4] 提出的C4.5算法等典型算法,该类异常检测算法具有算法简单等优点,但是需要专家经验和人工辅助,不能只依靠数据集中学习到的规律,并且规则也会随着数据集的变化而变化;基于统计的异常检测方法最早是由Barnett等人 [5] 提出,研究数据集服从于某种分布(如正态分布、二项式分布或泊松分布)或概率模型(如高斯模型、回归模型或直方图),该类方法根据数据分布能够快速有效地找出异常数据,但其只适用于单变量离群检测,较难确定模型概率分布,检测效率较低,对于高维数据处理能力不足。
随着信息技术的不断提高,对数据采集的颗粒度越来越细,基于规则和统计的异常检测方法在正确率和效率上已无法满足需求。因此,基于机器学习的方法开始被提出,这类异常检测方法可以分为以下四类:1) 基于距离的异常检测。其代表是Ramaswamy等人 [6] 提出使用基于距离的方法解决异常检测问题,采用K-最近邻(K-nearest neighbor, KNN)算法,这种方法无须了解数据分布,无须带标签的训练集,数据类型要求不高,但是由于其计算复杂度高,难以确定参数,在应用中也受到了一定的限制。2) 基于密度的异常检测。Breunig [7] 等人提出的基于局部离群因子(local outlier factor, LOF)是其中一个经典的方法,通过离群强度概念量化异常程度使其异常检测效果较好,但是时间成本和复杂度随维数增加,同时参数设置较难。3) 基于概率统计的异常检测。Li Z等人提出的COPOD算法 [8] 是一种基于统计概率的异常检测算法,优点在于运行开销小,速度快并且不需要设置参数;Zheng Li等人 [9] 提出的ECOD算法是一种计算速度快,且适用于高维数据集的算法。4) 基于分类的异常检测:南京大学周志华教授团队提出了iForest算法 [10],这种基于树的算法凭借线性的时间复杂度和优秀的准确率已广泛运用在工业界的结构化数据中,但建树完毕后仍然有大量的维度没有被使用,所以不适合高维数据的异常检测。
近年来,深度学习成为人工智能和机器学习中极为重要的部分。通过对数据的特征表示和提取以及设定不同类型的异常分数,基于深度学习的异常检测更是取得了巨大的进展。2018年图灵奖得主Yoshua Bengio教授团队提出的基于自编码器的异常检测方法 [11] 是许多深度异常检测模型的核心,Wang等人提出的DeepFD方法 [12] 运用了自编码器、图嵌入等技术来检测二分图中的结构异常;Zhang等人提出的城市时空异常检测方法 [13] 使用了时空特征神经网络来检测时空数据的异常;Zheng等人提出的OCAN方法 [14] 运用了自编码器、LSTM以及生成式对抗网络(GAN, Generative Adversarial Networks)等技术实现了时间序列异常检测;基于LSTM的异常检测方法Deeplog [15] 和LogAnomaly [16] 也在日志异常检测中被提出。尽管基于深度学习的异常检测算法不断涌现,但是当前的深度学习算法在一定程度上体现出来的是可解释性较差,算法结果的好坏依赖于距离定义的方法,即阈值的计算与选择比较困难,同时在训练模型的时候大量的模型会占用过多的计算资源。
在本文中,我们提出了一种基于GCN-LSTM的云计算服务异常检测算法,联合提取云计算服务器的空间特征与时间特征来进行构造。首先通过图卷积神经网络来学习云计算服务器之间的空间信息,然后利用长短期记忆神经网络学习云计算服务器的时间序列信息。使用两者共同建立可重构时间序列重构模型,然后根据重构值和真实值的偏差,使用COPOD [8] 来训练误差并定义异常结果,最终构建云计算服务异常检测算法。该方法为一种无监督算法,使用时无需额外的超参数优化,同时可以体现一定的解释性。
