1. 引言
在复杂网络研究中,社团结构描述了网络内部的一种特殊组织形态,它由节点之间的紧密连接和相似性形成的子图或节点集合组成。这种结构是网络自发形成的,代表了网络中节点的内在关联和互动方式 [1] [2] [3] 。其特点是同一社团内的节点更相似,而不同社团之间则差异较大。很多系统都可以看作是网络,例如社交关系 [4] [5] 、知识图谱 [6] [7] [8] 等。这些网络中呈现出明显的模块化特征和层次化结构,其中社团结构是一个重要的组成部分。如何有效地发现和刻画社团结构,对于深入理解网络本质、揭示系统的规律和特点具有重要意义。
社团划分不仅可以帮助我们了解网络的特征,还能够预测未来网络的演化趋势,发现潜在隐秘节点和关系。社团划分算法的主要任务是将网络节点划分成若干个子社团,以确保社团内部的紧密性和社团之间的分隔性。这一过程旨在揭示网络的内在组织结构,有助于更深入地理解网络的复杂性。社团划分算法可以分为三个主要范畴,包括基于节点相似性的聚类方法、以网络模块度为基础的分析方法,以及运用随机游走策略的方法。这些方法各自侧重不同的网络结构特征和信息挖掘方式,为研究复杂网络中的社团结构提供了多样的工具和角度。同时,随着深度学习技术的飞速发展,神经网络的强大潜力被越来越多地应用于社团划分问题的解决,提供了新的创新方法和技术路径。这些算法借助神经网络的特征学习和表示学习能力,以更深入、更准确的方式来探索网络中的社团结构,为复杂网络研究提供了令人兴奋的前景。
基于聚类的方法依靠节点或社团的位置信息以及他们在网络中的关注度来进行社团结构的划分。Newman利用模块度原理和模块度增量计算,通过逐步合并节点或社团进行社团划分,提出了Fast Newman (FN)算法 [1] 。由Raghavan等人 [9] 提出的标记传播算法(Label Propagation Community Detection Algorithm, LPC),是一种以节点相似性为基础的社团检测算法。该方法的核心思想在于将具有相似特性的节点赋予相同的标签,通过标签在网络中的传播来揭示社团结构。此方法为研究人员提供了一种有力工具,以更全面地理解网络中的社团组织和关联。Zhang等 [10] 提出了一种基于真实连接概念的重叠社团检测方法,它通过预处理原始网络得到“真实连接”图,并利用凝聚式策略不断地合并相似度高的社团,最终形成重叠社团结构。基于模块度(modularity)的方法以一种优化固定的数量的模块度量为目标函数,并尝试将网络分成多个社区,其中每个社区都有高内部连通性和低交叉边数。Blondel等 [11] 提出了Louvain算法。该算法将节点逐步聚类到社区中,并优化整个网络的模块度。Zhe等 [12] 提出了基于贪心策略的最大化模块度算法,利用网络拓扑和属性信息图对网络进行划分,以获得网络的社团结构。该算法能够高效处理大规模复杂网络数据。Zhu等人 [13] 引入了一种创新性的社团检测方法,采用了基于k-plex的策略。该方法的核心思路是通过生成k-plex,将其作为社团的种子,然后运用模块度优化算法来智能分配剩余节点,形成社团结构。基于随机游走的社团发现方法是利用随机游走模拟在网络中漫步而创建的节点序列,对网络结构进行分析和建模来检测社团。Perozzi等人 [14] 在其研究中提出了DeepWalk算法,该算法使用基于随机游走的节点表征策略来生成节点序列,随后应用Skip-gram模型将这些节点序列转换为低维向量表示。这一方法的独特之处在于它能够将网络中的节点转化为连续向量空间中的点,从而为节点之间的相似性和关联性提供了新的度量方式。Grover等人 [15] 提出Node2Vec算法,通过定义node-to-node转移概率分布来实现对网络节点的高质量嵌入表示。与DeepWalk类似,Node2Vec也利用随机游走的策略捕获网络局部结构,但同时采用深度优先搜索和广度优先搜索来平衡序列上下文和距离信息,建立更完整、更贴近真实网络的节点向量表达。
本文提出了一种基于聚类的方法,首先计算节点的接近中心性和介质中心性构建二维特征矩阵,其次利用基于K-means的迭代策略来找到聚类中心,并通过加权的Dijkstra算法将其余节点进行分配,直至所有节点完成社团划分。在几个真实网络上的实验结果证明了所提出算法的有效性。
2. 相关理论
2.1. 图的定义
给定网络模型
,其中V代表节点的集合,表示为
;E代表节点之间连接的边的集合,表示为
;A代表网络的邻接矩阵,记作
,其中,当节点
和节点
之间存在连接时,
;反之,则
。此外,
表示边
