1. 引言
基于集合论,波兰学者Pawlak于1982年提出了粗糙集理论 [1] ,粗糙集理论是用于处理不精确、不一致、不完备信息和知识的有效工具,其主要思想是通过上下近似来表示数据中的确定性与不确定性,从而推导出相应的决策规则。属性约简 [2] [3] [4] [5] 作为粗糙集理论数据预处理中的一个重要步骤,目的是减少属性维度和计算复杂度,做到数据降维。目前,许多学者对属性约简作了深入的研究并取得了很多成果 [6] [7] [8] [9] [10] ,但目前的研究大多以在传统粗糙集理论不断改进启发式属性约简或差别矩阵算法为主 [11] [12] [13] 。
超图是图论中的一种扩展,能够表示节点之间的多重关系,被广泛应用于数据分析、图像分割、社交网络等领域。超图应用于数据分析主要包括超图聚类、超图分析、超图可视化等方面。超图理论将数据点作为节点,利用超图表达样本之间的关系。超图分析方法将数据点和特征作为节点,利用超图表达数据之间的依赖关系,实现数据分析,能够将复杂数据映射到超图上,展示数据之间的关系和特征,提高数据的可视化效果和理解性。
本文从超图理论的角度出发,将超图理论的最小顶点覆盖算法与序决策系统相结合,提高约简效率。经实验证明本文所提算法具备一定的有效性。
2. 基本概念
2.1. 序决策系统
设一个四元组
为一个信息系统,如果在信息系统CIS中的某一属性的值域上存在偏序关系,则称该属性为一个准则。当CIS中每个属性都为一个准则时,该系统为一个序决策系统
。其中:
· U:表示所有对象的集合,称为论域。
· AT:包含条件属性集合C和决策属性集合D。
· V:表示条件属性集合C和决策属性集合D的值域。
· f:代表一个映射函数
,论域中的每一个对象在条件属性和决策属性上对应一个属性值,即
。
定义1 [14] 在序决策系统
中,对于
,有优势关系定义如下:
(1)
且满足
。其中,
表示在属性q下,对象
优于对象
。
优势关系是一个满足自反性、传递性和不对称性的偏序关系。因此,优势关系
可以导出论域在条件属性子集上的覆盖
。其中,
称之为优势类,且
。在决策属性上,同样有一个覆盖表示为
,其中
称之为决策类。
定义2 [14] 在序决策系统
中,对于
,有下、上近似定义如下:
(2)
(3)
且边界域表示为
。
2.2. 超图
超图理论是对传统图论的扩展和推广。在传统图论中,图由节点和边组成,而超图引入了超边的概念,以允许节点之间的多重关系。在超图中,超边可以连接多个节点,而传统图中的边只能连接两个节点。超边可以连接任意数量的节点,从而更好地捕捉节点之间的复杂关系。每个节点和超边可以具有任意类型的属性,这使得超图可以应用于各种实际问题。
定义3 [15] 设超图为一个二元组
,其中
为顶点集合,
为超边集合。
如图1所示为一个超图,共包含13个顶点和8条超边。
3. 基于序决策系统的下近似属性约简算法
序决策系统的下近似约简定义如下:
定义4 [14] 在序决策系统
