1. 引言
对石油行业的数据分析揭示了中国对外部石油的依赖程度每年都呈上升趋势。尽管我国石油产量在逐年递增,但是国内经济的快速增长导致了石油消费的急速上升,这使得石油产量的年度增长量相对较小,从而导致对外石油的依赖度持续增长,进一步扩大了我国石油供应和需求之间的不平衡 [1] 。因此,为了缓解石油供需的压力,增大储备和生产无疑是必要的步骤。在这种背景下,复杂的石油储层特性,如非均匀、非线性和不确定性反应特性,以及石油储层管理中的大量测井数据,其信息量大,来源广泛。在这种情况下,对已有的测井数据的深入分析和应用,准确识别石油储层变得非常重要 [1] 。
将基于聚类分析算法应用于石油储层识别中,能够得到储层识别中的关键测井属性,用这些关键属性进行石油储层的分类有助于提高石油储层的识别率,同时能够约减一些次要的测井属性,减少在石油勘探阶段需要进行勘探的属性数量以便节约开采成本。
K-Means聚类算法在地球科学、信息技术、决策科学等众多领域有着广泛的应用前景。K-Means聚类的核心是将多个维度数据集按一定的距离划分成K个类别,这样在同一类别内的对象之间存在较大的相似度,而在不同类内的对象之间存在较大的差别 [2] 。
如何实现对油气层特征的快速、精确辨识,是目前国际上石油资源勘查与开发中急需攻克的难点问题。为了解决这个问题,发展出了以测录井数据为主要手段的方法,然而,对于复杂岩性和低渗透率的储层,其适用范围还不够广。K-Means聚类的发展为油气层识别工作提供了新的方法和途径。本文从实际储层出发,采用K-Means聚类的思想,将测井资料和岩芯测试结果有机地融合起来,在选取特征参数的基础上,采用K-Means聚类分析方法,对陕北吴起白河区块的油气藏开展研究。
2. K-Means聚类分析模型
2.1. K-Means算法原理
聚类是一种依据各类特性将数据分拆至不同的集群或群组的步骤,属于同一群组的元素具有相似性,然而,不同群组之间的元素相差甚远。简单来说,聚类分析是在缺乏预知的状况下,利用各种方法根据数据自身的类似性将数据点分配至不同的集群的过程 [3] 。
K-Means算法,也被称为K-均值算法,是在无监督学习域里广泛应用的一种聚类算法。此方法采用物体之间的相似度作为分类数据的依据,通过计算距离函数,比较样本P和样本Q之间的相似性,以此将极具相似性的数据分类至同一个集群。其关键思路在于:在给定K值以及K个初始类群中心的基础上,定义每个数据记录(即点)属于距离自身最近的类群中心所代表的类别。当所有的数据点都已被归属后,根据每个类群中的所有数据点,重新计算该类群的中心点(求平均值);然后再继续处理这些分配点和更新类群中心的步骤,直到类群中心的改变范围微乎其微,或者达到预设的迭代次数为止 [4] [5] 。
我们假设有一个数据样本X,它由n个元素组成,即
,每个元素都具备m个维度的特性。K-Means算法的目的在于,将这n个元素基于他们间的相似性分配到预设的K个簇中,每个元素只能被分配到离它最近的簇。在应用K-Means算法之前,首先要确定k个初始聚类中心
,
,然后通过计算每一个对象到每一个类中心的欧氏距离,如下式所式
,
表示的是第i个对象
,Cj表示的是第j个集群中心,j的范围是
,
指的是第i项的第t个特性,t的范围是
,
