1. 引言
图像修复是根据残缺图像的完好部分对图像缺失信息进行重建,使修复图像与原始图像具有相似结构的一项技术。现有的图像修复方法主要有两类:传统方法和基于深度学习的方法。传统方法中,基于偏微分方程的方法利用物理学中的热扩散方程 [1] [2] [3] ,将缺失区域相邻信息传播到缺失区域中,该类方法对细小损伤有较好的修复效果,但当受损面积大时修复效果差。当图像大量信息丢失时,多采用基于纹理合成的修复方法 [4] [5] [6] ,通过模仿图像其他区域的纹理,生成纹理片段填充缺失区域。此种方法不能捕获图像的语义信息,易导致图像不连贯。
为弥补传统方法的不足,研究者们进一步探索基于深度学习的算法。Pathak等 [7] 提出Context Encoder网络,在类似“沙漏”的网络结构中增加对抗损失,使得生成的图像具有合理结构,但该算法的修复结果存在伪影和边缘模糊的问题。为解决上述不足,Li等 [8] 在此基础上增加了一项新的对抗损失,将修复区域补全到原图后再判断整个修复图像的真伪,保证生成的内容更加合理的同时,维持边界像素值的连续性,但此种方法仅能处理背景较简单的规则缺失。此后,Yu等 [9] 提出基于内容感知层的前馈生成网络,将修复过程分成粗修复及细修复两阶段,可有效修复大面积规则缺失,可以生成语义合理的结果,但在修复随机孔洞时,缺乏整体与局部信息的语义一致性。为有效修复随机不规则缺失区域,Liu等 [10] 提出用部分卷积代替普通卷积的修复算法,利用有效像素自动掩码更新机制推断并修复缺失区域,能处理背景简单、随机不规则的小面积缺失区域,但修复边缘数据稀疏的区域中,修复质量降低。其后,Nazeri等 [11] 提出了一个包括边缘生成器和图像补全网络的二阶段生成对抗网络,用边缘生成器预测生成边缘,再使用预测边缘作为先验填充缺失区域,该网络在背景简单时可得到逼真的细节纹理,但无法重建大面积不规则缺失图像。Zheng等 [12] 提出一种多元图像修复算法(PIC),采用重建路径与生成路径并行的结构,可修复较大面积不规则缺失,但该算法在复杂背景下会出现结构变形且色彩不协调的问题。为修补背景复杂的大面积缺失区域,Peng [13] 等提出基于分层的多解修复算法(VQ-VAE),其运用条件自回归网络和结构注意力模块生成具有高度多样性的合理结构,但缺失区域面积增大至30%及以上时,该算法的修复结果包含纹理细节失真和局部模糊。Jam [14] 等提出反向掩码网络(R-MNet),将Wasserstein GAN与一种新型反向掩码算子相结合,可捕捉数据分布并生成兼具逼真与连贯性的图像,但在修复背景复杂且缺失区域达30%及以上缺失时,生成图像边缘过渡模糊,视觉质量下降。此后,Suvorov等 [15] 利用快速傅立叶卷积对具有全局感受域的频域特征进行编码,捕捉图像高感受野以获取图像整体结构,该算法可修复大面积随机破损的图像,但主要提取纹理特征,损失大量的结构信息,因而生成图像结构细节模糊、清晰度低且掩码处含有色彩伪影。
综上所述,现有图像修复算法在处理人为破损图像中含复杂背景的大面积不规则缺失区域时,难以把握整体结构的完整度和纹理细节的清晰度,生成的图像存在结构不合理,边缘模糊,分辨率较低等问题。为克服此缺陷,本文仅针对人为破损图像,提出一种基于高效注意力的密集残差图像修复算法,主要创新点在于:1) 通过下采样提取破损区域的细节特征,将其传递至包含空洞卷积的密集残差网络,增大信息感受野的同时,捕获更多的纹理细节信息,提升了在含有大面积区域缺失的残缺图像上的修复效果。2) 引入了高效注意力机制,通过(Key, Query, Value)的三元组有效捕捉全局上下文信息,将通道按特征图加权聚合生成全局上下文向量,描述输入的全局特征,并增强修复纹理的细粒度,增强了在纹理细节复杂的残缺图像上的修复效果。3) 引入超图卷积模块,用于捕捉全局结构信息,复原图像的结构纹理信息。
