1. 绪论
1.1. 引言
多目标优化是现实生活中许多实际问题的重要组成部分,如工程设计、资源分配、机器学习等。在多目标优化问题中,通常存在多个相互竞争的目标,需要同时考虑这些目标并找到平衡的解决方案。然而,传统的单目标优化算法往往无法处理多目标优化问题,因为它们只能生成单一最优解。因此,研究者们提出了多种多目标优化算法,其中基于NSGA-II (Non-dominated Sorting Genetic Algorithm II)算法的研究引起了广泛关注。NSGA-II算法是一种经典的多目标优化算法,通过遗传算法的思想和非支配排序的策略,能够有效地寻找出多个非劣解,并提供问题的整体解集。该算法具有较好的性能和鲁棒性,在解决多目标优化问题方面取得了显著的成果。然而,目前仍存在一些挑战和待解决的问题。首先,尽管NSGA-II算法在解决多目标优化问题方面得到了广泛应用,但在实际的应用中其收敛速度较慢,需要大量的迭代才能收敛到最优解。这给求解大规模复杂问题带来了一定的困难。其次,算法的参数设置对NSGA-II的性能和效果有着重要影响。例如,交叉概率、变异概率和种群大小等参数的选择对算法的结果和执行效率有着显著影响,然而如何确定最佳的参数配置仍然是一个待解决的问题。此外,多目标问题中常常伴随着一系列约束条件,如资源限制、约束关系等。然而,NSGA-II算法对约束处理的能力相对较弱,容易生成约束违反的解,这限制了算法在实际应用中的进一步推广。最后,随着问题维度的增加,NSGA-II算法可能面临维度灾难和计算复杂度增加的挑战。如何提高算法的扩展性,使其能够应对更高维度和更复杂的多目标优化问题,仍然需要进一步的研究。因此,本文旨在综述基于NSGA-II算法解决多目标优化实际应用的研究,通过分析现有的文献和研究方法,探讨算法的优点和不足之处,并提出相应的改进策略,以提高算法的性能和应用范围。
1.2. 研究背景
多目标优化是现实生活中诸多问题的核心,如工程设计、资源分配、路径规划等。传统的单目标优化方法往往忽略了多个目标之间的相互影响和权衡,导致得到的解往往只在某一个目标下优秀。因此,为了在多个目标之间达到平衡,需要引入多目标优化算法。
1.3. 相关工作
在多目标优化领域,已经有许多经典算法被提出和应用。例如,混合遗传算法(MOGA)、多目标粒子群优化算法(MOPSO)等。这些算法在不同的问题上取得了一定的成功,但也存在着一些局限性,如缺乏多样性、收敛速度慢等。为了克服这些问题,NSGA-II算法被提出并受到了广泛的关注和应用。
1.4. 目标和意义
本研究旨在基于NSGA-II算法解决多目标优化实际应用问题,具体目标包括:研究如何将NSGA-II算法应用于具体的多目标优化问题,并设计相应的目标函数和约束条件。分析NSGA-II算法在多目标优化中的性能优势,如收敛性、多样性和均衡性。在实际应用场景中针对不同的多目标问题,验证NSGA-II算法的适用性和有效性。
