1. 引言
知识库是存储知识的数据库,存储包含规则联系的事实的数据,知识库有多种表现的方式,知识图谱就是使用最广泛的一种知识库。问答是自然语言处理中的重要任务,它的目的是回答由人提出的自然语言问题,知识库问答 [1] 就是指通过检索储存在知识库中的三元组来获取问题的答案实体,来返回问题的真实答案的一种问答方法。而在基于知识库的问答中,如何精准检索到和问题匹配的正确答案是问答任务的关键。知识库问答按照检索信息的难易程度进行分类,可以分为简单问题和复杂问题。
简单问题是结构简单的问题,比如“叔本华信仰什么宗教?”这种只需要在知识库中只进行一次检索就可以的到答案的问题。复杂问题是指多跳和多约束问题,多跳问题在知识库中搜索时通过多步检索得到答案。例如,“请回答《西风颂》作者的主要成就”,这个问题首先要找出问题中的实体“西风颂”,然后再知识库中搜索与问题相关的包含《西风颂》的三元组(珀西·比希·雪莱,代表作品,西风颂),确定与“《西风颂》作者”对应的实体“珀西·比希·雪莱”,再在知识库中寻找到与“珀西·比希·雪莱”相关的三元组(珀西·比希·雪莱,主要成就,创作大量浪漫主义诗歌)从而获取到《西风颂》作者的主要成就为“创作大量浪漫主义诗歌”。复杂问题的示例图如图1所示。
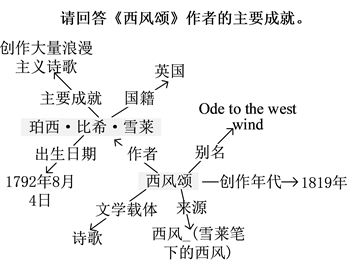
Figure 1. Example of complex problem query
图1. 复杂问题查询实例
现在知识库问答的解决方法主要的有两种,Lan等人 [2] 的综述中总结了复杂知识库问答方法,重点归纳了基于语义解析和基于信息检索的方法。前者将问句解析成为由实体和关系构成的语法树,然后用语法树生成语句查询知识库,然而这种严重依赖于中间逻辑形式(如SPARQL)的昂贵注释。后一种方法不解析问题,而是直接表示实体,并根据它们与输入问题的相关性对其进行排序。其中,首先检索与问题相关的路径,然后对其进行缩小。路径检索对于问答系统的性能至关重要,因为短的路径极有可能排除答案,而过长的路径则可能引入影响问答系统性能的噪声 [3] 。
基于信息检索的知识库问答方法首先要通过命名实体识别得到问句中的实体与候选实体,然后在知识库中进行若干次检索获得与包含答案的候选路径,再计算自然语言问题与候选路径之间的语义相似度、Jaccard距离等元素,然后使用逻辑回归模型对候选路径进行排序,找出候选路径中最优的路径,输出答案。因为基于信息检索的方法更方便寻找答案,在逻辑理解与构造数据集方面也较为简单,所以获得了更多的探寻。然而基于信息检索的方法在根据实体和候选实体检索知识库的这个过程中,路径数目会随跳数增加而呈指数级增长,引入更多噪声,使问答系统变得繁冗,也导致了正确率的降低。
为了避免引入更多噪声,提高正确率,本文提出了一个基于对比学习的语义联合模型框架,将实体消歧和关系匹配整合到一个统一的框架中,利用实体所连接的关系信息,同时完成实体消歧和关系匹配任务,防止误差传播,最大可能减少错误路径和无关路径,解决复杂问题,提高系统整体性能。
2. 基于语义联合的知识库问答方法
开放域知识图谱问答一般有三个模块,实体识别、实体消歧和关系匹配。在实体识别模块中,计算机会识别出问题中的实体提及。但是自然语言疑问句中的实体提及通常可能含有多个意思,实体存在的缩写、别名、嵌套以及问句与知识库中结构化语义之间的差距,例如“苹果”可能是水果,也可能是手机,在这种情况下就需要通过实体消歧来找到知识库中准确对应的实体。用户问句的意图通常具有不同的表现形式,关系匹配任务用于匹配问句意图和知识图谱中相近的关系。但是大多数研究都将实体消歧和关系匹配视为独立子任务导致误差传递,使得整体系统准确率不佳。
本文构建基于对比学习的实体消歧关系匹配任务联合框架如图2所示,将实体消歧与关系匹配统一建模联合,减少传递误差,提高相似度计算准确率。在得到问句中识别的实体提及,在Neo4j图数据库中进行模糊匹配,得到候选集合,用mention2id词典对其进行过滤,然后使用语义联合模型控制路径扩展,最大可能减少错误路径和无关路径,降低噪声,提高系统整体性能。
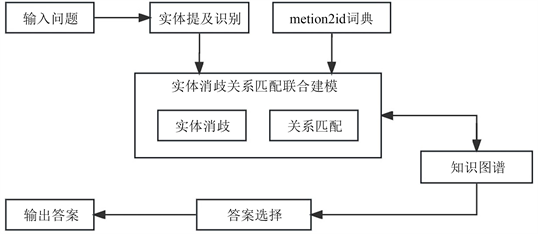