2. 基于高效注意力的密集残差卷积图像修复
基于高效注意力的密集残差卷积图像修复算法如图1所示:首先,对人为破损图像进行下采样操作,即在生成对抗网络中设置卷积核大小对破损图像卷积得到FeatureMap,再采用基本的区域归一化并调节池化层步长对其进行特征的粗提取,至此完成下采样过程。该部分主要负责降低图像的特征维度并保留精简的特征信息,然后,将提取出的特征信息输入包含空洞卷积的密集残差生成网络,此密集残差生成网络中,外层是包含三层密集残差卷积的多尺度融合空洞卷积块组合的卷积网络,内层是包含着高效注意力机制的卷积网络,超图卷积模块与之平行,连接第二层与倒数第二层的卷积块,其中,密集残差部分主要负责细化提取特征,进一步扩大感受野,捕获更加精细的特征纹理信息。同时,通过增加高效注意力机制,使用特征图的加权聚合有效捕获上下文信息。然后将其输入到超图卷积模块,修复多元关联对象的关系以更准确地描述全局语义信息并减小语义信息丢失。最后,将生成图像输入SN-Patch GAN鉴别器进一步判别优化,加强修复图像的结构完整性和纹理真实性。
2.1. 高效注意力机制
注意力机制对于学习图像修复中跨空间位置的模式具有重要意义 [9] [16] [17] ,有利于主干特征提取网络对颜色、线条等浅层语义特征的提取。该模块的主要作用是通过学习通道间的相关性,为每个通道分配权重,从而使网络更关注关键语义特征。然而,注意力模块的计算成本很高,且在图像修复中不易并行化 [10] 。为有效捕获远程特征并保证修复模型的效率,提出算法引入高效注意力(Efficient Attention)模块。首先将输入特征
和掩码
重构为
和
,分别作为矢量数据。从而可将高效注意力的过程记为:
(1)
上式中,
表示由输入像素矩阵X生成的学习参数矩阵,分别对应query、key、value三个特征,其中:
表示在softmax操作之前对输入图像屏蔽缺损部分的像素。
和
分别表示对输入的行和列应用柔性最大值传输操作,得到非线性归一化的处理结果。然后将输出
,重新整形为
。提出算法使用的是普通注意力操作的近似值 [18] ,输出 是由
而不是由标准的
计算所得,即
的计算顺序变换为
,将计算复杂度从
转变为
。由于
实际上永远小于
,复杂度呈线性,该方法可以显著降低计算成本。在实际计算机应用中,维度d远小于hw,因此提出算法引入多头注意力 [19] 进一步将维度从d减小到
。因此,
可在特征级聚合查询Q并获得全局上下文E。Efficient Attention模块是受激励的,以掩盖缺损区域的注意力分数而聚合未缺损区域的特征。
2.2. 超图卷积
简单图的每个边仅连接两个节点,能基本表示数据之间的成对关系,但很难描述图像空间特征之间的复杂关系,因此提出算法使用超图卷积捕捉缺失区域的全局信息并增强修复细节的完整性。
令
为由有限顶点集V、超边集E和超边的权重
组成的超图。每个超边都有一个权重
。超边G表示为
关联矩阵H方程式,其中每条边定义为:
(2)
基于关联矩阵H,顶点的度数可以定义为
,即对每一个边度进行加权求和;超边的度数定义为
,即对每一个节点度加权求和。其中,
和
分别表示顶点度和超边度的对角矩阵,W表示超边权重的对角矩阵。
节点特征通过求和操作构建出所连接的超边特征,相应地,超边特征经过聚合后重新应用于节点特征的更新。用于超图学习的归一化拉普拉斯方法可表示为:
(3)
其中,f表示要学习的相关性分数,
表示归一化成本函数,
是经验损失,