该研究具有以下意义:提供了一种解决多目标优化问题的有效方法,帮助决策者在不同冲突目标之间做出合理决策。探索和分析NSGA-II算法在具体应用中的性能和适用性,为进一步优化和改进算法提供参考。拓展NSGA-II算法在实际应用中的范围,促进其在工程、金融、物流等领域的广泛应用。
1.5. 研究方法 [1]
在本研究中,将使用NSGA-II算法作为主要的多目标优化方法。通过设计适当的目标函数和约束条件,将NSGA-II算法应用于具体的实际应用问题。通过在多目标问题中进行多次迭代和优化,得到一组Pareto最优解集,用于在不同目标之间进行权衡和选择。
1.6. 论文结构
第一部分为绪论,介绍了多目标优化问题的背景和意义,以及NSGA-II算法的研究背景和应用现状。第二部分将介绍本研究所选用的多目标优化实际应用问题,并说明NSGA-II算法在该问题中的应用方法和实验设计。第三部分将详细介绍NSGA-II算法的原理和流程,包括非支配排序、拥挤度距离计算和环境选择等步骤。第四部分则是NSGA-II算法解决多目标优化实际应用问题的简单案列。
2. 多目标优化 [2]
2.1. 单目标优化的缺点
单目标优化的情况下,只有一个目标,任何两解都可以依据单一目标比较其好坏,可以得出没有争议的最优解。但是传统的单目标优化存在着显著的缺陷。
2.1.1. 局部最优解问题
传统的单目标优化通常只关注寻找全局最优解或局部最优解。然而,优化问题往往具有多个局部最优解,而不同问题可能对不同的最优解感兴趣。因此,单目标优化方法可能陷入局部最优解,无法找到更好的解决方案。
2.1.2. 不适应多目标问题
传统的单目标优化方法无法直接处理多目标优化问题。在多目标问题中,我们通常需要在多个冲突的目标之间做出权衡和折衷。而单目标优化方法只能在一个目标上进行优化,忽略了多目标问题的复杂性。
2.1.3. 缺乏灵活性
传统的单目标优化方法通常基于特定的数学模型,需要精确地定义目标函数和约束条件。然而,在现实世界的复杂问题中,目标函数和约束条件往往难以明确定义,甚至是模糊的。这导致传统优化方法无法灵活适应不确定性和复杂性。
2.1.4. 高度依赖领域知识
传统的单目标优化方法通学需要依赖领域专家的知识和经验来指导优化过程。这对于非专业人士或新手来说是一个挑战,因为他们可能不具备足够的专业知识来定义目标函数和选择适当的优化方法。
2.2. 多目标优化的概念
多目标化与传统的单目标优化相对。多目标优化的概念是在某个情景中在需要达到多个目标时,由于容易存在目标间的内在冲突,一个目标的优化是以其他目标劣化为代价,因此很难出现唯一最优解,取而代之的是在他们中间做出协调和折衷处理,使总体的目标尽可能的达到最优。如下问题
不失一般性,考虑如下区间多目标最大化问题:
(1.1)
式中,x为n维决策变量;S为x的决策空间;
为第i个含有区间参数的目标函数;
为区间向量参数;
为
的第k个分量;
和
分别
的下限和上限。由于目标函数含有区间参数,因此,问题(1.1)的各目标函数值均为区间,并记
。
特别地,当所有参数均为确定数值时,问题(1.1)退化为确定型多目标优化问题,其数学模型为
(1.2)