Figure 2. Semantic-based knowledge base question answering approach
图2. 基于语义联合的知识库问答方法
2.1. 实体命名识别
命名实体识别 [4] 是为了找到自然语言问题q中实体,常用的实体识别方法是基于模型的方法。常用的实体识别模型为序列标注模型,可以给自然语言中的每个词映射最优的标签序列。
BERT是一种双向的Transformers模型,通过掩码机制进行预训练,取代了传统的单向语言模型或对单向语言模型进行浅层拼接的方法。在文本建模方面,BERT利用基于注意力机制的方法,使输入序列中的每个词都能够关注到其他词,从而更好地实现对语义层面的理解。通过双向编码的机制,BERT能够更好地将词的上下文信息融合到词向量中,使得词向量的表示更加准确。
本文尝试利用BERT-BiLSTM-CRF模型 [5] 对问题中实体指称的起点位置及终点位置进行预测,寻找问句中的实体。BERT-BiLSTM-CRF模型结构如图3所示,主要由BERT层、BiLSTM双向长短期记忆网络,CRF条件随机场三层组成。
在BERT-BiLSTM-CRF模型中输入问问句后,通过BERT模型获得问句相应的字向量表示,然后将字向量输入到双向长短期记忆网络进行对字向量的双向编码;最后用CRF条件随机场进行特征解码,将自然语言问句映射得到最优的标签序列,从而完成对整个问题命名实体识别的流程。

Figure 3. BERT-BiLSTM-CRF model architecture
图3. BERT-BiLSTM-CRF模型结构
2.2. 对比学习模型
2.2.1. Sentence-BERT模型
Sentence-BERT [6] 使用基于BERT模型 [7] 孪生网络结构来获得两个句子的词向量表示,然后对其进行预训练以建立相似度模型。使用BERT模型进行相似度计算会消耗很长的时间进行语义相似性的搜索,而且句子表示不适合无监督的任务,Sentence-BERT减小Bert语义搜索的巨大耗时,使其适用于句子相似度计算。
在Sentence-BERT模型的预训练阶段,首先使用BERT的孪生网络获取句子的向量表示。这意味着将两个句子输入到两个共享参数的BERT模型中,得到这两个句子的词向量表示。然后,在句子长度的维度上对所有词向量求平均值。这一步骤是将BERT输出的词向量输入到池化层进行平均池化操作,以获得两个句子的句向量表示。最后,使用余弦相似度公式计算词向量U和V之间的相似度,从而计算出两个句子之间的相似度。Sentence-BERT模型的结构如图4所示。
我们使用Sentence A和Sentence B的特征向量作为孪生网络模型的输入,输出两个句子的词向量进入Pooling层进行平均池化,得到句子的向量表示xi,yi,然后采用余弦相似度来计算问题Sentence A和Sentence B的相关度得分如式(1)。
(1)

Figure 4. Sentence-BERT model architecture
图4. Sentence-BERT模型结构
评价本文问题和实体属性相关度的准确标准使用的指标是估计距离
与真是距离θ的距离的函数,最常用的函数是距离的平方,但是因为估计距离
具有随机性,所以求该函数的期望值,公式如(2)给出了均方误差公式。在训练模型的过程中,我们使用最小化均方误差作为损失函数来训练相似度模型。
(2)
2.2.2. ConSERT模型
ConSERT [8] (Contrastive Framework for Self-Supervised Sentence Representation Transfer)是一种基于对比学习的句子表示迁移方法,旨在通过使用共享参数的BERT模型对两个句子进行向量表示来获得更具区分性的语义向量表示。该模型通过引入对比学习的思想,在训练过程中通过比较同一句子的不同增强样本之间的相似性以及不同句子之间的差异性,进一步提升语义表示的质量。与Sentence-BERT相似,ConSERT采用了共享参数的BERT模型架构,但利用对比学习的思想对模型进行了进一步训练,以获得更加区分度的语义向量表示。这种对比学习的方法能够生成更具区分性的句子表示,从而在各种自然语言处理任务中取得更好的性能。通过对比学习,ConSERT能够在无监督的自我训练过程中学习到更具语义区分度的句子表示,从而提高了句子表示的迁移能力和表达能力。这使得ConSERT成为一个有效的句子表示迁移方法,可在多种自然语言处理任务中发挥作用,如文本分类、语义匹配等。
