1. 引言
工业生产过程日益集成化、多样化、复杂化,一旦发生故障,会发生十分严重的经济损失和社会安全问题。为了维持工业生产过程的安全稳定运行,实现精确的工业过程的故障诊断是一直以来的研究重点 [1] 。
传统故障诊断方法一般采用基于知识的方法,然而该方法中的数据库并不具备特异性,因此在故障诊断过程中存在不适用性,且该方法要求工作人员具备相应的专业知识技能,要求较高。基于数据驱动的方法相较于传统故障诊断的方法,不需要建立复杂的数学模型,也不需要准确的先验知识,对于处理高维度的数据具有很大的优势,适用于复杂的工业过程,附加成本低,易维护 [2] 。随着信息平台的不断发展,一方面,工业过程中数据量急剧增加,另一方面,数据类型也朝着多元化发展,因此数据具有多源异构的特点。大量的数据为传统的工业过程故障诊断转为由数据驱动的故障诊断提供了可能。传统基于数据的工业过程故障诊断使用的数据集一般是工业过程数据,即传感器数值数据,且近年来工业过程故障诊断在精度上遇到了瓶颈,因此视频监控数据的出现为工业过程的故障诊断提供了新的方向。
在视频故障诊断分类领域,起初,研究人员将图像分类方法应用到视频分类中,Andrej Karpathy [3] 等人通过将视频分帧然后利用二维CNN方法对视频进行分类。N Davari [4] 等人从配电线路的视频中提取帧,使用Faster R-CNN在每一帧中检测电源设备,然后在整个视频帧中对其进行跟踪,然后,使用双流充气3D卷积(Inflated 3D ConvNet, I3D)来分别识别每个设备的图像中的电晕放电,确定初始故障严重程度。Ji Lin [5] 等人则通过将部分信道沿时间维进行移位,便于相邻帧之间的信息交换,提出了时间转移模块(Temporal Shift Module, TSM)。Mehmet Karakose [6] 等人通过改进的ViT对火车故障铁轨进行分类,实现了在线识别铁轨之间的故障类别。
近年来,由于Transformer [7] 在自然语言处理(NLP) [8] 领域展现的惊人潜力,研究人员开始尝试将Transformer应用到计算机视觉(CV)领域。Dosovitskiy [9] 提出了视觉Transformer (VIT),通过简单堆叠Transformer模块增强图像的空间特征提取能力,虽然在图像识别基准测试上取得了巨大的成功,计算复杂度却大幅增加。对于传统检测方法铁路接触网吊弦故障状态检测过程中存在的识别率低等问题,Xu等人 [10] 故提出了一种基于轻量型网络EfficientDet与VIT网络相结合的接触网吊弦状态检测算法。利用改进的Efficient Det [11] 用于吊弦定位,将定位后的吊弦送入改进Vision Transformer网络进行故障类别检测。该方法有效提高了故障检测准确率,同时提高了检测的效率。VIT的计算复杂度是图像大小的二次方,为了降低复杂度,Liu [12] 等人提出了Shifted Windows Transformer (Swin Transformer),引入了局部窗口和移动窗口的概念,在窗口区域和跨窗口进行无重叠的自注意计算。该方法克服了VIT中窗口之间缺乏连接以及计算复杂度过大的问题。
考虑到上述问题,本文提出了双流Swinc Transformer故障诊断视频分类模型,主要贡献如下:
1) Swin Transformer原模型只是一个二维的模型,改进了Swin Transformer Block,加入了3D卷积模块,构建了Swinc Transformer模型,将特征提取扩展到三维,既可以提取时间特征,又可以提取空间特征。
2) 引入了双流网络,以Swinc Transformer作为主干网络,进一步提取视频时间维度上的流动特征。
3) 引入了交叉注意力机制模块,用于融合光流特征和RGB特征,该模块在训练过程中自适应的调整光流特征和RGB特征的融合权重,以便于获取更高的分类精度。
2. 基本原理
2.1. 双流Swinc Transformer Block网络结构
视频分类主要就是关注两方面的特征,一是时间维度上连续帧之间的信息,二是空间维度上单帧图像所包含的特征信息,为此,我们提出了双流Swinc Transformer网络,整体结构如图1所示,为了捕获视频连续帧之间的流动特征,在Swin Transformer的Swin Transformer Block中加入了3D卷积模块,将模型维度扩充到了三维,提出了Swinc Transformer,并以Swinc Transformer作为