2. 研究方法
2.1. 任务描述及算法框架
为了保证云计算服务的性能和可靠性,运营商需要持续监控系统的状态性能指标。其中的指标包括CPU使用率、每秒I/O请求数、网络吞吐量等,这些指标可以为了解云计算服务器的运行状态检测提供有效的参考信息。当服务器相关性能指标的观测值偏离大多数正常数据时,若运维人员没有有效检测并介入进行维护,表现到真实世界的可能是整个云计算服务器的网络故障告警风暴。因此,本文的异常检测任务便是充分利用相关信息,检测出云计算服务器异常的历史时间快照,并设计一个异常检测算法。
本文提出的异常检测方法首先通过建立图模型描述云计算服务器的空间特征和属性,并通过GCN模型提取其空间信息,然后将不同时刻的空间信息构成时间序列输入到LSTM模型从中提取时间信息,使用训练好的GCN-LSTM模型对时间序列进行重建。最后使用基于Copula函数的方法对重构误差进行尾端概率的判定和异常分数的确定并最后返回异常判断结果。所提出的算法框架图如图1所示,GCN-LSTM序列重构模型表示将云服务器时长度为 的历史指标数据
重构为
;通过
与
相减的方式误差
构建
并将重构误差数据按照比例划分为
和
;使用
数据集训练COPOD方法,获得异常阈值和异常分数后,使用
数据集进行异常检测任务。
图1中各部分模块将在本章进行介绍。
2.2. 基础知识
2.2.1. 图卷积神经网络
图神经网络(Graph Neural Network, GNN)是近年来出现的面向图结构数据的深度学习技术。由于图神经网络处理的数据结构是图,在处理非欧几里得空间结构的数据有巨大的优势。在这其中,使用最广泛的是图卷积神经网络 [17] [18] (Graph Convolutional Network, GCN)。
GCN的目的就是利用卷积来提取非欧结构数据的空间信息以及属性信息,能够深入挖掘图模型中的特征规律,根据Kipf等人的定义 [19],给定一个无向图
由节点集合V和边集合E构成,A为邻接矩阵,其中
,输入变量X和输出变量Y,图卷积神经网络所采取的处理方式如式(1),图卷积神经网络的前向传播公式如式(2),其中
,I为大小是
的单位矩阵;
为无向图的度矩阵;
表示第l层的输出值;
表示第l层的参数值;
为激活函数。
(1)
(2)
如图2所示,图卷积神经网络的本质就是将各个节点的特征与其有连接的节点的特征信息加权平均后传播到下一层,并随着层数的加深,每个节点可以聚合到的节点信息就更远,从而表示整个图模型的结构特征并进行下一步操作。

Figure 2. Schematic diagram of GCN spatial feature extraction
图2. GCN空间特征提取示意图
2.2.2. 长短期记忆神经网络
基于长短期记忆神经网络(Long Short-Term Memory, LSTM)是循环神经网络(Recurrent Neural Network, RNN)的一种,由于RNN在训练时都会将自身提取的信息传递到下一个单元,当该链条的长度累积到一定程度时候便会出现信息的消失。LSTM的出现为的就是解决长序列训练过程中梯度消失和梯度爆炸的问题,相比起常规的RNN,LSTM能够在更长的序列中有更好的效果,LSTM内部模块示意图如图3所示。
LSTM内部采用了3种门控机制删除和增加神经元的信息,其分别为:遗忘门f,输入门i和输出门o (t表示该LSTM单元在t时刻)。
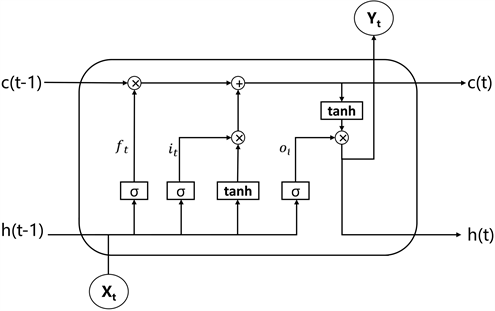