由于这些目标函数之间往往相互冲突,因此,基于某一目标函数得到的优化结果意味着至少一个其他目标函数的性能将会下降。由此不难想象,对于多目标优化问题,不存在一个使每个目标函数都达到最优的解,而只可能存在一个权衡所有目标函数的最优解集。下面针对式(1.2)描述的多目标优化问题,给出几个重要的概念
定义1.3 设x1和x2是同题(1.1)的两个解,即
,且
,
1) 如果对于所有目标函数,x1不比x2差,即
,
,且至少存在一个目标函数,使得x1比x2好,即
,
,那会,称x1 Pareto占优x2,记为
。
2) 如果x1既不Pareto占优x2,x2也不Pareto占优x1,那么,称x1与x2互不Pareto占优,记为
。
定义1.4 如果对
,不存在
,使得
,那么,称
为问题(1.2)的Pareto最优解(或优化解、非被占优解)。
定义1.5 所有Pareto最优解构成的集合称为问题(1.2)的Pareto最优解集,记为
。
定义1.6 所有Pareto最优解对应的目标函数值在目标空间形成的曲面或超体称为Pareto前沿。
2.3. 传统多目标优化方法
2.3.1. 线性规划
将多目标按权重线性组合转化为单目标,解集由权重的变化产生。
2.3.2. 折衷规划
综合优化兼顾各个目标的性能要求,根据各个单目标的理想点评估,得到最接近理想点的非支配解。
2.3.3. ε-约束
从所有的k个目标中选择一个作为优化的目标,剩余的(k – 1)个目标则通过加界限的方式转化为约束条件。对于最小化的目标,加入上界作为限制条件,对于最大化的目标则加入下界作为限制条件。
2.4. 进化算法求解多目标问题
2.4.1. 遗传算法GA
遗传算法(Genetic Algorithm是受自然进化理论启发的一系列搜索算法。通过模仿自然选择和繁殖的过程,遗传算法可以为涉及搜索,优化和学习的各种问题提供高质量的解决方案。
遗传算法具有以下概念:基因型(Genotype)、种群(Population)、适应度数(又称标数) (Fitness function)、遗传算子(选择(Selection)、交叉(Crossover)、变异(Mutation))。
2.4.2. 粒子群算法PSO
粒子群优化算法(Partice Swar Optimization是一种源于对鸟群捕食行为的研究而发明的进化计算技术,具有全局最优解和局部最优解,是基于群体协作的迭代优化算法。
PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解,在每一次迭代中,粒子通过跟踪两个“极值”来更新自己。第一个就是粒子本身所找到的最优解,这个解叫做个体极值gBest,另一个极值是整个种群找到的最优解,这个极值是全局极值gBest。另外也可以不用整个种群而只是用其中一部分最优粒子的邻居,那么在所有邻居中的极值就是局部极值。
2.4.3. 模拟退火SA
模拟退火算法来源于固体退火原理,是一种基于概率的算法,将固体加温至充分高,再让其徐徐冷却,加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每人温度都达到平衡态,最后在常温时达到基态,内能减为最小。