是用于平衡正则化器和经验损失的参数。上式中通过对
最小化操作,共享多数偶发超边的顶点可以计算出相似性质的相关分数。整理得到超图的正则化器定义为:
(4)
在此对正则器作出简化:令
,代表超边特征聚合预测出节点在下一回合特征表
示的操作,再令
,则正则化器可以重写为
,其中超图拉普拉斯算子
是一个半正定矩阵。
2.3. 损失函数
1) 生成器损失函数
定义生成器损失函数
评估预测图像的两个方面:缺失像素区域的质量和整个图像的感知质量。围绕这两个指标构建
确保生成器生成准确的缺失像素。使用特征空间鼓励对抗性训练生成具有相似特征的图像,从而获得更真实的结果。提出算法的损失函数将逐像素对比改进为用VGG提取高级特征,计算损失模型输入和输出的平方差作为感知损失 [20] (
),如式(5):
(5)
其中k是
的大小,
是使用I作为输入运行VGG19的前向传递获得的特征,
是对生成器
的输出运行前向传递获得的特征。
定义反向掩码损失(
),仅针对掩码区域创建的有效特征进行重建。反向掩码损失对应图像上掩码区域相应像素和掩码图像重建像素的平方差,使用反向掩码(
)和原始图像(
)来获得
,其中,
(6)
最后通过线性组合感知损失
和反向掩码损失
,得到生成器损失函数:
(7)
其中
,通过最小化缺失区域的误差来匹配与真实情况相当的预测,从而对特征进行最佳评估。
2) 判别器损失函数
使用Wasserstein距离损失函数(
)训练网络,对其定义如式(8):
(8)
其中,
是真实数据分布的概率,
是生成的数据分布。
3. 实验结果与分析
在CelebA-HQ和Paris-street数据集上,将提出算法与现有三种算法进行实验对比。CelebA-HQ和Paris-street数据集分别包含高清人脸和街景图像。设备参数为CPU:Intel i7-9700K,GPU:RTX2080Ti。代码在Pytorch深度学习框架下运行,将提出算法与PIC算法 [12] 、VQ-VAE算法 [13] 和RM-Net算法 [14] 进行对比,掩码为人工设置的不规则掩码,掩码大小为40%~60%。生成网络的学习率为1 × 10−4,鉴别器的学习率为1 × 10−1。
3.1. 主观实验结果
为了保证比较的公平性,所有模型的迭代次数相同。
图2是不规则掩码大小为40%~60%时,各算法分别在Celeba-HQ数据集及Paris-street数据集上的修复效果,直观比较细节已在图中标出。

Figure 2. The comparison experiment 1 of CelebA-HQ
图2. CelebA-HQ对比实验1
图2(a)为原图,图2(b)是掩码图,缺失区域达到前景的45%左右,且为随机不规则缺失。图2(c)~(f)分别为PIC算法、VQ-VAE算法、RM-Net算法以及本文算法的修复结果。由图可见PIC算法能生成较为合理的面部结构,但图像边缘出现明显的修复斑点。VQ-VAE算法生成的人像存在大面积修复痕迹,且右侧嘴角结构扭曲。RM-Net算法的修复效果整体较好,但嘴角及头发边缘处存在较大面积伪影,修复细节不够清晰。相对而言,提出算法修复结果更接近原始图像,且结构完整,面部细节纹理清晰。
图3(b)中随机缺失区域面积超过50%,且主要缺失集中,覆盖右侧主体区域,存在局部细节的修复困难。PIC算法的修复结果结构合理,但右侧头发细节丢失,图像四周浮现出大块修复斑点。VQ-VAE算法的修复结果信息缺失,右眼的结构不合理,眼睛和嘴角存在不同程度的形态扭曲。RM-Net算法生成的图像相对完整,但头发出现大面积可见斑块,鼻翼和嘴角的纹理细节较为扭曲,同时眼睛的修复效果也比较模糊。而本文提出算法不仅能生成合理的结构,且能兼顾整体与细节的语义一致性,眼睛和头发细节的修复结果较其他算法更为准确细致。

