1. 引言
近年来,西南地区海相页岩气勘探取得重大突破,发现了涪陵、长宁、威远、昭通威荣等页岩气田,探明储量超过10000 × 108 m3 [1] [2] [3] [4] ,证实了四川盆地五峰组–龙马溪组是最有利的海相页岩气勘探层系 [5] [6] [7] [8] 。另外,五峰组–龙马溪组页岩分布面积相对广泛,在川南、渝西地区、鄂西及贵州北部、云南昭通等都有发现,油气勘探潜力巨大 [9] [10] [11] [12] 。随着海相页岩气的勘探深入及压裂工艺的成熟,现阶段的勘探目标逐渐转向中深层,并取得相关的勘探突破及进展,如涪陵地区的普顺1井,五峰组–龙马溪组页岩层在垂深接近6000 m的深度仍然具有较好的含气性。通观四川盆地,其中深层页岩气勘探大有潜力可挖,如石龙峡、南温泉、黄瓜山、铁厂沟、石油沟、官渡等地区的高陡背斜下的埋深为中深层的页岩层将是今后海相页岩气勘探的重点,有望取得更多的油气勘探突破。继2014年发现涪陵焦石坝气田之后,在四川盆地东南缘的丁山勘探区内获得重要发现。其中,dy2HF、dy4HF、dy5HF井测试分别获10.50 × 104 m3/d、20.56 × 104 m3/d、16.33 × 104 m3/d的页岩气流 [13] [14] [15] [16] ,证实了丁山构造中深层五峰组–龙马溪组为页岩气高产富集带。但该地区的页岩气产量总体上比焦石坝地区略低,不同位置的水平井之间产能差异比较明显,如dy1HF井的测试产量仅为3.4 × 104 m3/d。相关勘探实践证明,LM地区不同埋深带的页岩气产能与裂缝、含气性及压力系数等因素紧密相关 [17] 。因此,有必要研究适合该勘探区的页岩气储层预测及评价技术,总结出该区优质页岩储层的分布特点,以利于后续的页岩气勘探开发及经验推广。
优质页岩储层主控因素包括:页岩储层含气量、机碳含量TOC、孔隙度、脆性条件、裂缝发育强度等 [18] [19] [20] [21] 。因此本文在叠前叠后 [22] [23] 高精度反演的基础上对页岩气成藏关键参数进行表征,然后引入机器学习方法预测甜点,最终结合断层发育情况开展优质页岩储层的综合评价。同时,本文提出一种智能多属性融合评价技术(Intelligent multi-attribute fusion evaluation technology),将储层类型与页岩岩石物理参数相结合,完成研究区地质“甜点”精细化预测,克服了单一指标进行预测的多解性,并且本文将预测结果与实际测井解释的分类结果进行对比,匹配度较高,证明了该方法的准确性和有效性。
2. 方法原理
2.1. 机器学习与优化算法
为了更好的利用测井资料中的实测“甜点”参数及基于地震数据预测的空间分布信息,本文利用PSO算法优化SVM模型,并采用PSO-SVM模型进行联合地质“甜点”精细化预测。针对“甜点”预测,本文选择智能群优化算法优化机器学习模型超参数,即PSO和SVM,最大限度地利用机器学习模型出色的非线性拟合能力。尽管现代机器学习算法为地震数据与岩石物理性质的反演创造了新的和改进的解决方案,但通常是采用人工试错法确定机器模型的超参数,模型的最大拟合能力并没有有效地发挥,本文试图通过PSO优化SVM模型来找到一个最优分类器以达到提高预测精度目的。