中,对于
,
。当
为序决策系统的下近似约简,当且仅当满足以下条件:
1) 对于
,有
;
2) 对于
,
,有
。
条件(1)为联合充分性,条件(2)为个体必要性。
定义5 [14] 在序决策系统
中,对于
,
。
为一个规模为
的差别矩阵。且满足以下条件:
(4)
其中,
。
定义6 [14] 在序决策系统
中,对于
,
。
为一个规模为
的差别矩阵,其差别函数定义如下:
(5)
基于上述定义,给出序决策系统下经典差别矩阵算法(Classical discernibility matrix algorithm in ordered decision system, CDM-ODS) (表1)。

Table 1. Classical discernibility matrix algorithm in ordered decision system (CDM-ODS)
表1. 序决策系统下经典差别矩阵算法
4. 基于图顶点最小覆盖的属性约简算法
差别矩阵算法进行属性约简的过程与图论中寻找最小顶点覆盖集之间存在共同点。因此针对这种情况,可以将序决策系统构造出的差别矩阵生成一张超图,在超图上进行求解顶点最小覆盖。
定义7 设二元组
为一个超图,V顶点集合,E是超边集合。在超图
中定义如下布尔函数:
(6)
对该函数求解极小析取范式所得结果就是最小顶点覆盖集合。
定义8 在序决策系统
中,
为序决策系统生成的差别矩阵,由该系统差别矩阵导出的超图定义如下:
(7)
其中,顶点集合
,超边集合
。
定义9 在序决策系统
中,
为序决策系统生成的差别矩阵,由该系统差别矩阵导出的超图为
。顶点集合
,则V中顶点的度表示为
,顶点的度表示为与顶点相关联的超边数。
定理1 在序决策系统
中,
为序决策系统的差别矩阵生成的超图,则有
。
其中,
代表超图
的定点最小覆盖。
证明:
要证明
首先假设
为该系统生成的差别矩阵。通过定义8可知诱导超图
的超边集合
,因此有
。这将分为以下两种情况:
情况一:
;
情况二:
。
在情况一中,通过定义7可知显然
;在情况二中,由
可知
,即
,根据吸收律可得
。综上得
。
基于上述定理,给出序决策系统下基于图顶点最小覆盖的属性约简算法(Attribute reduction algorithm based on graph vertex minimum cover in ordered decision system, ARGVMC-ODS) (表2)。
Table 2. Attribute reduction algorithm based on graph vertex minimum cover in ordered decision system, ARGVMC-ODS
表2. 序决策系统下基于图顶点最小覆盖的属性约简算法
5. 实验分析