Figure 3. Schematic diagram of LSTM internal module
图3. LSTM内部模块示意图
遗忘门是用来控制当前神经元需要剔除哪些信息,遗忘门的具体计算过程如式(3):
(3)
输入门则是用来控制当前神经元接受的信息有多少可以保留到当前的单元状态中,输入门的状态更新计算过程如下式:
(4)
(5)
(6)
输出门控制的是当前神经元能够输出多少信息到下一个时刻,输出门的状态更新计算过程如下式:
(7)
(8)
上述式子中,
表示的是神经网络的激活函数Sigmoid函数,会根据输入将变量映射成[0, 1]之间的向量;
表示的是候选神经元中的信息;
,
,
,
表示的是LSTM神经元状态更新计算过程中权重;
,
,
,
表示的是LSTM神经元状态更新计算过程中偏置。
LSTM用以捕捉时间信息,就是相比普通的RNN,LSTM在面向含有未知长度的时间序列的学习中十分有效,其具有维持长时记忆的能力。因此本文选用LSTM作为子模块。
2.3. GCN-LSTM序列重构方法
各级服务器之间不仅有网络层级拓扑结构的交互信息,每个服务器自身的运行状态性能指标也会随着时间的变化而产生变化。因此,整个云计算服务器架构需要抽象成图模型,各个子服务器被抽象成为图的节点,各服务器内部的状态性能指标数据抽象为每个节点的特征向量,各个服务器之间的连接关系抽象为图的边。与此相同,图模型中节点的运行状态除了自身状态以外还受其他节点状态的影响,该图模型的建立为描述云计算服务器的空间特征和属性提供了分析工具。
云计算服务器内部在时域上都经历着使用率、吞吐率、读取速度、写入速度等要素属性的变化,而这些要素又受到地理环境、气候环境、人类生活、生产规律的影响而体现出来一定的规律性和周期性。因此,通过对过去的云服务器性能指标历史数据进行分析和计算可以对未来云服务器的运行状态进行评估。云服务器的客观运行规律也为时序算法提供了有力的理论支撑。
基于以上分析,本节提出了一种融合了空间信息和时间信息的时间序列重构模型:GCN-LSTM模型。GCN-LSTM模型由图卷积神经网络和长短期记忆神经网络两部分组成,其内部模块连接示意图如图4所示。一方面,图卷积神经网络对建立的图数据模型提取其内部的信息,解析其拓扑结构,并提取其空间特征。另一方面,将图卷积神经网络对不同时刻的所提取的特征依时间序列的方式输入到长短期记忆神经网络当中学习时间特征。
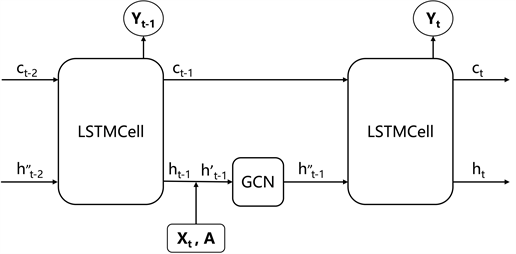
Figure 4. Schematic diagram of GCN-LSTM internal module connection
图4. GCN-LSTM内部模块连接示意图
GCN-LSTM模型面向云计算服务器中的性能指标数据的操作流程可以简单描述为:通过云服务器历史指标数据时长为s的数据
和图模型的邻接矩阵A,来推测下一个时刻t的性能指标,设
表示 时刻云服务器指标数据,F为GCN-LSTM模型处理方法,即可得式(9):
(9)
将云服务器的历史性能指标序列
输入到GCN-LSTM模型中,生成重构序列
,误差序列
,其中
。将集合E按照时间顺序分
为和
两部分,并分别作为COPOD方法的训练集以及测试集。
2.4. COPOD异常检测方法
异常检测的目的是对不符合预期模式或大多数数据的分布的项目、数据、事件或观测值的识别。从最容易理解的角度出发就是看该数值距离平均值有多远,给定一组一维数据满足高斯分布,若某数据离均值2个或者3个标准差以外的数值就可以简单地被认为是异常。然而在现实世界中,该方法并不是常常有效的,例如大多数数据并不是一维的,而是有多个维度的。同时这多个维度的数据并非是相互独立的,也就意味着联合分布的建模会变得十分困难,更意味着无法简单地使用3sigma准则(又称为拉依达准则)来判定异常,否则会忽略了多个维度数据之间的关联性,使得模型过于盲目和随意。