2.1.1. 支持向量机(SVM)
SVM是一种通过超平面分离的判别分类器 [24] 。超平面用于在不同类别的点之间尽可能宽地划分边界,根据距离边界最近的训练样本子集对其进行评估,称为支持向量,如图1所示。
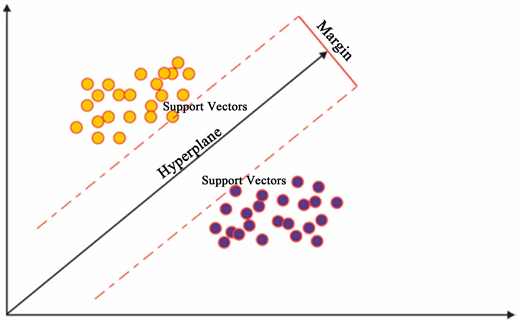
Figure 1. Example of SVM with separated hyperplane
图1. 分离超平面的SVM示例
利用收集的测井数据样本
以及甜点分类结果
作为训练样本,使用以下线性函数表示SVM映射关系:
(1)
其中,
对应于向量
和x的点积,如果精度
内的所有训练点都由回归函数
估计,那么最小化问题可以通过以下方程转化为优化问题:
(2)
在某些情况下,上述函数不会处理超出精度范围的数据,可以通过引入松弛变量
和
来纠正估计函数来解决。至此,优化问题可以转化为以下内容:
(3)
上式中,训练样本的分布与边界决策函数的优化是为了处理参数X,对于较大的X值,允许使用硬间隔(hard-margin)回归函数,而较小的X值以较低的代价偏离精度
。此外,核函数也称为广义点积,用于计算非线性区域高维特征空间中“x”和“y”向量的点积或标量积,如图2。支持向量机常用的核函数有:线性核、多项式核、高斯核、sigmoid核。高斯核是最常用的核,见式7~14,适用于不同甜点属性之间的非线性关系,因此本文选择高斯核。
(4)
其中,
是用于定义单个训练集的核尺度,如果
较大,距离越近的必然受到其他样本的影响。在这种情况下,为了在多类分类问题中取得更好的结果,将执行一对一分类。
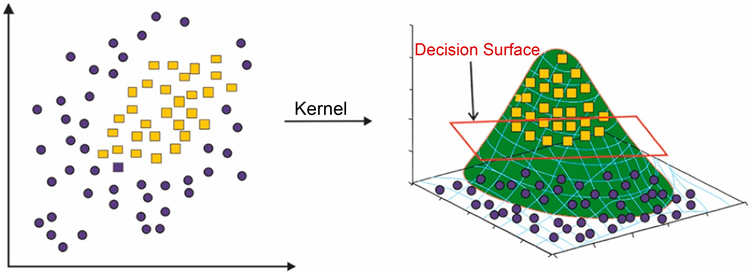
Figure 2. Schematic diagram of the nuclear function
图2. 核函数的示意图
SVM的有效性在很大程度上取决于核函数类型和相关参数,如系数X和不敏感参数
。核函数及其参数表明,训练数据的分布和范围对预测模型有显著影响,没有理论模型来确定SVM模型的正确参数设置,针对此问题,本文引入PSO优化算法用于确定SVM模型的超参数。
2.1.2. 竞争神经网络(MOP)
自组织竞争神经网络是一种无监督的学习方法。与其他的神经网络不同的是,其他神经网络通常更新网络是更新全部的神经元,并没有考虑到人体神经元的侧抑制现象,也就是在很多情况下,某一个神经元刺激仅能激活很少一部分神经元而不是所有神经元,这就体现了一种竞争的思想。竞争神经网络每次只更新一个被激活的权值并且没有标签,这更像是一种聚类方法。常用的竞争神经网络有主成分分析、协同神经网络、自组织特征映射网络等等。竞争神经网格结构通常包括神经元、极限值以及训练机制。其中,神经元由自定义权重相连,响应根据样本集的变化而变化;极限值,则用来规定神经元训练时的强度;机制,为竞争神经网络核心,即定义神经元竞争输入子集响应,通过机制定义,只有最后竞争赢的一个神经元激活。总体来讲,该网络结构简单,可以根据需求自定义,可定义成只有一个输入层和一个输出层的结构,输入输出通过前向连接,而输出层如下图所示为侧向连接,使用该连接方式实现竞争输出。从网络算法上来看,各神经元一直在学习,但极限值导致能量受限,因此权重慢慢逼近输入,神经元经过竞争产生输入子集响应,最终输出竞争胜利神经元即获胜神经元。因此本文用于属性融合的竞争网络结构如图3,由一个输入层、一个竞争层和一个输出层组成。输入网络数据为体曲率属性体、蚂蚁追踪属性体以及水平应力差异比数据体。