主干网络,引入双流网络,将光流图像与RGB图像作为输入,进一步捕获视频的连续特征。最终,为了更好的将光流特征与图像特征融合,采用了交叉注意力机制(CAM),可以自适应的分配视频特征权重,以便获取更全面的视频特征。将特征融合后经过全连接层进行故障分类。

Figure 1. Video fault classification model
图1. 视频故障分类模型
2.2. Swin Transformer Block
Swin Transformer在VIT的基础上引入了移动窗,使得相邻的两个窗口之间有了交互,且复杂度相对图片大小为线性相关,计算效率较高。Swin Trasnformer提出了基于窗口的多头自注意力机制(W-MSA)和基于移位窗口的多头自注意力机制(SW-MSA)。在W-MSA中,输入特征将被划分为非重叠窗口,每个窗口包含M × M个小切片,默认大小为7*7。W-MSA仅在本地窗口内进行自注意力计算。如图2所示,
和
分别表示第l层中W-MSA和LN & Linear模块的输出,计算如下:
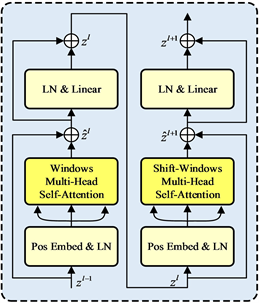
Figure 2. Swin Transformer block
图2. Swin Transformer Block
(1)
(2)
W-MSA的问题是在窗口之间缺乏有效的信息交互,SW-MSA引入跨窗口交互而无需额外计算,它通过循环移位将特征窗口往左上角上移,溢出部分往反方向填充,这样在移位之后,特征窗口可能由特征映射中的多个非相邻子窗口组成,并同时保持相同数量的特征处理窗口作为常规分区。自注意力计算在W-MSA和SW-MSA的局部窗口内进行,计算相似度时会考虑相对位置偏差。通过这种移位窗口划分机制,SW-MSA和LN & Linear模块的输出
和
可以表示为
(3)
(4)
VIT的计算复杂度是图像大小的二次方,这使得许多密集预测和高分辨率图像任务很难进行。Swin Transformer自注意力是在小窗口之内算的,它的计算复杂度是随着图像大小而线性增长,而不是平方级增长,计算复杂度如公式所示:
(5)
(6)
其中h、w表示图片的高和宽,每张图片包含的切片数量为M*M。
2.3. Swinc Transformer Block
由于Swin Transformer Block主要是用于提取视频的空间特征,而忽略了视频的时间特征,为了提取视频中水流流动的连续特征,我们在Swin Transformer Block加入了3D卷积模块,提出了Swinc Transformer Block,结构如图1右图所示,主要包含窗口多头自注意模块(W-MSA)、3D卷积模块、移动窗口多头自注意模块(SW-MSA)。Swinc Transformer Block的输出
可以表示为:
(7)
(8)
2.4. CAM
交叉注意力机制模块,用于融合光流特征和RGB特征,该模块在训练过程中可以自适应的调整光流特征和RGB特征的融合权重,模型结构如图3所示。为了挖掘光流图像与RGB图像特征通道之间的相关性,首先通过式(9)使用全局平均池化操作在特征图每个通道维度大小为
的特征上进行压缩变换,得到模态特征的通道描述符
,然后再根据公式(10)获取对应模态的权重系数,记为
。
(9)
(10)
其中
、
是可训练参数,表示线性映射。
由上方法可分别得到光流图像特征与RGB图像特征对应的权重系数
、
。然后再根据式(11)、(12)使用权重系数交叉激活对应数据特征,使得两种数据特征信息相互引用,达到相互增强的目的。
(11)
(12)
、
分别表示经过交叉注意力后模态特征的输出。
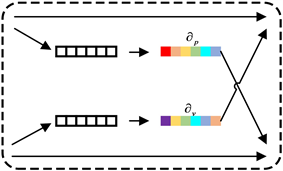
Figure 3. Cross attention mechanism
图3. 交叉注意力机制(CAM)
3. 实验结果与分析
3.1. 实验数据集
本文使用的数据集是PRONTO基准数据集 [13] ,收集自克兰菲尔德大学过程系统工程实验室的全自动、高压、多相流设备。该设施为研究多相流的输送、测量和控制而设计的,允许对包括水、空气和油在内的多相流进行研究。该设施,描述了不同操作条件下的测试和诱发的故障。有两种数据类型,包括工业过程数据,即传感器数值数据,视频数据。每种数据包含三种相同的故障类型,分别是空气泄露、空气堵塞、分流。过程数据是由31传感器以1 hz的采样率采集到的数据,包括2800组数据,每组数据由31个传感器以1 hz的频率采样获得。视频数据拍摄的是透明管道中水流的流动状态,时长为10~30秒。视频数据被分为960个精细视频片段,剪辑的长度不小于一秒,不超过5秒。在此数据集中,训练、测试集的比例为7:3。