Figure 3. The comparison experiment 2 of CelebA-HQ
图3. CelebA-HQ对比实验2
图4(b)的掩码区域遮挡了人脸的60%以上,且掩码分布较为分散。从修复结果看:VQ-VAE算法修复效果差,整体存在大面积的修复斑点和不均匀色块,眼部结构较为不合理。RM-Net算法的修复结果能保持较好的整体一致性,但同样是眼睛细节不够清晰,且额头处存在明显色差斑块。PIC算法能正确复原图像纹理,面部细节也较为精细,但发梢边缘存在大面积模糊光影,轮廓语义丢失。相对而言,使用提出算法修复得到的整体结构更为真实精致,颜色一致性保持较好。
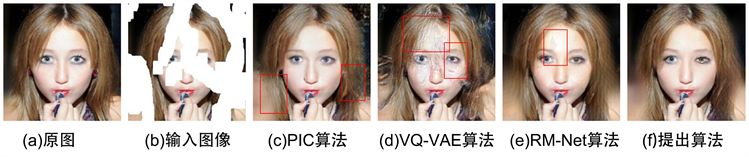
Figure 4. The comparison experiment 3 of CelebA-HQ
图4. CelebA-HQ对比实验3
图5是对Paris-street的修复结果对比。图5(b)中部分缺失面积达到85%左右,且背景复杂,包含大量纹理细节。从实验结果可看出:VQ-VAE算法的修复效果较差,大理石柱的轮廓及建筑的结构扭曲,可见原缺失痕迹及较大面积的明显掩码痕迹。PIC算法修复的整体结构相对完整,轮廓较为笔直锋利,但边缘区域存在像素丢失及内容不连续的问题,重影明显。RM-Net算法能较好地捕获整体语义信息,但不能呈现出精细的纹理,表现为边缘模糊,存在掩码痕迹。提出算法修复的目标边界清晰,结构明确,纹理有序,掩码处不存在可见伪影。

Figure 5. The comparison experiment of Paris-street
图5. Paris-street对比实验
3.2. 定量评估
为客观评估本文提出算法的效果,选择三种定量评估指标进行效果对比。使用峰值信噪比(PSNR)比较图像在纹理及像素层面的差异,凭借结构相似度(SSIM)区分图像在结构、亮度以及对比度上的差异,通过l1(%)损失度量预测值和真实值之间的差距。对比算法均导入统一的训练集和测试集,采取相同的训练机制,以减少训练和测试过程中可能产生的误差。
表1为各算法在CelebA-HQ数据集上叠加不规则掩码的修复性能指标,由实验结果可知:提出算法的PSNR、SSIM、l1(%) 3个指标都高于比较算法。相比整体修复效果较好的RM-Net算法,提出算法的PSNR提高了2.56,SSIM提高了0.088,l1(%)损失降低了0.86。客观实验指标也验证了提出算法的有效性。

Table 1. Quantitative comparison experiments
表1. 定量实验对比
以上评价结果皆表明提出算法在把握全局结构,纹理细节及语义信息方面均表现出较好性能,均优于比较算法。
4. 结论
本文提出了一种基于高效注意力的密集残差修复算法。首先,对人为破损图像下采样,将提取的细节特征输入包含空洞卷积的密集残差网络,扩大信息感受野从而对细节纹理信息进行更加深入的提取。然后引入补充高效注意力机制,通过生成的全局上下文向量,表达输入特征的全局结构。同时叠加超图卷积模块,捕获全局信息,增强修复纹理的细粒度。最后,将生成的图像输入SN-Patch GAN鉴别器进行判别优化,进一步提升修复结构的整体一致性和细节纹理的精细度。将提出算法与现有的三种算法进行比较,实验结果表明:当待修复图像存在大面积不规则缺失时,提出算法有效提高了修复结果的结构合理性及纹理细节的精度,主客观指标优于对比算法。
项目基金
国家级大学生创新创业训练计划支持项目(202110673087)。
NOTES
*通讯作者。