则表示的是第j个集群中心的第t个特性。根据此方法,比较每个项目与每个集群中心的距离,将项目分类到与其最近的集群之中,从而形成k个不同的分组,该方法就被称为K-Means算法 [6] [7] 。
K-means算法的初始聚类中心是随机选取的,而聚类结果易受初始中心的影响,因此,采用不同的初始聚类中心进行聚类,所得的聚类效果也存在较大差异。在此基础上,本文先求出数据集中的每一个数据点到原点的距离,再将这些数据点按照此距离进行排序,把已排列好的数据平均分成k个组,并以各组的中间数据点为初始聚类中心。由此,可以减少聚类结果误差过大影响其效果。
2.2. K-Means算法流程
首先,根据需要划分的簇类数k,从样本集合中选取k个数据中心,对每个样本进行多次迭代,并计算每一个样本对k个数据中心的距离。当一次遍历结束时,全部的样本都找到自身属于的类别,但是这个分类并不是最后的类别,因此需要再做一次循环。在第二遍迭代前,首先要在簇中更新质心,计算出每一个簇中的质心,再反复上述过程,直至到达期望的迭代数目或多次迭代的结果,簇内的信息都不会改变 [8] 。K-Means均值算法的主要过程如图1所示。
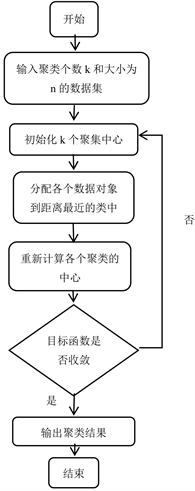
Figure 1. K-Means basic flow of the algorithm
图1. K-Means算法基本流程
K-Means聚类算法是一个不断迭代的过程,原始数据集有4个簇,图中x和y分别代表数据点的横纵坐标值,采用K-Means方法对样本进行聚类,并将其进行两次迭代,得出最后的聚类结果,迭代过程如图2所示。
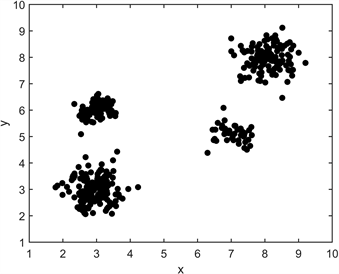
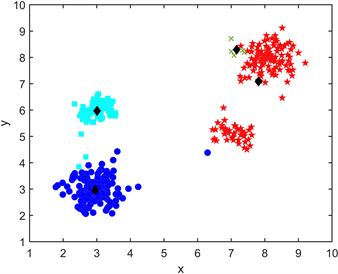
(a) 原始数据 (b) 选择初始中心
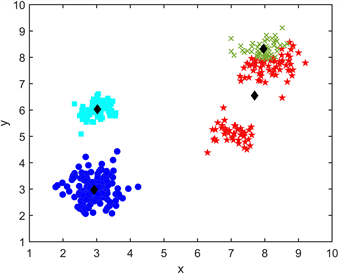
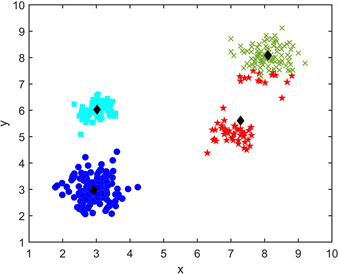 (c) 第一次迭代 (d) 第二次迭代
(c) 第一次迭代 (d) 第二次迭代 (e) 最终结果
(e) 最终结果
Figure 2. K-Means algorithm iteration process
图2. K-Means算法迭代过程
3. 储层含油性识别中的K-Means聚类
3.1. 样本和指标的选取
本次样本和指标所选取的数据源自于陕北吴起白河区域。吴起白河油区位于吴起县城西北部,东西长约15 km,南北宽约11 km,面积约110 km2。研究区目的层构造活动较弱,构造形态简单,处于一级构造单元伊陕斜坡带的西部(图3)。在此背景上发育了多排局部略高的微幅度鼻状隆起。这些微幅度鼻状隆起,在平面上呈隆凹相间的条带状分布。地层岩性多呈砂泥岩互层,受到成岩期压实作用影响,纵向上各层构造具继承性发育的特点,但横向上各层构造高点略有偏移 [9] [10] 。
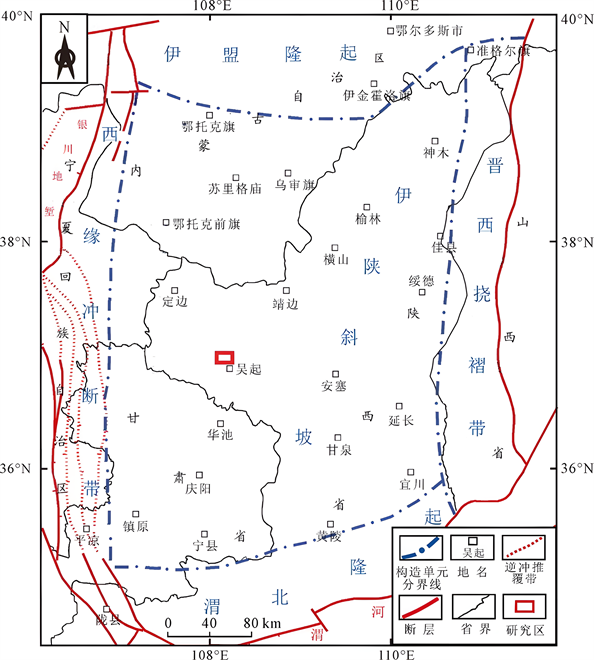
Figure 3. Regional map of structural location in the study area (Xiong Anliang 2023)
图3. 研究区构造位置区域图(引自熊安亮2023)