为了解决该问题,Li等人提出了的基于Copula的异常检测方法 [8] (Copula-Based Outlier Detection, COPOD)来估算各数据维度之间联合分布的尾端概率。其中Copula函数理论由Sklar [20] 在1996年率先提出,可以将一个多元联合分布分解为数个边缘分布以及Copula函数,而该函数可以确定变量间的相关性。即设F为一个N维联合分布函数,其边缘分布为
,则存在一个Copula函数使得式(10)成立。
(10)
若
连续,则存在唯一的Copula函数。经过多年发展,Copula理论已成为了解决高维随机变量联合概率分布问题的有效手段,由于Copula函数可以对各边缘分布进行一定程度上的相关性的总结,COPOD可以对异常是哪些维度造成的提供一些可解释性,例如运维人员可以直接找到造成异常最多的维度,进行深入分析。
COPOD是一种基于Copula的异常检测方法,给定d维数据集
,其中i表示当前的时间快照,算法分三步进行操作:
1) 面向每一个维度,按照如式(11)以及式(12)使用非参数方法估计左尾部以及右尾部经验累积联合分布(left/right tail Empirical CDF)。
(11)
(12)
此时,异常可能出现在分布的左边,也可能出现在分布的右边。不同情况下,使用不同方向的ECDF会得到不一样的结果,此时还需要计算偏度系数(Skewness coefficient)。偏度系数是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称(左右不一致)程度的数字特征。当分布左右对称时,偏度系数为0;当偏度系数大于0时,该分布为右偏,异常点更倾向于落在分布的右侧;当偏度系数小于0时,该分布左偏,异常点更倾向于落在分布的左侧。偏度系数的计算方式如式(13)。
(13)
2) 计算每一个时间快照
的empirical copula观测值,计算过程如式(14)和式(15)所示。于是,可分别得到
以及
,此时根据
的值确定偏度系数的empirical copula观测值
,若
,则
反之
。
(14)
(15)
3) 计算
的左侧、右侧以及偏度的尾部概率,计算过程如下式:
(16)
(17)
(18)
当尾部概率越小,它的负对数就越大,所以如果一个点的尾部概率小,会更容易被认定为异常值,因此该时间快照下输出异常分数如式(19):
(19)
阈值可以按照不同领域不同行业自行设置,针对本文方法并按照经验总结,如式(20)所示,异常的阈值
由数据集总体异常率
的分位数决定,percentile函数表示计算分析各时间节点按由大到小排序后异常分数的百分比数值点。当
时,当前时间快照为异常,反之为正常,并将结果输出。
(20)
3. 实验评估与分析
3.1. 实验数据集
本实验采用MBD数据集,该数据集来自运行大数据批处理系统的环境,其中一个包含1个主节点和4个从节点。监控并收集的数据包括每个节点的26个指标,包括CPU空闲、CPUI/O等待、CPU软件、CPU系统、CPU系统、CPU用户、每秒等待、磁盘I/O进程、磁盘使用百分比、磁盘读取速度、磁盘写入速度、内核熵、负载等,其图模型如图5所示。R740-3-1、R740-3-2、R740-3-3、R740-3-4以及R740-3-5表示位于不同地点的云服务器;服务器之间的连线表示其间的交互情况;服务器保存着的过去运行情况的数据指标,上述三点分别可用于构建图模型的节点、边以及属性,以实现图模型内空间特征的提取。