ConSERT模型的结构如图5所示,由三个主要部分组成:共享参数的BERT模型层、对比损失层和数据增强模块。在每个批次中,有N个输入文本,数据增强模块采用不同的方法生成两个增强样本。这两个增强样本经过共享参数的BERT模型层进行向量表示,然后通过平均池化映射到相同的维度上,并在对比损失层计算对比损失。损失函数是通过计算两个句子之间的余弦相似度来度量它们的相似性。对比损失层的目标是最大化正样本的相似度,并将负样本的相似度最小化,以增强语义表示的区分度。通过这种对比学习的训练方式,ConSERT能够生成更具区分性的语义向量表示,从而在各种自然语言处理任务中获得更好的性能。损失函数如式(3)所示:
(3)
其中sim(∙)函数为余弦相似度函数,1为指示函数,r为句子对的向量表示,
为温度超参,设置为0.1,最终的对比损失是通过平均批次内的所有损失计算得到的。对比损失函数的目标是拉近相似句子,拉远不相似句子。通过找到每个样本的增强样本,并计算它们之间的相似度,以及将其他样本作为负样本,可以提高语义表示的区分度。最终的对比损失是批次内所有样本损失的平均值。
上述为在无监督情况下的对比损失,ConSERT在有监督的情况下,采取损失融合和的方式进行,将有监督数据视为分类任务数据,并结合对比损失进行训练,式(4)和式(5)为分类损失函数:
(4)
(5)
其分类损失使用交叉熵损失函数,r1,r2为句子向量表示,并且和
拼接起来,α作为对比损失的平衡参数。
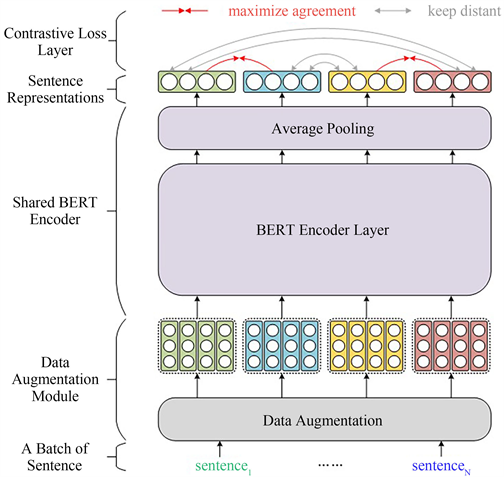
Figure 5. ConSERT model architecture
图5. ConSERT模型结构
2.2.3. CoSENT模型
CoSENT [9] (Cosine Sentence)模型使用两个参数共享的BERT构成孪生网络,和Sentence-BERT模型结构相同,对于输入句子U和V,输出它们各自的语义向量,然后进行池化操作,最后使用余弦相似度函数进行相似度计算。CoSENT使用对比学习的方式是针对一对句子而不是一个句子对比。具体来说,CoSENT模型在训练阶段,记h+为所有的正样本对集合,h−为所有的负样本对集合,对于任意的正样本对
和负样本对
,都有:
(6)
其中
分别为
的句向量表示。CoSENT模型使用对比损失优化句子对的余弦相似度替换 Sentence-BERT的训练任务,获得了句子更有区分度的语义向量,其损失函数如公式(7)所示:
(7)
其中λ是一个大于0的超参数,后续实验取为20。该损失函数可以再训练过程中,将语义相似的句子对在向量空间中的表示拉进,不相似的句子对远离,来得到更有区分度的句子向量表示。
2.3. 基于对比学习的语义联合模型
在先执行实体消歧任务再执行关系匹配任务的过程中,会导致误差的传递,如果实体消歧模型选出的实体就已经偏离了问句,那么关系匹配模型将无法正确找到关系,进而无法在知识图谱中找到正确的答案。同时,在这种情况下,实体消歧过程中无法利用关系匹配阶段的信息,如有些候选实体根本没有正确的关系,而实体消歧任务中仍然可能会选择这个候选实体,最终导致结果错误。因此本文用出了语义联合建模框架来完成实体消歧关系匹配联合任务,其直接计算候选集合路径和问句之间的语义相似度。

Figure 6. Framework diagram of a contrastive learning-based semantic fusion model
图6. 基于对比学习的语义联合模型的框架图
图6为基于对比学习的语义联合模型的框架图,其使用对比学习的方法来学习问题以及候选集合的语义向量表示,使其更容易区分开来,并将实体消歧和关系匹配统一建模联合完成,以避免误差传递。首先将候选实体集
中的每一个候选实体ei和其所连关系集