2.4.4. 混合遗传算法MOGA
多目标遗传算法(MOGA)是解决多个目标决策问题的遗传算法,同时考虑多个目标函数的优化,并通过适应度分配方法来选择适应度较好的个体。在工业中的应用有用α-stable分布生成随机数对PSO算法的种群进行变异后的ASMOPSO算法应用到RAE2822跨音速翼型的减阻和力矩绝对值不增大的综合优化中,得到了较好的多目标气动优化结果。
2.4.5. 多目标粒子群优化算法MOPSO
多目标粒子群Q (MOPSO)算法是由Carlos A Coelo Coello等人在2004年提出,目的是将原来只能用在单目标上的粒子群算法(PSO)应用于多目标上。在工业上用处有基于混合NSGA II-MOPSO算法的热电联合经济排放调度,经济调度问题旨在找到发电机的最佳时间表,以最大限度地降低受功率平衡约束和其他运行约束的发电燃料成本。ED的公式可以经济地运行电力系统。为了同时最大限度地降低发电厂的燃料成本和排放,提出了一个生物喷射CEED问题。这些目标不仅提供了可观的经济效益,而且减少了污染气体的有害影响。可以使用多目标算法并获得帕累托最优(PO)解或权衡解,因为不可能获得满足冲突目标的唯一最优解。
3. 遗传算法–NSAG算法–NSGA-II算法
3.1. 遗传算法
遗传算法基本理论及概念 [3]
1962年,John Holland在Outline for a Logic Theory of Adaptive Systems一文中提出所谓监控程序的概念,即利用群体优化模拟适应新系统的思想,并且引进了群体、适应值、选择、交叉和变异等。1966年,Fogel等也提出来类似的思想,但其重点是放在变异算子而不是交叉算子。1967年,Holland的学生J. D. Bagley通过对跳棋游戏参数的研究,在其博士论文中首次提出“遗传算法(genetic algorithm, GA)”一词。1975年之后,遗传算法作为函数优化器不但在各个领域得到广泛应用,而且还丰富和发展了若干遗传算法的基本理论,其与传统的启发式优化搜索算法(爬上法、模拟退火法等)相比,遗传算法的主要本质特征在于群体搜索策略和简单的遗传算子。群体搜索使遗传算法得以突破领域搜索的限制,可以实现整个解空间上的分布式信息采集和搜索;遗传算子仅仅利用适应值度量作为运算指标进行随机操作,降低了一般启发式算法在搜索过程中对人机交互的依赖。在优化理论中,采取迭代算法求解一个特定问题,若该诉法的搜索过程所产生的解或函数的序列的极限值是该问题的全局最优解,则该算法是收敛的,遗传算法的基础理论主要以收敛性分析为主,即遗传算法的随机模型理论和进化动力学理论。
3.2. NSGA算法
3.2.1. NSGA算法原理
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
在选择操作执行之前,种群根据个体之间的支配与非支配关系进行排序:
首先,找出该种群中的所有非支配个体,并赋予他们一个共享的虚拟适应度值。得到第一个非支配最优层;