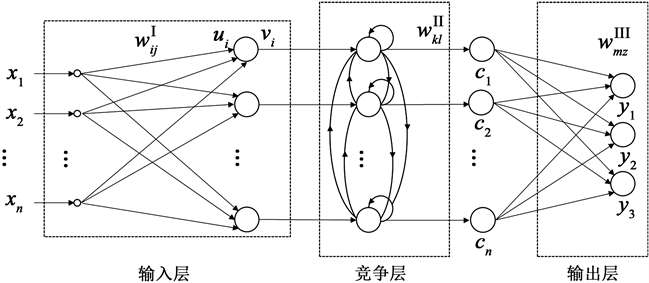
Figure 3. Competition network structure in this paper
图3. 本文竞争网络结构
单一地震属性往往仅能反映部分信息,融合多种敏感属性对于减少构造解释的多解性具有重要作用。常规属性融合大多数是基于简单的线性像素叠置,融合结果虽然提升了较大尺度裂缝的概率,但是不同属性之间可能会相互干扰,导致部分细节信息的缺失,影响裂缝的识别精度。基于此,我们选用无监督学习的竞争学习神经网络用于多属性聚类融合,通过竞争学习,激励不同属性之间的学习权重系数动态更新,提高属性融合的精度和分辨率。
由于不同的属性之间会存在着幅值和物理意义的差异,因此首先要对优选出的敏感属性做值域为[0, 1]的标准化处理:
(5)
利用主成分分析(PCA)输出标准化后的m种敏感属性的特征值,为属性融合剔除冗杂信息并提供主成分贡献率,其中特征方程可以表示为:
(6)
式中R是输入数据的协方差矩阵,通过上式求解出特征值,并根据特征值计算累计主成分贡献率:
(7)
将主成分分析输出的主成分分量看作是一个集合
,假定输出的聚类结果C具有n分类,那么对于每一类输出结果Ci都存在一个权值矩阵Wi和一个偏置项bi,并按照Kohonen学习规则进行迭代更新:
(8)
其中,
是随时间衰减的学习率函数,进一步可以建立一个输入与输出之间的映射关系式:
(9)
聚类结果往往没有明确的地质含义且边界刻画不准确,难以实现复杂储层构造细节的精细识别。为此,引入Sigmoid激活函数,将聚类结果变量映射至[0, 1]之间,则聚类结果可以转换为地质意义明确的裂缝发育概率体,上式优化为:
(10)
2.1.3. 粒子群优化算法(PSO)
PSO是一种智能群体优化算法,粒子群算法的主要流程是在有限迭代次数内搜索和更新每个粒子,并同时更新全局最优解。在本文的优化流程中,粒子群的位置包涵了支持向量机的3个超参数,并将最后的储层综合评价的准确率作为目标函数。假设粒子群体包含M个D维粒子。
在迭代次数t时刻,粒子群体的位置可表示为:
(11)
其中,
和
表示搜索空间的上下边界,
,
。
在迭代次数t时刻,粒子群体的速度可表示为:
(12)
其中,
和
分别表示粒子个体速度的上限和下限。其中,
和
。
个体最优和全局最优位置可分别定义为
(13)
(14)
其中,
表示t + 1迭代次数下的第i个粒子在第d维度的位置,可通过下式计算:
(15)
(16)
在上述公式中,
和
为学习因子,
和
表示范围(0, l)内的随机数,
为惯性权重,平衡了全局和局部搜索的权重,本文采用线性下降法(linear decreasing inertia weight, LDIW)确定。