通过一个特殊的[AND]标识符进行连接,构成候选集合集
。其次将问句Q和候选集合集C输入进共享参数的BERT层,得到它们的向量表示。然后将这些向量分别输入进池化层以获得固定大小的句子嵌入,其表示为:
(8)
(9)
其中池化层默认使用平均池化策略。最后使用余弦相似度函数计算他们的相似度:
(10)
其中
为问句与候选集合的相似度得分集合。直观地说,一些候选关系可以提供一些语义信息给实体消歧。如果知道问句中的关系,就可以通过其提供的语义信息排除一些候选实体。例如,问句“水浒传有多少集?”包含词语“多少集”对应的关系“集数”。为了实体消歧,有理由将注意力集中在连接有“集数”的候选实体上,例如“水浒传(电视剧)”而不是“水浒传(小说)”。因此,本章构建了一个语义联合模型来同时进行实体消歧和关系匹配。
2.4. 知识库问答的实现
在知识库查以基于信息检索的方式查询一个问题,返回包含问题答案的候选路径。在多跳问答中,若是跳数多于或者少于可以找到问题答案的真实跳数,则会引入影响问答系统性能的噪声,并且考虑到大多数复杂问题可以在两条内解决,为了减少候选路径的规模,去除大量与问题无关的路径,因此本文只选择两跳的扩展路径,并在这个过程中加入语义联合模型,通过计算问题与路径的相似度对路径每一跳质量评估,保留高质量路径。
对于问句中的主题实体集合Etopic中的实体e,如问句“白鹿原的作者出生地在哪儿”,检索问句的实体“白鹿原”,得到实体属性为“作者”、“出版社”、“总策划”和“导演”等属性,然后计算问题与每个候选属性的语义相似度,自然排除了与问题无关的实体属性与包含这些属性的路径,得到(白鹿原,作者,陈忠实),然后根据第一跳得到的属性“陈忠实”检索,得到与“陈忠实”有关的属性“国籍”、“民族”、“出生地”和“出生日期”等,再次计算实体属性与问题的相关度,得到(陈忠实,出生地,陕西),最终得到问题的答案“白鹿原的作者出生地在陕西”。
因为在根据“白鹿原”扩展路径时,第二跳可能会出现(俯仰关中,作者,陈忠实)这种情况,也有可能在第一跳中出现实体关系与正确无关的情况,所以在路径扩展中方式如图7。
(1) 对于单实体问题的答案路径:在第一跳中,首先通过问句中识别的实体提及,在Neo4j图数据库中进行模糊匹配,得到候选集合,之后使用mention2id词典对其进行过滤,只保留词典实体提及对应的候选实体及其关系,使用联合语义建模框架计算问句Q和实体–关系对的语义相似度,选取排名前n的候选路径集合C;得到第一跳的候选集合中实体提及对应属性以后,根据属性在Neo4j图数据库中进行精确匹配,计算问句Q和实体–关系–关系对的语义相似度,选取排名前n的实体–关系–关系对加入候选路径集合C。
(2) 对于两个实体问题的答案路径:首先查询多实体之间相似的关系,构成候选路径集合C;若无相似关系,每个实体提及进行第一跳,如果有相同属性则合并,加入候选路径集合C;若第一跳有相同属性,则将属性作为实体在Neo4j图数据库精确匹配,计算语义相似度,排名前n则加入候选理解集合C;若第一跳无相同属性,则联合语义建模框架计算问句Q与两对实体–关系对的语义相似度,选取排名前n关系对一一进行第二跳,合并两个实体–关系–关系对和两个实体–关系,不能合并则舍弃。
(3) 对于多实体问题的答案路径:首先查询多实体之间相似的关系,构成候选路径集合C;然后第一跳,对多实体相似的关系进行扩展,合并想同的属性,计算多实体–关系对于问题Q的相似度,排名前n加入候选路径集合C。
在得到所有的候选路径集合C后,使用语义联合建模框架计算问题Q与候选路径集合C的语义相似度,选取排名最高的路径最为最终路径,在Neo4j图数据库中匹配最终答案。
3. 实验
3.1. 数据集分析
本文使用了PKUBASE大规模开放域知识库,在CCKS2019KBQA数据集上进行测试,其中,训练集有2298条,验证集有766条,测试集有766条,简单问题和复杂问题的比例为1:1。一条完整的问答数据包括问题、SPARQL查询语句和问题的答案,如表1为一条问答数据的示例。