然后,忽略这组己分层的个体,对种群中的其它个体继续按照支配与非支配关系进行分层,并赋予它们一个新的虚拟适应度值,该值要小于上一层的值,对剩下的个体继续上述操作,直到种群中的所有个体都被分层。
算法根据适应度共享对虚拟适应值重新指定:
比如指定第一层个体的虚拟适应值为1,第二层个体的虚拟适应值应该相应减少,可取为0.9,依此类推。这样,可使虚拟适应值规范化。保持优良个体适应度的优势,以获得更多的复制机会,同时也维持了种群的多样性。
3.2.2. NSGA算法的不足
NSGA通过基于非支配排序的方法保留了种群中的优良个体,并且利用适应度共享函数保持了群体的多样性,取得了非常良好的效果。但实际工程领域中发现NSGA算法存在明显不足,这主要体现在如下3个方面:
1) 计算复杂度较高,为O (mN3) (m为目标函数个数,N为种群大小),所以当种群较大时,计算相当耗时;
2) 没有精英策略;精英策略可以加速算法的执行速度,而且也能在一定程度上确保已经找到的满意解不被丢失;
3) 需要指定共享半径
。
3.3. NSGA-II算法
3.3.1. Pareto支配与Pareto前沿
支配:由于多个目标函数的存在、对于可行解(满足优化条件的解),无法利用传统的大小关系比较进行优劣关系比较和排序,定义多目标情况下的个体间关系。
Pareto支配:又称Pareto占优,对于两个可行解11和2,对所有目标而言,11均优于12,则我们称11支配12。
在多目标优化问题中,我们通常会面临多个冲突的目标,而Pareto前沿则表示了在给定问题下,无法进一步改善一个目标而不牺牲其他目标的解集合。换句话说,Pareto前沿是一组最优解,其中任何解都不可被改进而不降低其他目标的值。Pareto最优解经目标函数映射构成了该优化问题的Pareto前沿,见图1。
Pareto前沿的计算通常涉及使用多目标优化算法,例如进化算法或遗传算法。这些算法通过遗传、变异和选择等操作来生成一系列解,并使用Pareto支配关系(Pareto dominance)来判断解的优劣。通过迭代搜索过程,算法可以逐步逼近Pareto前沿,找到一组近似最优解。
3.3.2. NSGA-II算法的提出
为了克服非支配排序遗传算法(NSGA)的上述不足,印度科学家Deb于2002年在NSGA算法的基础上进行了改进,提出了带精英策略的非支配排序遗传算法(Elitist Non-Dominated Sorting Genetic Algorithm, NSGA-II),NSGA-II算法针对NSGA的缺陷通过以下三个方面进行了改进:
1) 提出了快速非支配排序法,降低了算法的计算复杂度。由原来的O (mN3)降到O (mN2),其中,m为目标函数个数,N为种群大小。
2) 提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
3) 引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