SVM和PSO之间的关系如图4所示。结果表明,对于SVM算法,首先可以使用输入学习值x (储层参数)来估计输出y,用SVM预测数据y和实际数据集y*的差值e作为目标函数,PSO算法通过迭代确定SVM的超参数,最大限度地提高SVM模型的拟合性能。
2.2. 页岩脆性指数计算
脆性指数对于页岩气的研究十分重要,它表征岩石受到外力时是否容易发生破裂。对于脆性矿物含量较多的页岩地层来说,脆性指数越高,表示地层越容易破裂,导致产生天然裂缝的概率增加,也更适合进行水力压裂,因此,脆性指数的准确预测可以有效指导实际生产。
利用地震数据进行脆性指数预测时,通常采用AVO近似方程反演出弹性参数后,代入Rickman公式间接计算脆性指数的方法。根据实际工区测试结果进行经验总结,利用岩石弹性模量中的泊松比及杨氏模量进行运算最终预测脆性指数,简称“泊–杨”算法,公式为:
(17)
(18)
(19)
式中,BI代表脆性指数,E代表杨氏模量,
为泊松比;
、
代表杨氏模量最小和最大值,
、
即为泊松比最小最大值,它们可以从测井资料获得。通常,E的数值非常大,数量级约为1 × 1010,而
数值较小,分布在0到1之间,在使用它们进行计算时,首先要归一化,
、
即表示归一化后的杨氏模量和泊松比。
通常利用反演波阻抗进行脆性指数推算,那么阻抗形式的杨氏模量、泊松比表达式为:
(20)
(21)
式中,为横波阻抗,为纵波阻抗,其中代表密度,进一步推导出脆性指数为:
(22)
3. 基于神经网络的储层参数预测
同时裂缝发育情况也是页岩优质储层重要评价标准,裂缝预测一直是油气勘探研究热点之一,单一方法预测通常会导致多解性,因此在方法优选的基础上如如何准确开展多尺度裂缝预测也是本节研究重点。本节将叠后多属性分析和地层应变属性结合进行多尺度裂缝精细表征研究。
3.1. 页岩有机碳含量(TOC)预测
针对页岩储层,有机碳含量(TOC)是评价其富含页岩气程度的重要评价指标,指导实际生产储层产量是否达到开发价值。利用地震数据进行储层预测的方法通常是建立在波动理论基础上的数学运算,但直接借助数学手段进行页岩储层参数预测很难实现。因此,本文在实际测井资料的基础上,结合第二章储层相应特征进行页岩TOC预测,首先分析TOC与其它岩石物理参数相关性,根据分析结果将TOC与其它参数的实测值(一个或多个)进行多元回归,然后利用第六章高精度叠前参数反演结果完成TOC的间接计算。该预测过程就是目前最常用的TOC预测方法,回归拟合法。
在该理论指导下,本文首先提取研究区W3、W4井测井曲线目的层段内的值,通常提取出的值不能直接用于分析,要先进行预处理,即进行背景值和有效值分析,剔除异常值,进行归一化等操作。然后将处理好的TOC数据与其它岩石物理参数进行拟合。如图5所示,红色散点为实际测井曲线在目的层段约束下的数值,黑色线为拟合线,拟合结果显示,实际工区TOC值与纵波阻抗、横波阻抗、密度及纵横波速度比等参数均存在线性关系,其中相关性最高的参数为密度,其数值达到0.7136,其它参数相关性较差难以建立多元线性表达式,因此得到密度与TOC的线性关系为:
(23)
式中,
代表密度值。