云服务器的指标数据总共收集了3天,数据集共有8640条数据(观测值),数据观测时间从2020.3.25 0:00:00开始到2020.3.27 23:59:30,以30秒为一个观测单元记录1条数据。该数据集被不规则地注入随机参数来模拟应用程序故障,标签值label代表异常标记,1表示异常数据,0表示正常数据。

Figure 5. Schematic diagram of MBD data set topology
图5. MBD数据集拓扑结构示意图
3.2. 实验评估
本实验使用基于python3环境的Pytorch开源深度学习框架实现图卷积神经网络和长短期记忆网络进行设计,本文实验采用PC机,Microsoft Windows 10操作系统,16GB内存,处理器为AMD Ryzen 5 4600U with Radeon Graphics 2.10 GHz。本文将前两天的数据作为模型的训练集,将第三天的数据作为模型的测试集。
在检测算法中,模型的评估方法使用混淆矩阵及其衍生的各项性能指标,如表1:
本文中将使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、AUC值作为异常检测评估指标,其计算公式如以下各式:
(21)
(20)
(21)
ROC曲线(Receiver operating characteristic curve),即受试者工作特征曲线,主要用来评价对二分类算法的效果,以及寻找最佳的指标临界值使得分类效果最好。该曲线由真阳性率(TPR, True positive rate)为横坐标,假阳性概率(FPR, False positive rate)为纵坐标共同绘制而成,曲线越往左上角则效果越好。
AUC值(Area Under ROC Cure)被定义为ROC曲线下与坐标轴围成的面积,取值范围一般在0.5和1之间,这是因为ROC曲线一般在y = x上方,其评价标准为:当AUC值越接近1.0,该异常检测方法真实性越高。
3.3. 实验结果与分析
实验中采用了多种在异常检测领域有所建树的方法作为对比实验,包括基于距离的KNN方法,基于密度的LOF [21]、COF [22] 方法,基于树的iForest方法,基于概率的ECOD方法以及基于深度学习的AutoEncoder方法。同时,我们还对基模型LSTM的方法进行了实验对照,以便于对模型效果更好的评估。以下为各基准方法的介绍:
1) KNN (K-Nearest Neighbor):基于距离的方法,对数据集分布、标签以及类型要求不高,K取值为5;
2) LOF (Local outlier factor):基于密度的方法,若某点密度越低越可能被认定是异常点;
3) COF (Connectivity based Outlier Factor):基于局部密度的方法,通过最短路径求出局部密度;
4) iForest (Isolation Forest):采用构造多个决策树的方式进行异常检测,通过树的高度确定异常值;
5) ECOD (Empirical-Cumulative-distribution-based Outlier Detection):通过计算经验累积分布确定落在尾部的异常值;
6) AutoEncoder:利用编码器和解码器的之间的序列重构误差确定异常,该方法异常点服从不同的分布,从而无法将异常数据较好还原。
实验采用3.1的数据集进行,分别对各类基准方法进行对比,评估方式如(3.2)各式,结果如下方图6、图7、图8,表2所示:
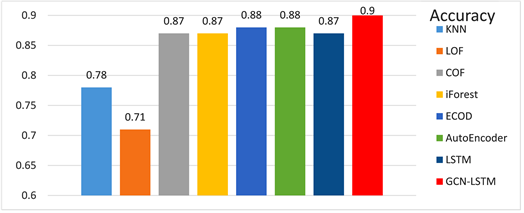
Figure 6. Experimental results of Accuracy
图6. 准确率(Accuracy)实验结果
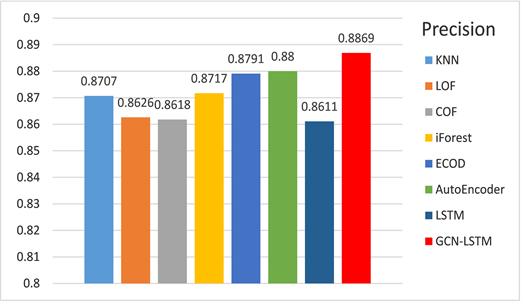
Figure 7. Experimental results of Precision
图7. 精确率(Precision)实验结果
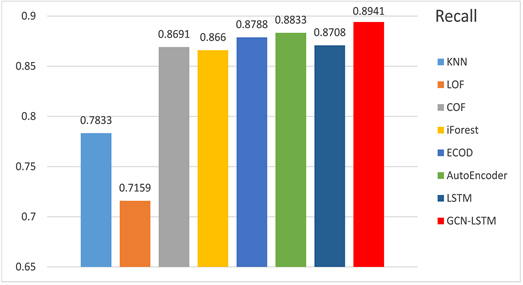
Figure 8. Experimental results of Recall
图8. 召回率(Recall)实验结果
从实验结果可以得出,本文提出的GCN-LSTM-COPOD异常检测方法在MBD数据集上,准确率(Accuracy)、精确率(Precision)、召回率(Recall)、AUC值等都优于上述方法。除了准确率、精确率和召回率都有一定程度的提高以外,相比较起其他方法,本文提出的方法可以获得更好AUC值,相比起其他方法提高了大约27%~40%,意味着本方法在面向异常的有效程度和检测价值得到了提高。如图9所示,ROC曲线可以很好地展现出各类方法对异常的检测能力,展示本文提出的于图卷积神经网络的云服务时序异常检测算法优于其他类型方法,试验准确性高。另外,相比起基模型LSTM,GCN-LSTM在获取空间信息上有着更好的适用性,使得模型在训练时可以学习到更加充足信息,在序列重构时,可以将空间信息和时间信息有效重现,此时的构建误差可以获得更好的效果。
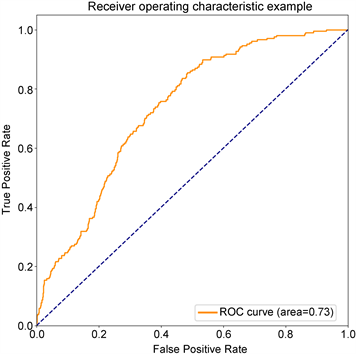 (a) GCN-LSTM
(a) GCN-LSTM  (b) LSTM
(b) LSTM 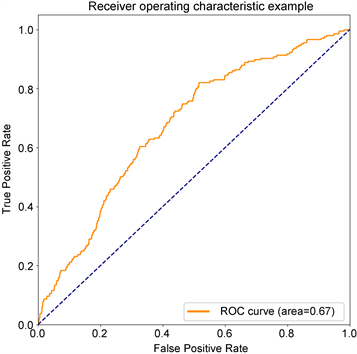 (c) ECOD
(c) ECOD 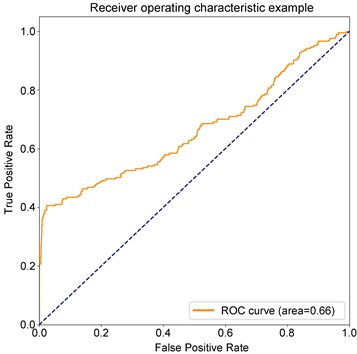 (d) AutoEncoder
(d) AutoEncoder
Figure 9. ROC curves of each method (excerpt ranking the top four)
图9. 各方法ROC曲线(节选排名前四)
在可解释性方面,本文使用的异常检测方法可以将一个多元联合分布分解为数个边缘分布以及Copula函数,此时可以针对不同的边缘分布进行分析,查看其哪个分布的异常得分对异常结果有最大的贡献,从而让该方法可解释。如图10所示,这是MBD数据集中处于异常状态时最后20个维度的异常得分示意图,其中数字14的维度拥有远超其他维度的异常得分,该维度表示的数据为建立TCP连接的等待时间,因此,意味着此时的异常极有可能是TCP建立时引发的。
4. 结论
本文提出了一种基于GCN-LSTM的云计算服务异常检测算法,面向带有时空特征数据的云服务器异常检测问题,首先采用图卷积神经网络提取云服务器之间的空间特征,然后用不同时刻提取到的时间信

Figure 10. Schematic diagram of dimension anomaly score
图10. 维度异常得分示意图
息输入到长短期记忆网络中对云服务器性能指标进行重构,利用COPOD对重构误差进行异常检测。实验结果表明本文提出的异常检测算法要比其他类型异常检测算法更优异,同时减少了阈值的选择和计算,并为造成异常的原因带来了可解释性。未来,将对该模型进一步优化,研究更优秀的数据异常检测的处理方法,提高模型的各项效果以及指标。