精英策略即保留父代(上代),然后让父代和经过选择、交叉、变异后产生的子代共同组成一个群体,其目的就是为了防止父代中可能存在的最优解被遗落,最后经过再次选择操作,获得与初始种群同样规模的群落。
3.3.3. NSGA-II算法的基本原理
1. 非支配排序算法
通过非支配排序算法对规模为n的种群进行分层,具体步骤如下:
1) 设i = 1;
2) 对于所有的
,且
,按照以上定义,比较个体
和个体
之间的支配与非支配关系;
3) 如果不存在任何一个个体
优于
,则
标记为非支配个体;
4) 令i = i + 1,转到步骤(2),直到找到所有的非支配个体。
通过上述步骤得到的非支配个体集是种群的第一级非支配层,然后,忽略这些已经标记的非支配个体(即这些个体不再进行下一轮比较),再遵循步骤(1)~(4),就会得到第二级非支配层。依此类推,直到整个种群被分层。而NSGA-II的快速非支配排序,降低了计算的复杂度。
传统NSGA-II算法虽然在非支配解排序的效率上比NSGA有较大提高,但是对于规模大、目标较多的调度问题,NSAG-II算法仍需要花费较多时间。本文采用基于改进非支配排序遗传算法的多目标柔性作业车间调度 [2] 中提出的快速排序方法构造非支配集,该方法在进化个体之间定义一种新的关系:
,如果
或X和Y不相关,则
。快速排序方法每次找一个个体X作为比较对象,按照关系“
”进行比较判断,经过一趟排序后,以X为中界将P中的个体分成两部分,比X小的一部分肯定是被支配个体;第二部分是比X小的个体或与X不相关的个体,然后对第二部分进行下一轮排序,直至第二部分只有一个个体。快速排序算法的平均时间复杂度小于O (rnlgn),比NSGA-II的O (rN2)具有更高的运行效率。
2. 采用拥挤度和拥挤度比较算子
1) 拥挤度估计:为了得到种群中特定解周围的解的拥挤度估计,我们根据每一目标函数计算这点两侧的两个点的平均距离。这个数值作为以最近邻居作为顶点的长方体周长的估计(称为拥挤系数)。在下图中,第i个解在它所在前沿面的拥挤系数是它周围长方体的长度(如虚线框所示),拥挤度的计算保证种群多样性。(拥挤度算子见图2)
拥挤系数的计算需要根据每一目标函数值的大小的升序顺序对种群进行排序(即假如得到第一级非支配层,则对其按照目标函数的大小进行排序,然后计算拥挤度)。因此,对每一目标函数,边界解(拥有最大和最小值的解)被指定为无穷大距离的值。所有其它中间的解都被指定为等于两个相邻解的函数值归一化后的绝对差值。计算方法对其它目标函数也是这样。全部拥挤系数值是通过个体每一目标的距离值的加和计算得到的,每一目标函数在计算拥挤系数前都会进过归一化处理。
2) 拥挤比较算子
经过前面的快速非支配排序和拥挤度计算之后,种群中的每个个体i都拥有两个属性:非支配排序决定的非支配序irank (级数,即第几级)和拥挤度id依据这两个属性,可以定义拥挤度比较算子:个体i与另一个个体j进行比较,只要下面任意一个条件成立,则个体i获胜。(拥挤度比较算子见图3)
3. 精英策略