的权重。
2.2. 网络拓扑中心性
2.2.1. 接近中心性
接近中心性,通常表示为Closeness Centrality (CC) [16] ,评估了一个节点与其他节点之间的平均最短路径距离。这一度量方法关注的是节点在网络中的紧密性,即节点与其他节点之间的距离越短,其接近中心性值越高。其公式为:
(1)
(2)
其中,
表示节点i到其余各点的平均距离,N表示所有节点的总数,
表示连接节点i,j的最短距离。在这里,接近中心性的概念用来描述一个节点与其他节点之间的联系程度,即这个节点与其他节点沟通的便捷程度。聚类中心作为网络中的中心,与其他节点的联系应该比普通节点要强。
2.2.2. 介质中心性
介质中心性,通常用Betweenness Centrality (BC)表示 [17] ,用于评估网络中的节点在不同节点对之间的最短路径上出现的频率。这一概念有助于我们识别那些在网络中连接不同部分、促进信息流动的节点,从而更好地理解网络的结构和功能。介数中心性的计算公式为:
(3)
其中,N表示节点的数量,
表示由节点s到达节点t的所有最短路径的条数,
则表示在满足
条件的路径中,恰好路径节点i的路径条数。聚类中心作为社团内的中心,起到其他节点之间的连接沟通作用。
2.3. Dijkstra最短路径算法
Dijkstra算法 [18] ,被广泛认为是一种基于局部最优选择策略的最短路径搜索算法。该算法的核心思想是逐步探索并更新到达各个节点的最短路径,以便有效地确定源节点与其他节点之间的最短距离。具体算法步骤如下:
第一步:初始化节点,将起点s的距离dist[s]赋值为0,把除s外的其它顶点的已知最短距离dist数组置为一个很大的数(表示暂时不可达)。再定义一个S集合,存放已经确定了最短路径的节点。
第二步:迭代,找到当前未被访问的、距离最近的节点v(即在dist中最小的),加入S集合;并通运算更新与v相邻节点到起点s的距离,直到所有顶点都被加到S集合中。算法一给出了Dijkstra最短路径的算法流程。
3. 基于节点拓扑属性的社团结构划分方
3.1. 基于迭代策略的聚类中心选择
根据网络图计算每个节点的接近中心性和介质中心性CC和BC值。对
和
进行Max-Min归一化处理,具体公式为:
(4)
(5)
值得注意的是,接近中心性CC和介质中心性BC都很小的节点将没有机会被选为聚类中心。具体来说,我们要保留前80%节点的平均值,即对所有节点按照CC和BC的值从大到小排序,选取前80%节点的平均值作为阈值。将所有CC和BC值都小于该阈值的节点丢弃。剩余节点组成的集合记为
,并将
的CC与BC的乘积记为
,其公式为:
(6)
根据
值对节点进行k-means聚类,其中
,即分为两组。根据启发式方法,在初始的聚类过程中,将
较高的节点设置为初始聚类中心(H-group),
较低的节点设置为被划分的一个集合(L-group)。然后,使用一个标准来确定新H-group中的节点是否被选为聚类中心,该标准涵盖了计算L-group中的最大值与H-group中的最小值,然后取其平均值。这一度量方式旨在从平均的角度审视两个不同群体之间的关联程度。其公式如下:
(7)
其中,
表示集合中节点的数量,
表示H-group中最小的
值,
表示L-group中最大的
值,
为平衡参数,根据实验最佳值为0.5。如果满足不等式,则说明L-group中已经没有更多的节点应该被划分到H-group中作为新的聚类中心了,递归过程结束;否则,从L-group将
值最大的节点分配给H-group形成新的H-group',继续进行k-means聚类的迭代过程。重复执行直至达到所需的收敛状态,即不再有节点被划分到H-group中。将最终的H-group节点集合视为网络的聚类中心。
3.2. 节点聚类分配
一旦确定了聚类中心,接下来的任务是使用Dijkstra最短路径算法将尚未分配的节点分配到它们最近的聚类中心所在的集群中。值得注意的是,这一聚类分配过程是在单一步骤内完成的。这意味着在确定聚类中心后,节点的分配过程更加高效,省去了多次迭代的需要,从而加速了整个聚类过程。不仅能够在实际应用中节省时间和计算资源,还有助于减少潜在的计算复杂性。
4. 实验与结果分析
选取3个已知社团标签的真实网络数据集Karate [19] 、Football [20] 和Polbooks [11] 来进行实验,表1列出了真实网络的先关统计数据。

Table 1. Statistical analysis of real network datasets
表1. 真实网络数据集的统计分