计算得到线性回归方程后,将高精度叠前反演得到的密度体代入,即可获得整个工区TOC三维预测结果,如图6所示,图6(a)、图6(b)分别为过W1井和W2井预测剖面,图中可以看出,预测结果与测井曲线高低值趋势一致性较高,证明了该方法的准确性及可靠性。
为了进一步结果的准确性,本文沿目的层段提取了TOC预测结果,如图7所示,并且将各井中的实测TOC值与预测结果进行对比分析,见表1,其中前四口井为反演井,后面两口(蓝色标注)为验证井,可以看到误差值较小,预测值跟井上值吻合度较高,说明该方法预测结果可靠。
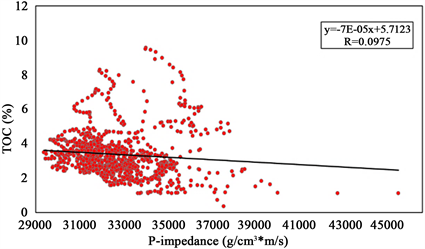

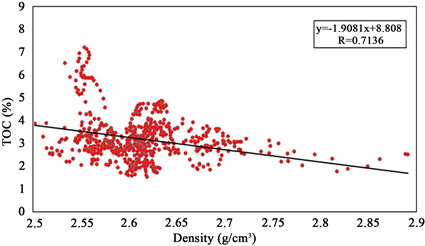
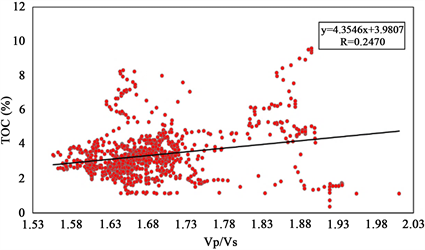
Figure 5. Analysis of TOC sensitive parameters
图5. TOC敏感参数分析图
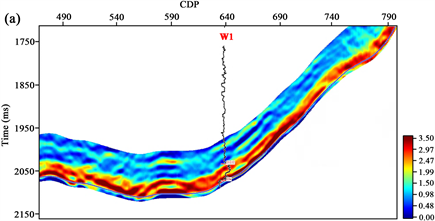
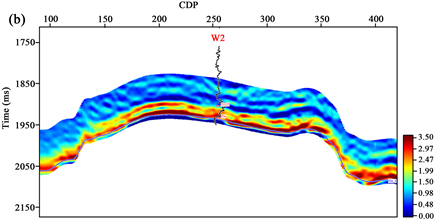
Figure 6. TOC prediction profile of well (a) W1 (b) W2 in the study area
图6. 研究区过(a) W1井(b) W2井TOC预测剖面
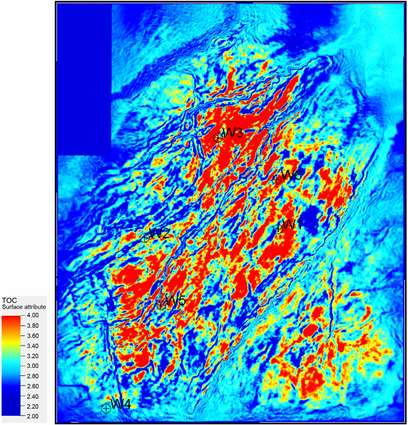
Figure 7. Plan of TOC prediction of shale in target horizon in the study area
图7. 研究区目标层位页岩TOC预测平面图

Table 1. Comparison between logging TOC value and seismic prediction results
表1. 测井TOC值与地震预测结果对比
3.2. 页岩孔隙度预测
孔隙度作为页岩气储层重要评价指标之一,因此本文同样对其开展预测。与前文TOC预测方法类似,选择回归拟合法。首先提取研究区W3、W4井测井曲线目的层段内的值进行预处理,然后将孔隙度实测值与其它岩石物理参数进行拟合。如图8所示,红色散点为实际测井曲线在目的层段约束下的数值,黑色线为拟合线,拟合结果显示,实际工区孔隙度值与纵波阻抗、横波阻抗、密度及纵横波速度比等参数均存在线性关系,其中相关性最高的参数为纵波阻抗,相关数值达到0.7158,其它参数相关性很差很难建立多元线性表达式,因此得到纵波阻抗与孔隙度的线性关系为:
(24)
式中,IP代表波阻抗值。
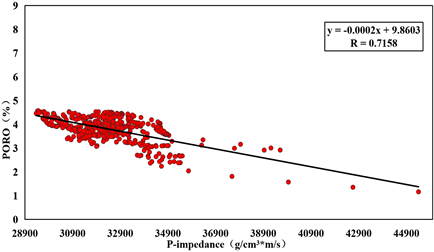
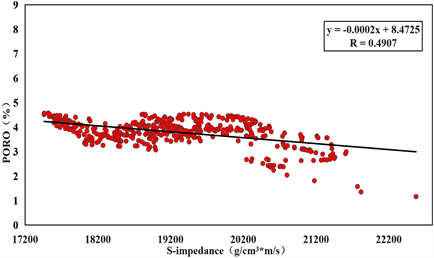
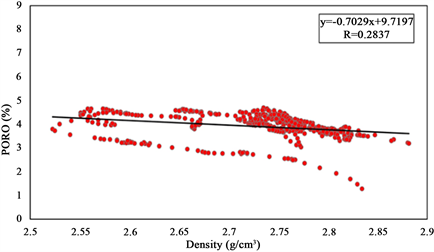
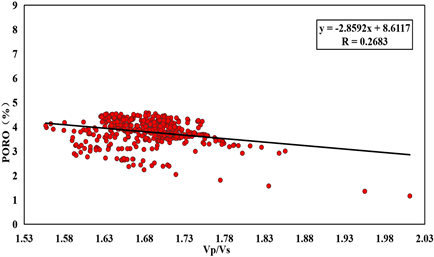
Figure 8. Analysis of porosity sensitive parameters
图8. 孔隙度敏感参数分析图