本实验选取八组UCI数据集进行约简效率和分类精度的对比,详细信息如表3所示。在验证算法有效性之前,使用WEKA3.8对数据集进行离散化预处理。本节进行的所有的实验都是在一台带有MacOS13.0 Ventura、Intel(R) Core(TM) i9-9880H八核2.30 GHz CPU和16GB内存的笔记本电脑上进行。算法在Pycharm2023开发工具是使用Python编写,实验图使用MatlabR2021a绘制。
5.1. 约简效率
如图2所示为本文所提算法ARGVMC-ODS与经典差别矩阵算法CDM-ODS在序决策系统下按论域规模比例均匀增加时的算法执行时间曲线。从中可以看出,当论域中的对象数量比例较小时,算法效率差别不大。当对象的规模逐渐增大时,两种算法的执行时间均有上升,并且经典差别矩阵算法CDM-ODS
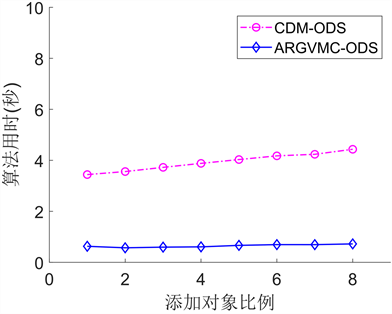
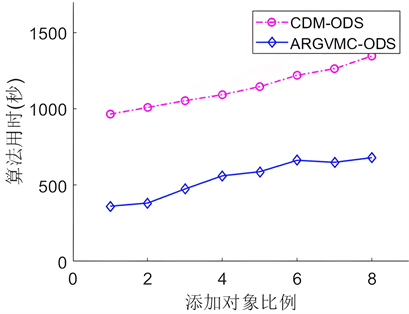
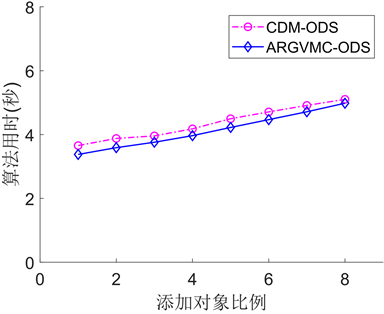
(a) Wine (b) Abalone (c) Car
的执行时间始终最长。本文所提算法ARGVMC-ODS与之相比,整体运行时间都有所缩短,且变化较均匀。因此,本文所提算法ARGVMC-ODS相对于经典差别矩阵算法CDM-ODS的约简效率较高,在大规模数据集上优势较为明显。
5.2. 分类精度
如图3与图4所示为本文所提算法ARGVMC-ODS与经典差别矩阵算法CDM-ODS在序决策系统下在不同数据集上分别在KNN与SVM分类器上的分类精度对比。在本实验中采取十倍交叉验证的方法计算分类精度。其中,经典差别矩阵算法CDM-ODS能够得出所有约简结果,而本文所提算法ARGVMC-ODS能够得出最短结果,因此对经典差别矩阵算法CDM-ODS的约简结果取平均值。从图中可以看出,本文所提算法在实验数据集上有较高的分类精度。
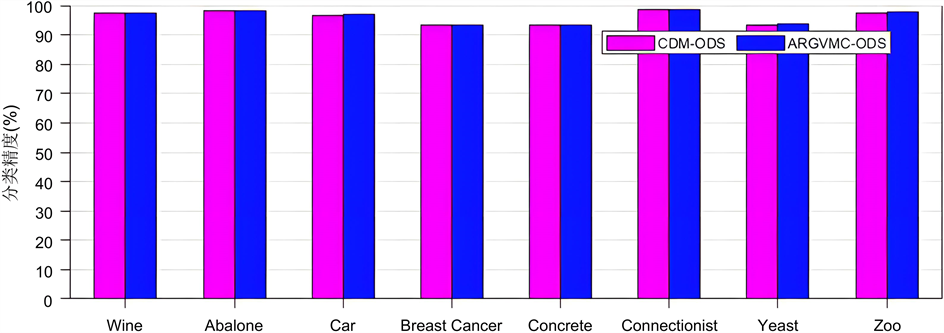
Figure 3. Comparison of classification accuracy (KNN)
图3. 分类精度对比(KNN)
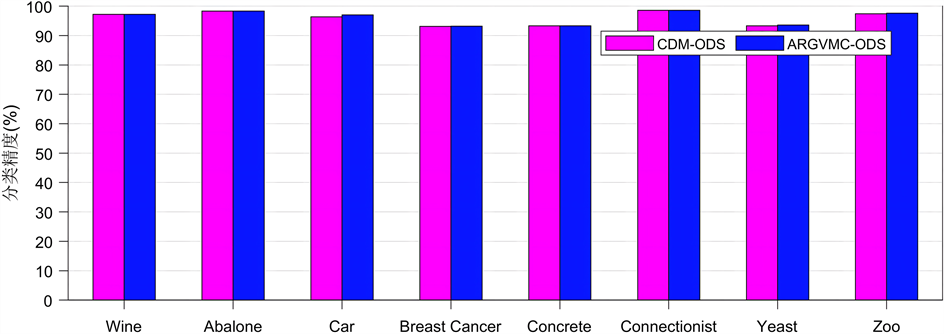
Figure 4. Comparison of classification accuracy (SVM)
图4. 分类精度对比(SVM)
6. 结论
在本文中,首先通过寻找最小顶点覆盖和差别矩阵属性约简的共性,进一步提出在序决策系统回顾下基于顶点最小覆盖的属性约简算法,将图论与粗糙集理论相融合。本文所提算法ARGVMC-ODS与差别矩阵算法思想相比,无需计算最小析取范式,避免了时间复杂度过高的问题,能够提高算法效率。通过选取的八组UCI数据集上进行算法有效性验证。从实验结果可以看出,本文所提算法相比于传统的差别矩阵算法效率较高。
基金项目
本文受烟台市科技计划项目(编号:2022XDRH016)的资助。