1. 引言
在金融市场中,我们一般假设扩大100倍的对数收益率服从正态分布,但越来越多的实证分析表明资产收益率数据并不满足对称分布,大多存在明显的尖峰厚尾特征和非对称性。厚尾性表示数据集的尾部比正态分布厚。该现象受到国内外学者持续关注,为了更好地拟合尖峰厚尾特征的资产收益率数据,有学者选用学生t分布、广义误差分布等来拟合,它们的拟合效果与正态分布相比尾部更厚,但这并未有效的解决数据尖峰厚尾性和非对称性。所以,不管从理论上还是实际中,我们对概率分布的研究并提出新的分布函数显得非常重要。
实际金融资产收益率数据存在明显的尖峰厚尾特征,该现象受到国内外学者持续关注。现存文献中,针对资产收益率数据分布的估计主要有:参数法(Bollerslev [1])、非参数法(Silverman [2])和半非参数法(Sargan [3], Mauleón和Perote [4])。参数法要求数据的分布函数形式已知,如假设研究的数据服从正态分布,再根据已知的数据估计正态分布中的参数,这种假设有时并不成立,会存在较大的偏差;非参数法是不考虑总体分布,此时可以避免对总体分布假设不当而导致的偏差,但对于大样本,计算会变得十分复杂;而半非参数法不需要知道数据概率分布的具体形式,在拟合分布时存在一定的优势。因此,利用半非参数法拟合分布是存在意义的。
若序列
独立同分布于
,满足
,四阶矩
,令
,则
的二阶Edgeworth [5] 展开式为
(1)
其中,
为均值,
为标准差,
,
,
,
,
,
为Hermit多项式,
,
,
,
和
分别为标准正态分布的分布函数和概率密度函数。Edgeworth展开式将总体的偏度和峰度参数融入其中,能较好地刻画数据尖峰厚尾特征。Ñíguez [6] 提出了正的Edgeworth-Sargan分布(PES),León [7] 研究了变换Gram Charlier分布(TGC)及应用。
Bollerslev [8] 首次提出GARCH模型用于刻画金融数据波动率的聚集特征,此后,针对该模型的拓展和应用形成了丰富的GARCH簇模型,如Nelson [9] 和Ding [10] 分别提出EGARCH与APARCH模型,用于克服金融资产收益率正负的非对称效应;魏正元 [11] 将EGARCH模型与广义Pareto分布的极值理论结合,构建EGARCH-PED模型测算了收益率的VaR值,该方法在一定程度上提高了VaR估计的预测精度;鲁皓 [12] 提出用GARCH-GED模型来度量证券投资风险;宫晓莉 [13] 用GJR-GARCH-GED模型拟合资产收益率的边际分布,构建GARCH-copula模型,分析了两个模型对金融序列的拟合效果,度量了投资组合风险值。
受文献 [5] 和 [6] 的启发,本文基于Edgeworth展开的思想,新提出了一类正Edgeworth截断分布,计算出了新分布密度函数、分布函数和k阶矩的函数表达式,并计算出参数的最大似然估计量。新分布包含了数据的峰度与偏度两个参数,在拟合尾部较厚的数据上比正态分布更合适。将PET分布刻画到模型的残差序列,建立了APARCH-PET模型用于估计收益率序列的VaR值。选取上证主板招商银行股票收盘价格数据,对比分析了APARCH-norm,APARCH-PES,APARCH-PET三种模型拟合效果,计算出了相应的VaR,并对VaR做了返回测试。结果表明,采用正态分布拟合残差序列的模型低估了风险值,而采用PET分布拟合残差序列的模型度量的VaR更准确。一定程度上提高VaR的准确度,可以防止投资者过度投资,从而避免一些金融交易中的重大亏损。