由于深度学习后的叠后波阻抗分辨率和精度相较叠前反演更高,因此计算得到线性回归方程后,将深度学习预测得到的波阻抗代入,即可获得整个工区孔隙度三维预测结果,如图9所示,图9(a)、图9(b)分别为过W1井和W2井预测剖面,图中可以看出,预测结果与测井曲线高低值趋势一致性较高,证明了该方法的准确性。
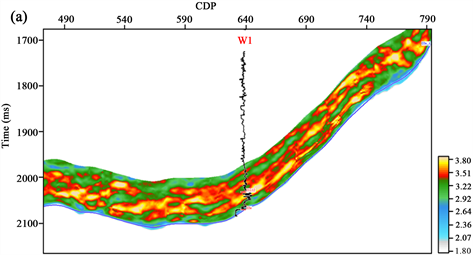
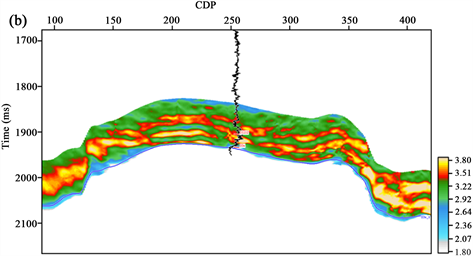
Figure 9. Porosity prediction profile of well W1 (a) and well W2 (b) in the study area
图9. 研究区过(a) W1井(b) W2井孔隙度预测剖面
为了验证结果的准确性,本文沿目的层段提取了孔隙度预测结果,如图10所示,并且将各井中的实测孔隙度值与预测结果进行对比分析,见表2,其中前四口井为反演井,后面两口(蓝色标注)为验证井,可以看到误差值较小,预测值跟井上值吻合度较高,说明该方法预测结果可靠。
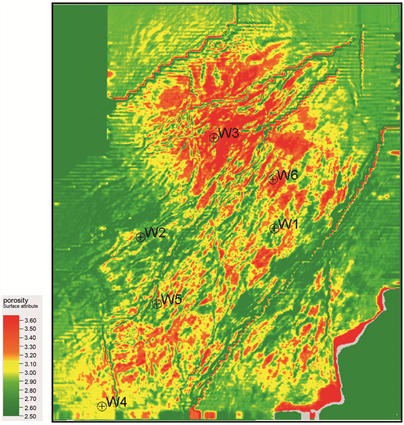
Figure 10. Shale porosity prediction plan of target stratum in the study area
图10. 研究区目标层位页岩孔隙度预测平面图
Table 2. Comparison between logging TOC value and seismic prediction results
表2. 测井TOC值与地震预测结果对比
3.3. 页岩脆性指数预测
因此,本文利用上述,在叠前反演的基础上计算泊松比、杨氏模量,最终代入Rickman公式获得脆性指数预测结果,如图11所示,图11(a)、图11(b)分别为过W1井和W2井预测剖面,预测结果与实测脆性指数曲线高低值趋势比较一致,证明了该方法的准确性。
为了验证结果的准确性,本文沿目的层段提取了孔隙度预测结果,如图12所示,并且将各井中的实测孔隙度值与预测结果进行对比分析,见表3,其中前四口井为反演井,后面两口(蓝色标注)为验证井,可以看到误差值较小,预测值跟井上值吻合度较高,说明该方法预测结果可靠。
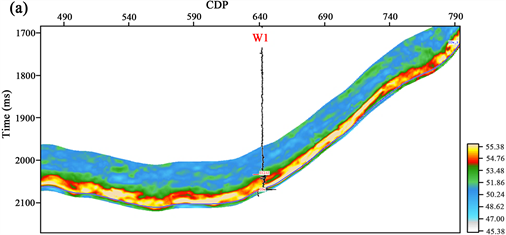
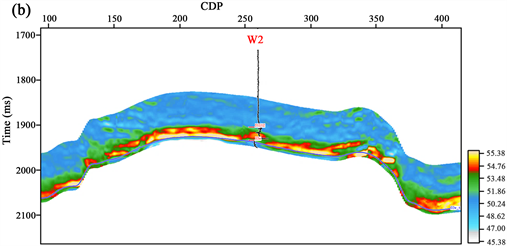
Figure 11. Brittleness index prediction profile of well W1 (a) and well W2 (b) in the study area
图11. 研究区过(a)W1井(b)W2井脆性指数预测剖面
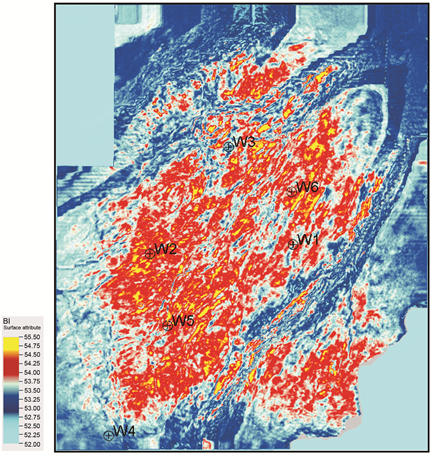
Figure 12. Plan for prediction of shale brittleness index of a layer in the study area
图12. 研究区目标层位页岩脆性指数预测平面图