本文使用的PKUBASE知识库包含了三个文件,分别是知识库的三元组,有41,009,141条数据;实体类型,有25,182,627条数据;实体别称,有13,930,117条数据。知识库使用Neo4j图数据进行储存,并提供查询,mention2id词典为数据集所提供,用于辅助开放域问题中主题实体提及映射到知识图谱中的实体上,然后在知识图谱的三元组中根据问题寻找若干个实体或者属性名作为答案。

Table 1. Example of a question-answer data
表1. 一条问答数据的示例
3.2. 实验设置
本实验使用BERT、Sentence-BERT、Con SERT、Co SENT四个模型,实验相关软件及训练环境为Pycharm Community Edition 2020.2.5 x64、Python3.7版本、Tensorflow-gpu 1.14、Pytorch 1.7。
实验使用的所有BERT预训练模型为bert-base-chinese的权重,训练了30个epoch,最大序列长度为64,批次大小为16,学习率为2e-5。
3.3. 实体识别模型效果
本文针对BERT-CRF、BiLSTM-CRF、BERT-BiLSTM-CRF三个实体识别模型训练,实验结果如表2所示,可以看出用BERT-CRF模型在识别问题中的实体提及任务上的效果要优于BiLSTM-CRF模型,BERT-BiLSTM-CRF实现实体命名识别的效果高于另外两个模型。
Table 2. Entity named recognition performance
表2. 实体命名识别效果
3.4. 语义联合模型任务效果
实体消歧关系匹配联合任务中,对各个模型的准确率进行了实验,使用准确率(Accuracy)作为评价指标。联合匹配任务模型效果如表3所示,实体消歧关系匹配任务的联合模型中候选实体–关系数量较多,实验结果表明和BERT模型相比,对比学习模型能够学习到更深层次的语义信息,在语义联合模型框架中CoSENT模型表现效果最好,但是conSERT模型也有不错的速率。
Table 3. Accuracy of the entity disambiguation and relation matching joint task model
表3. 实体消歧关系匹配联合任务模型准确率
3.5. 问答系统性能评估
本文最终在CCKS2019KBQA数据集上进行测评,评测最终结果采用的评价指标为AverageF1值。本文在识别问题中的实体之后,做以下两个实验:(1) 先做实体消歧然后进行关系匹配的方法作为Pipeline 方法;(2) 将两个子任务联合进行的方式即使用语义联合匹配框架。最终问答结果如表4所示。实验结果表明了将实体消歧关系匹配任务进行联合匹配框架均优于Pipeline方法,证明了该框架在开放域知识图谱问答中的优势性。
Table 4. Evaluation results of the CCKS2019KBQA dataset
表4. CCKS2019KBQA数据集测评任务结果
4. 结论
本文介绍了一种基于语义联合的知识库问答方法,实现了对简单问题和复杂问题的统一处理。系统使用实体消歧关系匹配联合任务模型框架,充分利用实体和关系之间的交互信息,获取更加具有区分度的语义向量表示,提升了问题与路径之间的相关能力,在任务数据集上取得了比先做实体消歧然后进行关系匹配的方法更好的效果,证明了基于对比学习的联合语义建模框架在开放域知识图谱问答中的有效性。
虽然本文的知识库问答方法提高了系统的正确率,但仍然有欠缺之处。为了解决复杂问题,在识别到问句中的实体提及后,在Neo4j图数据库中进行模糊匹配和二次匹配,减少了噪声,但是最终获得的路径还有很多,整个系统依然十分繁冗。因此后续我们会将解决复杂问题的研究重点放在相关子图的推理中,减少答案的候选集合,结合本文的方法计算问题与候选路径集合的相似度,达到简化系统的目的。
基金项目
1) 国家档案局科技计划项目《基于大数据智能驱动的档案信息资源挖掘与共享利用服务研究》的阶段性成果,项目批准编号:2021-X56;2) 甘肃省委办公厅(甘肃省档案局),甘肃省档案科技项目《甘肃省档案信息资源大数据分析及其数据可视化研究与应用》研究成果之一,甘档发[2020]48号GS-2020-X-07,2020-09至2021-09,在研,主持。
参考文献