2. PET分布
定义1. 若随机变量X的密度函数为
(2)
其中,
,则称X服从正Edgeworth截断分布,简称PET。
 (a) PET概率密度函数图(d1 = 0, d2 = 0.04, 0.06, 0.10, 0.20)
(a) PET概率密度函数图(d1 = 0, d2 = 0.04, 0.06, 0.10, 0.20) 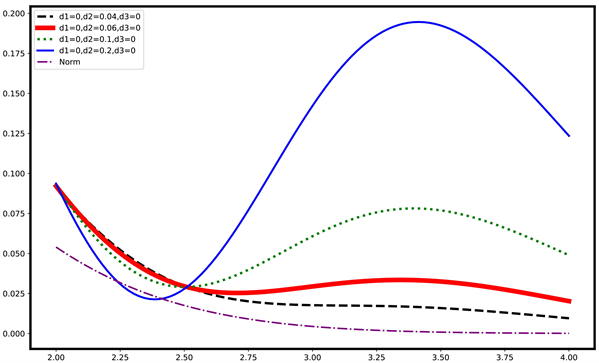 (b) PET概率密度函数图(d1 = 0, d2 = 0.04, 0.06, 0.10, 0.20)
(b) PET概率密度函数图(d1 = 0, d2 = 0.04, 0.06, 0.10, 0.20) 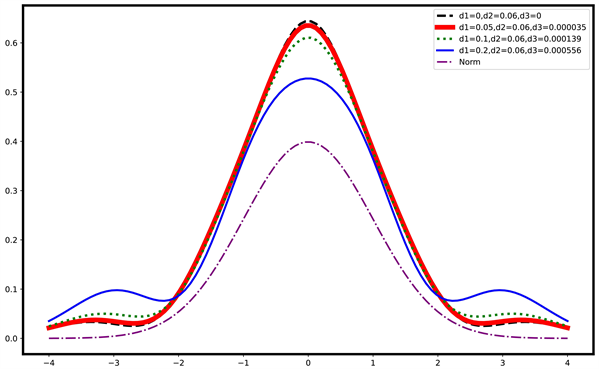 (c) PET概率密度函数图(d2 = 0.06, d1 = 0, 0.05, 0.10, 0.20)
(c) PET概率密度函数图(d2 = 0.06, d1 = 0, 0.05, 0.10, 0.20) (d) PET右尾概率密度函数图(d2 = 0.06, d1 = 0, 0.05, 0.10, 0.20)
(d) PET右尾概率密度函数图(d2 = 0.06, d1 = 0, 0.05, 0.10, 0.20)
Figure 1. Diagram of the PET density function with different parameters
图1. 不同参数下的PET密度函数图
注. 图1给出不同参数下的PET概率密度函数图。图1(a)与图1(b)表示参数
,
(虚线),0.06 (粗实线),0.10 (点线),0.20 (细实线)的PET概率密度函数图与右尾概率密度图。可以看出,固定参数
,PET函数图像随着
增大,尾部将增厚,且由单峰变为多峰。
图1(c)与图1(d)表示参数
,
(虚线),0.05 (粗实线),0.10 (点线),0.20 (细实线)的PET概率密度图和右尾概率密度图。可以看出,固定参数
,PET函数图像会随着
的增大,尾部增厚,峰度递减。不同参数下,与标准正态分布(点横线)相比,PET分布的尾部更厚。当
趋于0时,PET分布将退化为
时的PES分布。
注2. 不难验证(2)式右边积分为1
命题1. PET的分布函数如下,证明见附录
命题2. 假设随机变量X服从PET,k阶矩为(证明见附录)
当k为奇数时,
当k为偶数时,
其中,
,
是常数,
表示标准正态分布的k阶矩。
命题3. 设
是来自PET的简单样本,其样本观测值为
,则参数
,
和
的对数似然函数为
对数似然方程组
上式对数似然方程无解析解,借助R软件的DEoptim函数可以给出
,
,
的最大似然估计值数值解。
3. APARCH-PET模型
本文提出APARCH-PET模型,具体表达式如下
(3)
其中,
,
分别为
的条件均值和条件标准差,
。
服从均值为0,方差为1的PET分布。
由于PET分布包含偏度与峰度两个参数,APARCH模型能捕捉到收益率序列的非对称性,上式模型假定
服从PET分布,提出的APARCH-PET模型兼具PET分布和APARCH模型的优良特性。一定程度上,本文提出的新模型具有灵活性和双重性。
由(3)及VaR平移不变性和正齐次性得
(4)
其中,
为PET的
分位数。
4. 模型应用
4.1. 拟合结果
本文选取上证主板招商银行股票日收盘价