Table 3. Comparison between logging TOC value and seismic prediction results
表3. 测井TOC值与地震预测结果对比
4. 甜点综合预测和评价
本文引入机器学习方法首先进行地质“甜点”预测,选择的页岩分类评价指标为上文预测得到的TOC、孔隙度、含气性以及脆性指数,为最后的优质页岩储层综合评价打下基础。
4.1. 基于机器学习的甜点预测
4.1.1. 样本构建
利用该算法进行甜点预测的训练集构建流程如下:
1) 检查测井和地震数据后,选择表征甜点的关键参数(TOC、含气性、孔隙度、脆性指数);
2) 结合表4页岩储层测井分类评价标准对实际测井数据进行分类(训练标签),根据表5页岩综合分类评价标准,以评估每个参数的贡献;
3) 选择工区内W3、W4井目的层内的数据进行标注,根据步骤(2)的分类结果,具体深度对应甜点类型,解释好的数据作为训练集,如表6。
Table 4. Comparison between logging TOC value and seismic prediction results
表4. 测井TOC值与地震预测结果对比
Table 5. Comprehensive classification and evaluation criteria for shale
表5. 页岩综合分类评价标准
4.1.2. 模型训练
在本文中,将PSO-SVM算法用于地质“甜点”预测中,并根据输入数据的规定调整了以下主要参数:
,粒子数 = 90,惯性权重
,学习因子
。
(迭代次数) = 200。同时,在样本集中随机选取80%作为模型训练样本集,以测试集预测值与实测值的分类准确度作为目标函数,如图13所示,迭代200次后,训练集的预测精度超过了97%,同时损失值逐渐收敛。
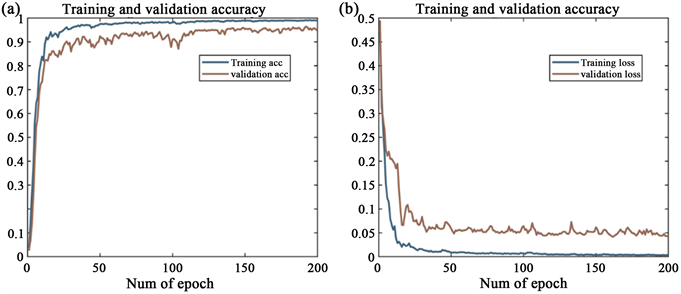
Figure 13. Training curve of this model. (a) Training set; (b) test set
图13. 本文模型训练曲线。(a) 训练集;(b) 测试集
4.1.3. 实际数据预测
在岩石物理分析和前期单个甜点参数三维预测的基础上,利用模糊优化原理和地震资料,识别了目的层段储层甜点,模糊优化方法更适合于预测和表征极不均匀油藏中的甜点。
前期预测出的TOC、孔隙度、脆性和含气性沿目的层切片见图14,各预测输入指标的范围和权重系数见表7。
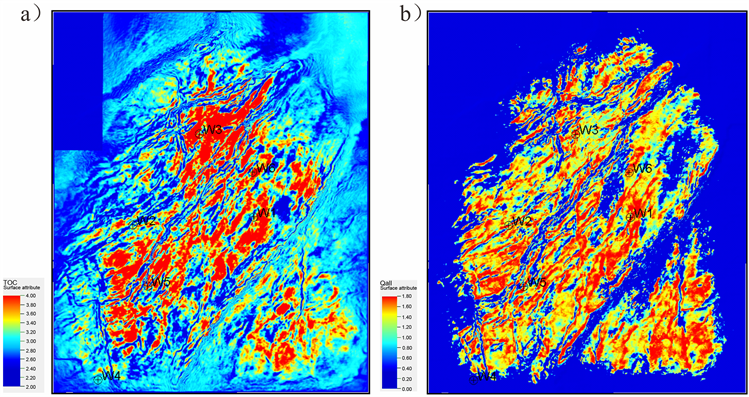
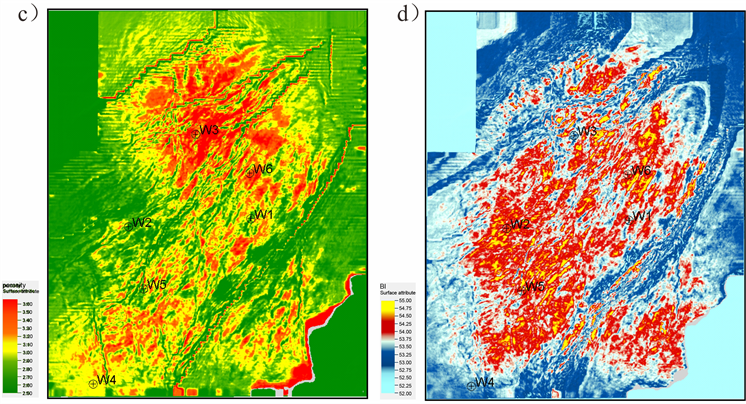
Figure 14. Predicted dessert input parameters. (a) TOC; (b) gas bearing property; (c) porosity; (d) brittleness index
图14. 预测甜点输入参数。(a) TOC;(b) 含气性;(c) 孔隙度;(d) 脆性指数