首先将第t代产生的新种群Qt与父代Pt合并组成Rt,种群大小为2N。然后Rt进行非支配排序,产生一系列非支配集Zi并计算拥挤度。由于子代和父代个体都包含在Rt中,则经过非支配排序以后的非支配集Z1中包含的个体是Rt中最好的,所以先将Z1放入新的父代种群Pt+1中。如果的大小小于N,则继续向Pt+1中填充下一级非支配集Z2,直到添加Z3时,种群的大小超出N,对Z3中的个体使用拥挤度比较算子,使Pt+1个体数量达到N。然后通过遗传算子(选择、交叉、变异)产生新的子代种群Qt+1,见图4。
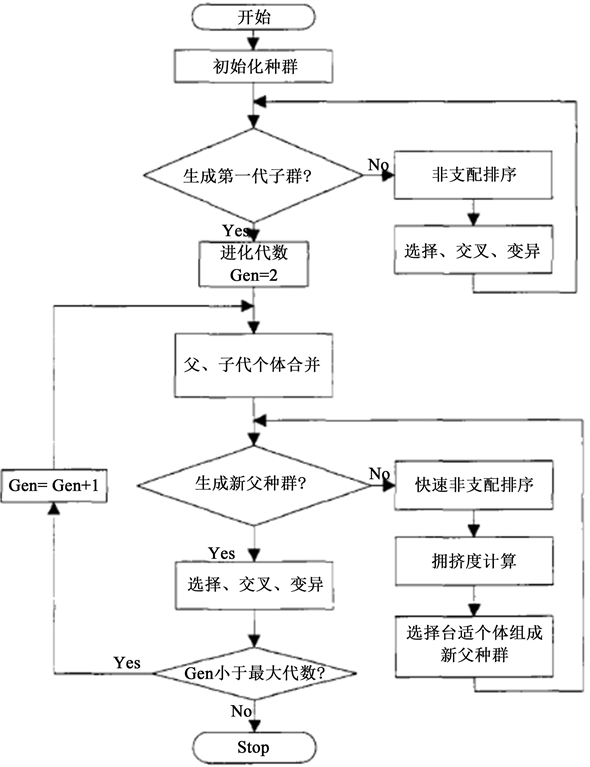
Figure 4. Flow chart of NSGA-II algorithm
图4. NSGA-II算法的流程图
4. NSGA-II算法解决多目标优化实际应用问题的简单案列
4.1. 案例背景
在工业生产中经常会出现既要能耗低又要利润高的情形,这时普通的单目标优化无法或难以在满足约束条件的可行解中找出最优解,这时我们采用多目标优化的方法,能够较为轻易解决此类问题的简单应用。下面将具体展示基于NSGA-II算法解决实际多目标优化问题的简单应用。
4.2. 问题描述
工厂共有工人300名,生产A、B、C、D四种化工原料。每人每周平均生产时间在40~48小时内。C为国防用产品,每周至少生产150公斤,而每周至多可提供能源20吨标准煤。
其他数据见表1:

Table 1. Standard experimental system results data
表1. 标准试验系统结果数据
如何安排每周的生产,才能使纯利润最高,而能耗最少,试建立数学模型并求解。
4.3. 建立模型 [4]
目标函数:
约束条件
x1是A化工原料的生产量
x2是B化工原料的生产量
x3是C化工原料的生产量
x4是D化工原料的生产量
f1函数是代表总利润,f2函数代表总能耗
4.4. 运行求解
1) 初次运行结果:见图5
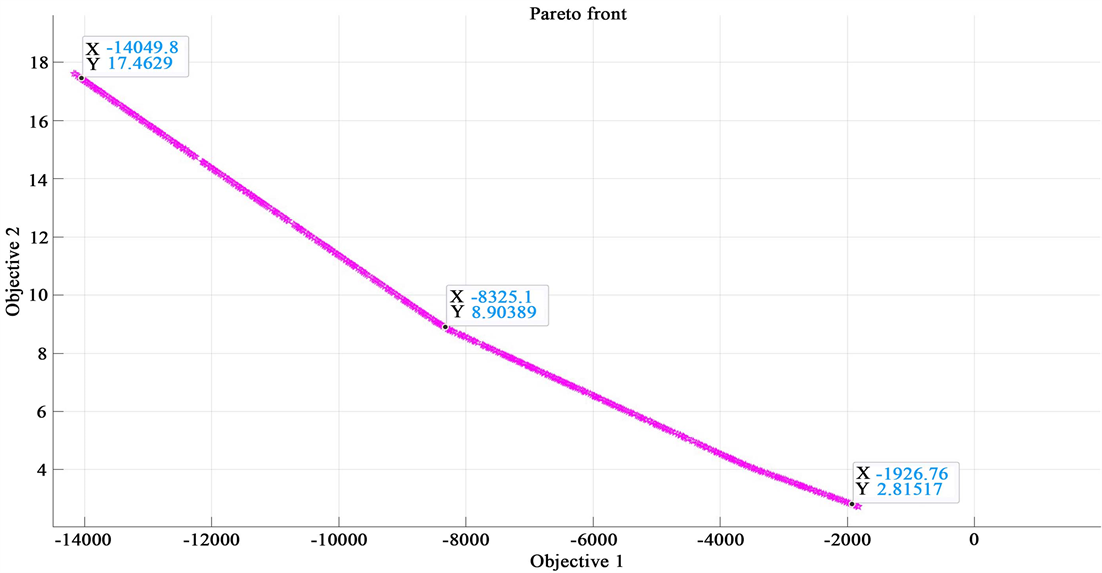
Figure 5. Pareto front overall results
图5. Pareto前沿整体结果
2) 决策过程
a) 如果需要我们的总利润相对大一些,且不太需要考虑能耗的问题时,靠近目标函数2可以找到此时符合条件的可行解,并且使得最后的总利润相对较高且能耗也较高。见图6:
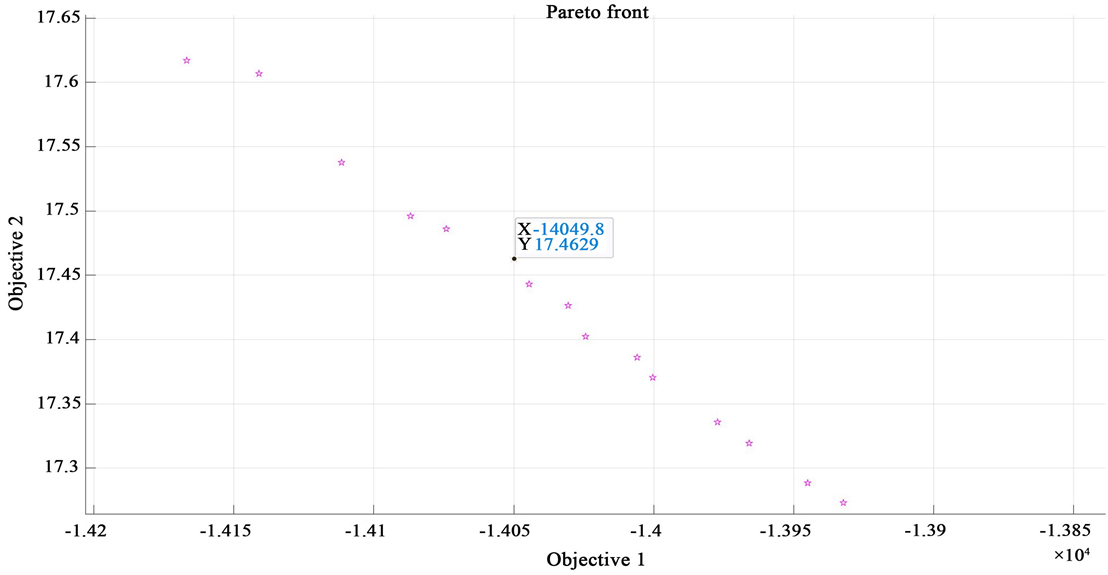 Pareto最优解:−14049.8 17.4629对应的方案:A:217.848808842778 B:235.918038136872 C:449.931246046659 D:125.273054314774
Pareto最优解:−14049.8 17.4629对应的方案:A:217.848808842778 B:235.918038136872 C:449.931246046659 D:125.273054314774
Figure 6. Pareto front results close to the objective function 2 part
图6. 靠近目标函数2部分pareto前沿结果