根据沉积旋回与储层非均质性的关系,因此在进行地层划分时,需要采用测井资料进行地层划分。测井资料的数据量越大,对储层的物性、流体特性的刻画也就越来越细致,所以用测井曲线来进行地层划分是最基本、最有效的方法。通过对鄂尔多斯盆地延长组地层(表1)的分析,发现长3号、长4 + 5和长6的测井资料具有“高电位,低密度,低电阻”的特征 [11] [12] 。

Table 1. Marker surface layer in Yanchang formation
表1. 延长组地层中的标志层
实验数据来源于陕北吴起白河区域,目前储层和微构造条件是石油聚集的关键因素,该井的测井特性和相关的测井解读成果可在表2中查询。
Table 2. Logging interpretation and identification results
表2. 测井解释结论和识别结果
我们可以从表2的数据中了解到,用于识别储层含油性的几种特征包括:自然电位、孔隙率、双感应以及渗透率。井测得出的结论指出:致密油层、水层和干层。在进行聚类的过程中,利用欧氏距离来评价相似性,并进行了归一化处理以消除无量纲下数值差异。所有的4个属性,都被用于储层含油性的辨识。
3.2. 分类结果
表2的最后一栏展示了聚类的结果,其中用粗体标注了与测井结果有出入的样例。经过比对发现,鉴别的误差大致集中在差油层和水层以及油层和差油层的交界处 [13] 。这主要源于界定差油层和油层、差油层和水层的度量标准 [14] 。实际上,由于很难确定精确的分界标准,在实际操作中通常只能给出一个可以接受的范围。但是即便如此,整体上聚类效果有较高的准确率,对于预测测井数据仍具有很高的价值。
4. 结论
(1) 储层含油性的确定是油气藏测井评估中的一个关键环节,是把测井数据转化为地质信息,反映测井解释结果及使用效果的更高阶段,其好坏将直接关系到油气勘探的效果和成功率。在某些复杂的低孔渗、低电阻率等地质条件下,常规的测井解释方法难以取得理想的效果。本文提出将K-Means聚类分析的方法引入到储层识别中,使其可以较好地识别储层的各种复杂特征,符合应用要求 [15] [16] 。
(2) 油气藏的辨识是一个多因素的综合分析,单独利用一种数据往往无法达到预期的效果,尤其是对于具有复杂性质的油气藏,其辨识成果很难为油气藏的勘探与开采提供依据。因此,在实践中如何选取合适的典型参量还有待于进一步提炼和归纳。K-Means聚类方法用于储层含油性的识别时,由于储层类型数量的变化而有所不同,聚类质量差异很大,因此K-Means聚类方法在实际中具有很大的局限性,容易陷入局部极值。
(3) 自K-Means算法提出以来至今已有多时,它已经成为一种非常典型的聚类方法,并且在未来的研究中会得到更广泛的应用。对于传统K-Means算法是聚类分析中一种常用的基于划分的方法,其不足之处在于其对初始聚类过于敏感。为此,本文针对这一点进行了优化,将初始聚类中心的随机选取,优化为对各数据点到原点的距离进行排序后,选择k个数据点作为初始聚类中心,可减少聚类误差大影响其效果。
(4) K-Means方法在油气藏辨识领域具有广阔的发展空间,但仍存在许多问题有待解决。在本项目提出的基础上,还需要进一步提高在大规模或者高维度数据集条件下的处理能力并且减少其算法的时间复杂度。在此基础上,我们还需要对其进行更深入的研究,以提高其识别性能。
致谢
感谢高胜利教授提供的研究资料以及指导建议。