最终预测出的结果如图15,为储层预测甜点沿目的层切片,机器学习预测结果更好的刻画了甜点分布情况,克服了单一参数进行甜点预测的多解性以及不准确性,并且本文将预测结果与实际测井解释的分类结果进行对比,见表7,可以看到机器学习多参数预测结果与测井解释能够良好匹配,证明了本文方法利用地震数据预测甜点的可靠性。
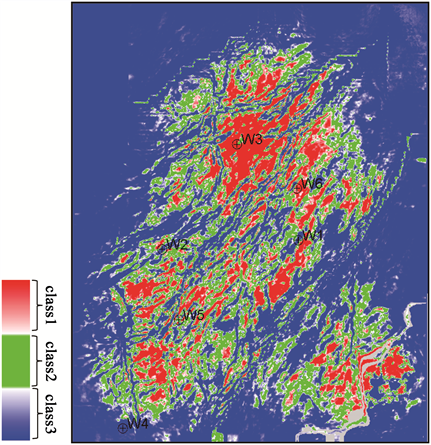
Figure 15. Slice the predicted dessert results along the target layer
图15. 预测甜点结果沿目的层切片
Table 7. Comparison of prediction results of well logging dessert
表7. 测井甜点预测结果对比
4.2. 页岩优势储层综合评价
结合工区内三维资料前期处理结果、构造解释结果、裂缝预测结果,根据区内钻井的目标层位优质页岩储层参数、甜点预测结果,参考页岩气储层测井分类评价标准,考虑优质页岩埋深情况,最终确定了本区优质页岩有利区划分标准,如表8所示。
Table 8. Comprehensive evaluation criteria for favorable reservoirs
表8. 有利储层综合评价标准
同时,通过有利区标准表的划分,结合前期预测的多种指标图件,对实际工区绘制优质页岩储层综合评价图,从而落实I类、II类、III类有利区,如图16所示,本文根据有利区指导井位选取建议如下:
1) 尽量避开断层发育区域,避开I类断层2 km,II类断层0.7 km;
2) 水平段位于优质储层区域;
3) 水平段地层平缓,断层不发育,微幅构造不发育;
4) 微裂缝相对发育。
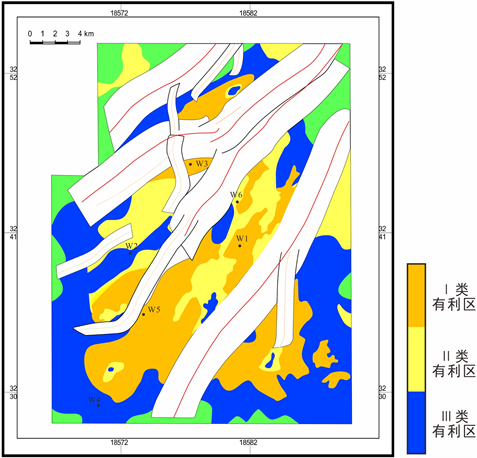
Figure 16. Comprehensive evaluation of high quality shale reservoir in the study area
图16. 研究区页岩优质储层综合评价图
5. 结束语
1) 为改善叠后反演波阻抗的精度,克服常规仅仅使用振幅作为深度学习输入的缺陷,本文提出一种在低频和高频信息约束下,同时结合地震数据空间分布特征的混合深度学习网络结构,该网络结构使用全局连接网络学习地震数据空间特征,局部连接网络学习地震与测井之间的数据特征,从而实现高分辨波阻抗反演,为页岩孔隙度预测打下基础。
2) 基于地震资料和测井资料开展研究区页岩优质储层参数预测:在实际测井资料的基础上,通过对目的层AVO特征分析,在叠前AVO属性的基础上进行研究区含气性预测;基于模型驱动高精度叠前反演弹性参数,采用回归拟合法预测TOC及孔隙度,利用岩石弹性模量中的泊松比及杨氏模量预测脆性指数,为机器学习“甜点”预测提供数据支撑。
3) 本文在得到各地质“甜点”指标三维预测体的基础上,结合页岩储层测井分类评价标准对实际测井数据进行分类,将SVM和PSO算法相结合,在前人回归算法PSO-SVR预测的基础上,应PSO-SVM分类算法完成研究区地质“甜点”精细化预测,克服了单一指标进行预测的多解性,并且本文将预测结果与实际测井解释的分类结果进行对比,匹配度较高,证明了该方法的准确性和有效性。