b) 如果我们需要能耗相对低一些时,且暂时忽略能耗降低所带来利润下降的影响时,靠近目标函数1可以找到符合条件的,可行解并且使得此时的能耗较低,但利润相比也有所降低,见图7:
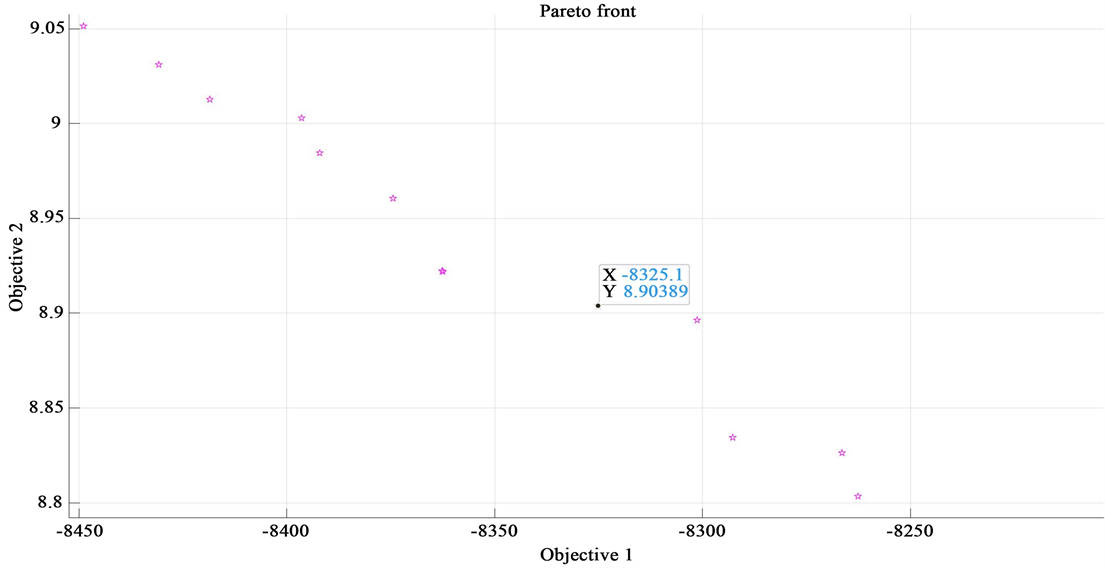 Pareto最优解:−8325.1 8.90389对应的方案:A:4.80387855791507 B:234.040722992458 C:154.629500221295 D:124.335077943723
Pareto最优解:−8325.1 8.90389对应的方案:A:4.80387855791507 B:234.040722992458 C:154.629500221295 D:124.335077943723
Figure 7. Relatively balanced partial Pareto front results
图7. 相对平衡部分Pareto前沿结果
c) 如果需要在能耗达到一个相对较小的情况下,总利润也能相对合适的方案,在整个图像的中间部分,此时的可行解满足能耗相对较低但利润也较为可观的程度,见图8:
 Pareto最优解:−1923.76 2.81517对应的方案:A:0.0448202947279866 B:2.17427741804580 C:150.693175496264 D:5.32171491812089
Pareto最优解:−1923.76 2.81517对应的方案:A:0.0448202947279866 B:2.17427741804580 C:150.693175496264 D:5.32171491812089
Figure 8. Pareto front results close to the objective function 1 part
图8. 靠近目标函数1部分Pareto前沿结果
5. 总结
本文研究了基于NSGA-II算法(Non-dominated Sorting Genetic Algorithm II)来解决多目标优化问题的实际应用。NSGA-II是一种经典的多目标优化算法,它基于遗传算法的思想进行设计,并通过非支配排序和拥挤度计算来维持优势解的多样性和均匀分布性。本文主要介绍了传统的NSGA-II算法,在本文的第四部分,给出了用NSGA-II算法实际操作解决工业生产上多目标优化问题的典型案列,本文给出的NSGA-II算法与传统的NSGA-II算法差距并不大,但在具体操作步骤上做了简化,对于维数较低的多目标优化问题(目标函数个数低于5)采用本文所给出的NSGA-II算法能够较为轻易地获得Pareto前沿的结果。缺点:本文给出的NSGA-II算法对于高维的优化问题通常难以获得效果较好的Pareto前沿结果,而对于低维的优化问题,能够得到的Pareto前沿结果较好,但所得结果的目标点通常较多,对于具体的目标点的选取,文本并没有做更深层次的讨论,通常需要花费一部分的时间进行比较选取。
基金项目
北京市级大学生创业训练计划课题(10805136023XN262-289)。