本文应用标准互信息(Normalized Mutual Information, NMI) [21] 、兰德指数(Adjusted Rand Index, ARI) [22] 和纯度分数(Purity) [23] 这三个评价指标,对本文所提出的算法本文算法与LPC [9] 、GN (Girvan-Newman Algorithm) [24] 方法进行社团划分结果比照实验。
图1为三个真实网络的二维决策图,图中横纵坐标分别表示节点的拓扑结构属性接近中心性(CC)和介质中心性(BC)的标准化后的数值。此外,图中的颜色条表示节点聚类中心的可能性。节点颜色越接近红色,则越有可能成为聚类中心。最后使用基于K-means的迭代策略进行量化找到具体的聚类中心节点。
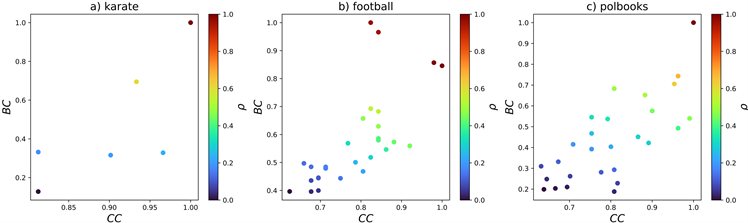
Figure 1. Two dimensional decision graphs of three real networks
图1. 三个真实网络的二维决策图
表2展示了不同算法的标准互信息对比,本文的算法本文算法在三个真实网络中的结果相对较好,特别是在Karate真实网络中,本文算法达到性能最佳。表3和表4分别为ARI和Purity评价指标下不同算法的对比,表现出同样的结果。从图中可以看出本文所提方法在Karate的性能表现最佳,在NMI、ARI、Purity三个评价指标中分别达到了81.56%、83.34%、100.00%,在Football和Polbooks数据集中,并没有表现出最好的性能,但也并不是最差的。
Table 2. Comparison of NMI among various algorithms
表2. 不同算法的标准互信息NMI对比
Table 3. Comparison of ARI among various algorithms
表3. 不同算法的兰德指数ARI对比
Table 4. Comparison of Purity among various algorithms
表4. 不同算法的纯度分数Purity对比
分析其原因,考虑数据集之间的本质差异。Karate数据集源自于一个空手道俱乐部,反映的是俱乐部成员之间的社交互动和联系。这种类型的网络往往表现出较为明显的社交结构特征,其中社团结构的形成与个人间的日常交流密切相关。因此,此类网络中的社团划分通常较为清晰,且社团内部的联系比较紧密。相比之下,Football数据集代表的是12支足球队之间的比赛网络。这种网络的连接通常基于比赛关系而非日常社交互动,因此其社团划分可能不如基于社交互动的网络那么明显。此外,足球队之间的比赛并不一定能完全反映出队伍之间的社会关系或者社区归属感,而是更多受赛季赛程和比赛结果的影响。Polbooks数据集则涉及政治图书之间的共引关系,映射的是图书在政治倾向上的二分性。综上所述,本文提出的算法在分析具有强社交结构特征的网络时表现得更为优秀。
此外,在基于迭代策略的聚类中心选择阶段,我们还对平衡参数进行了详尽的敏感性分析来确定最佳参数值,以确保聚类过程的准确性和效果。在图2中,横坐标对应着不同参数
的取值,而纵坐标则展示了各种评价指标的具体数值,包括兰德指数ARI、标准互信息NMI以及纯度分数Purity。这一敏感性分析的目的在于确定最佳参数值,以确保聚类过程的准确性和效果。从图2中可以看出,当
时,在不同真实网络上的性能总体达到最佳。
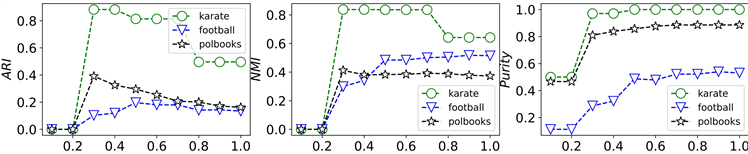
Figure 2. Sensitivity analysis for different μ parameter values
图2. 不同μ参数值的敏感性分析
5. 结论
本文提出了一种基于节点拓扑属性的社团结构划分算法(记为本文算法),首先计算节点的接近中心性和介质中心性来构建二维决策图,然后使用基于k-means聚类的迭代策略选择聚类中心,最后使用Dijkstra算法将剩余节点分配给就近的聚类中心所在的社团,直至所有节点完成分配实现网络的社团划分。在三个真实社会网络中,将所提算法与LPC算法和GN算法进行综合性能对比,进一步确认了本文算法在不同社会网络下的可行性和有效性。实验结果显著地展示了本文提出的算法在识别Karate数据集这类具有强烈社交关系的社群结构方面的卓越性能。针对Karate数据集,本文所提算法在NMI、ARI、Purity三个评价指标中分别达到了81.56%、83.34%、100.00%,显著提高了社团划分结果的准确性。