作为样本(数据来源:http://www.resset.cn/锐思金融数据库,时间区间为2007.01.04~2022.10.20),共3810个数据。放大100倍的日对数收益率
。

Table 1. Summary statistics of China Merchants Bank’s stock yield series
表1. 招商银行股票收益率序列概要统计量
注:ADF为ADF检验统计量。
从表1可以看出,偏度值为−0.1276,该序列存在左偏特征;峰度值为8.0419大于3,该序列比正态分布陡峭。同时,J-B统计检验在5%的显著性水平下,拒绝服从标准正态分布的原假设,数据存在尖峰厚尾特征。ADF的检验结果表明
是平稳的序列。
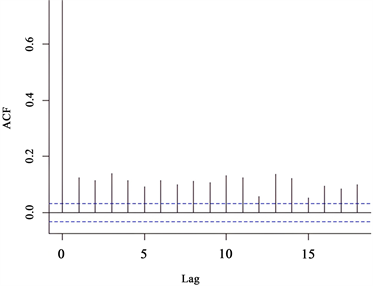
图2中招商银行日对数收益率的样本ACF均在两倍标准差之内,而平方后的样本ACF均超出两倍标准差,表明
存在显著的ARCH效应,而APARCH模型恰能刻画此效应,所以用三种模型APARCH-PET,APARCH-PES,APARCH-norm来拟合
。模型参数结果如表2。
 (a)
(b)
(a)
(b)
Figure 2.
with
ACF diagram
图2.
与
的ACF图
Table 2. APARCH model estimation results
表2. APARCH模型估计结果
根据表2可知,APARCH-PET模型的AIC与BIC均小于经典模型,这表明对于存在非称现象和具有尖峰厚尾特征的序列,用APARCH-PET模型拟合能达到更好的效果。
4.2. 返回测试
本文选取Kupiec [14] 失败率检验法评价APARCH-PET模型估算
值的优劣。定义示性函数
(5)
令
表示收益率超过VaR值的总天数,T为序列总观测天数,
表示失败频率,考虑原假设
。则
在原假设条件下,似然比统计量渐近服从
分布,若
,则认为模型无效,反之有效。计算2021.07.25~2022.10.20共300天数据的
,并对其结果进行失败率返回测试。
Table 3. VaR 1 − α Returns test results
表3.
返回测试结果
表3给出残差序列分别采用PET和正态分布估算出的
返回测试结果。当
时,两种方法得到的p值均大于0.05通过检验,但当
时,正态分布拟合的残差序列估算出的值未通过检验。表3可知采用正态分布拟合残差序列的模型往往低估了金融风险,而采用PET分布拟合残差序列的模型在度量金融风险上更准确。
5. 结论
本文提出的PET分布包含了数据的峰度与偏度,在拟合尾部较厚的数据上比正态分布更合适,能更有效的拟合资产收益率数据“尖峰厚尾”特征。在APARCH模型的基础上,结合PET分布构建APARCH-PET模型,并选取上证主板招商银行股票数据进行实证分析。结果显示,用PET分布拟合残差序列的模型对VaR度量效果明显优于经典模型,新模型提高了估计VaR的精准度。对于存在非对称效应和尖峰厚尾特征的资产收益率数据,在度量金融风险时可以考虑利用APARCH-PET模型估算VaR值的方法,投资者可以进行更好的资金控制和风险管理。
基金项目
重庆市自然科学基金项目(cstc2020jcyj-msxmX0232),重庆市高等教育教学改革研究项目(203332),重庆市研究生科研创新项目(CYS21475)。
附录
证明命题1
根据Hermit多项式的性质可以计算出
其中
证明命题2
当k为偶数时,
NOTES
*通讯作者。