3.2. 实验细节
在实验中使用Adam优化器 [14] 更新网络参数,使用交叉熵损失函数用于计算分类损失 [15] ,先求出所有类别的总的精确度和召回率,然后计算出的f1分数即为Micro F1分数 [16] ,它可以很好的评价一个多分类模型的性能,因此使用准确率、Micro F1分数,精确度,召回率作为评价指标。
在训练过程中,需要调整的超参数有:学习率,视频帧批量大小,网络的层数表示每个Basic Layer中Swinc Transformer Block的个数,移动窗口的大小模型中移动子窗口的大小,网络的隐藏层维度大小表示每个Basic Layer中Swinc Transformer Block的维度大小,注意力头数表示Swinc Transformer Block的注意力头数,丢弃率,超参数的值如表1所示。
3.3. 实验结果与可视化分析
在表2中,是视频数据故障诊断模型精度对比以及消融实验,同时,为了验证视频数据是作为增强故障诊断的新方向,实验中还加入了过程的数据的故障诊断模型作为对比。可以看到,整体上,在普通的故障诊断方法中,过程数据的故障诊断精度更具优势,然而在将SwinTransformer扩充到3维后,视频数据的故障诊断精确度有了明显的提升。本文所提模型实验结果如实验18所示,相比其他视频故障分类模型和过程数据故障分类模型,具有显著优势。GRU解决了RNN长时间“遗忘”的问题,在过程数据故障分类模型中准确率最高。视频分类模型中,Deep Video的性能最差,原因是它是按照图像的方法去处理视频的,并没有考虑时间维度。而对于工业过程的视频而言,只有充分考虑水流的流动信息才能知道该视频属于哪个工业过程,因此,对于该工业过程视频数据,考虑时间维度的特征是十分有必要的。实验7、8、9是3D卷积的相关模型对比,可以看到实验10到实验14的模型整体上性能要优于3D卷积相关模型,原因是虽然3D卷积学习了空间特征的同时也学习了时间特征,但它提取时间流动信息的能力有限,不如光流。另外,实验12、13采用特定的方法对视频的连续帧进行操作计算,提取时间特征的能力相较于3D卷积有所加强,但是比光流特征弱。这与以往的研究不同,原因可能是对于PRONTO水流视频数据集,模型的分类性能过于依赖水流的流动信息。而光流图像正是提取流动信息的最佳方式。VIT和Swin Transformer由于没有考虑时间维度,分类性能较低,在引入3D卷积和双流网络后,分类性能得到大幅提升,实验18比17提升明显,表明双流模块相比3D卷积可以获得更好的分类性能。
为了更直观的展示本文所提出的模型的优越性,图4所示为消融实验的损失值随epoch的增加的变化曲线,可以看到本文所提模型损失下降收敛的最快,而且震荡最小,Swin Transformer模型损失下降最慢。图5是基于双流Swinc Transformer的混淆矩阵,可以直观的看到我们所提模型对于不同故障的预测性能,其中,分流故障的预测性能最佳,预测虽然也存在误差,但是相比于其他类型,预测性能最佳。
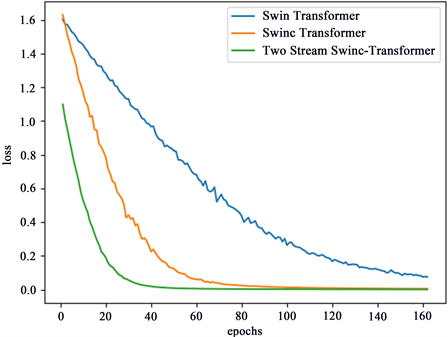
Figure 4. Loss convergence curve of ablation experimental model
图4. 消融实验模型的损失收敛变化曲线

Figure 5. Confusion matrix based on two stream Swinc Transformer
图5. 基于双流Swinc Transformer的混淆矩阵

Table 2. Comparison results of fault diagnosis classification models
表2. 故障诊断分类模型对比结果
4. 结束语
传统工业过程的故障诊断使用的数据集一般是工业过程数据,即传感器数值数据,且近年来工业过程故障诊断在精度上遇到了瓶颈,因此视频数据的出现为工业过程的故障诊断提供了新的方向。本文提出了一种双流Swinc Transformer故障诊断方法。该方法将Swin Transformer扩充到了三维并引入了双流网络,实现了同时提取视频时间和空间特征的效果。在PRONTO基准数据集中,该方法具有较好的故障诊断性能。
为了获取更高的故障诊断精度,考虑到工业过程数据和视频数据在信息特征上具有互补的特点,未来可以考虑通过多模态融合的方式来提取更全面的信息特征,实现更高精度的故障诊断。
基金项目
国家自然科学基金(61903251)。