1. 引言
传统的螺栓安装质量检测方法通常使用经验观察和尺子测量等方式。这些检测方法的效率低下,且易使工人产生视觉疲备,进而导致误检、漏检,存在安全隐患 [1] 。相较于传统的验收方法,使用图像语义分割技术进行螺栓安装验收具有自动化、精度高、花费小的优点,能够使得对接地设备的安装验收更加智能化。
传统的图像语义分割方法使用包括基于阈值、候选区域、聚类等机器学习的方法来构建像素分类器 [2] ,从而完成图像的语义分割,但由于硬件设备的计算能力有限,传统方法在分割图像的颜色、形状、纹理等低级语义特征时通常效率不高、分割时间较长,并且面对颜色相近且背景复杂的螺栓图像分割任务时,图像的语义分割精确度较低。
随着深度学习技术的兴起,越来越多的学者选择利用深度信息去辅助可见光图像进行图像分割,结合基于深度学习的端到端深度卷积神经网络(Deep Convolutional Neural Networks, DCNN) [3] 进行图像语义分割,有效的提高了分割的效率和精度。文献 [4] 在DeepLabv3网络的空洞金字塔池化层中引入了一个全局池化层,更好地提取了图像级特征,能够从螺栓关键区域分割出螺母和螺杆。文献 [5] 使用了SSD512定位算法和U-net8模型的实现了对紧顶螺栓图像中螺栓和螺母的分割。文献 [6] 将阈值分割和Rammer算法结合对螺栓轮廓图像进行分割,并利用质点云法确定螺栓轮廓。文献 [7] 提出了一种基于Faster-RCNN卷积神经网络的螺栓松动检测方法,能够更加快速地检测出图像中的螺栓。文献 [8] 构建了一个协作反卷积神经网络来联合建模,将深度图像作为可见光图像的附加通道输入网络进行语义分割。然而上述方法,要么不能充分地融合深度图像和可见光图像的特征,要么就无法适用于纹理相似且背景复杂的任务场景中,而且还容易受到噪声干扰。
对此,本文提出了一种基于RGB-D边缘信息融合的接地设备图像语义分割方法,充分地融合可见光图像特征以及深度图像信息,并利用边缘信息,大幅提高了螺栓图像分割的准确性。首先对所获取的接地设备相连螺栓的可见光图像和深度图像进行预处理;然后通过编码模块提取深度图像特征和可见光图像特征,并进行多特征融合;最后利用边缘信息辅助监督,输出最优的预测图像语义分割结果。实验结果证明,本文提出的算法在对颜色纹理相近且边缘轮廓模糊的复杂图像情况下分割准确度较高。对精确分割螺栓图像,保障接地设备的安装质量检测方面有着极大的应用价值。
2. 基于RGB-D边缘信息融合的接地设备图像语义分割
本文提出的基于RGB-D边缘信息融合的接地设备图像语义分割网络架构如图1所示。首先获取包含接地设备相连螺栓的可见光图像和深度图像,对进行预处理,其次将经过预处理的可见光图像和深度图像输入进双路编码–解码模块 [9] 中,其中编码模块有两个平行排列的残差网络ReSNet [10] 组成,采用卷积和池化操作分别得到相应的可见光图像特征与深度图像特征;添加空间金字塔池化层并引用注意力辅助模块获取更加丰富的特征图;将经过特征融合后得到的全局特征图输入至解码模块,此模块由语义分支和边缘分支两个分支构成,语义分支主要负责从可见光图像和深度图像中提取语义信息,并利用这些信息生成语义预测结果。边缘分支主要通过分析可见光图像和深度图像的边缘,确定图像中不同区域之间的边缘,并输出边缘预测结果;最终结合边缘信息进行监督训练,得到最优的预测图像语义分割结果。
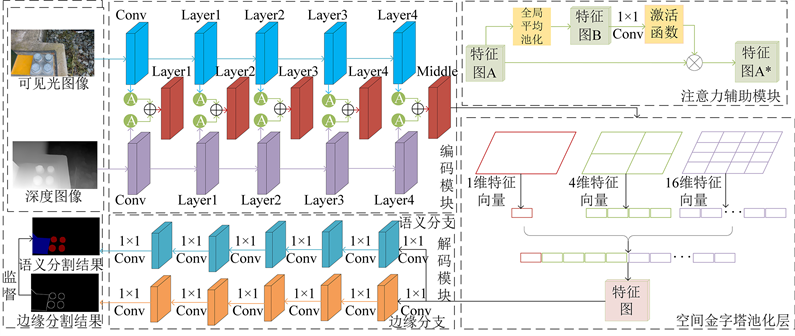
Figure 1. Network architecture of RGB-D image semantic segmentation based on edge information guidance
图1. 基于RGB-D边缘信息融合的接地设备图像语义分割网络架构
2.1. 图像预处理模块
传统的语义分割算法在图像处理部分较为粗糙,然而螺栓图像存在对比度低、颜色衰退以及细节模糊等现象,因此需要对螺栓图像进行预处理。图像预处理可以消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据,从而改进图像分割的可靠性。首先对所获得的可见光图像和深度图像,使用高斯滤波器进行去噪处理;其次利用校正网络(RSN)对去噪之后的图像进行畸变校正,校正网络通过学习训练数据中的畸变模式,预测输入图像的几何畸变,并生成校正后的图像;最后将矫正后的图像进行归一化操作,即将图像的像素值缩放到[0, 1]之间。
2.2. 注意力辅助模块
目前大多数的编码–解码模块大都只是简单的从输入图像中提取特征。如文献 [11] ,使用两个编码器分别从可见光图像和深度图像中提取特征,并在上采样之前或期间结合两者的特征。另一个类如文献 [12] ,只是在下采样阶段融合可见光和深度特征。前者不能充分结合图像的特征信息,而后者往往因为融合分支而丢失原始的可见光和深度分支。因此本文在双路编码模块的每一层网络后面引用注意力辅助模块 [13] (Attention Assistance Module, AAM),得到每一层网络新的特征图,从而丰富特征图像的语义特征。
从编码模块得到的某一特征图
,首先对特征图A进行全局平均池化,得到一个大小为
的特征图B,第m个通道特征图表示如公式(1)所示:
(1)
其中
,
,H,W依次代表特征图A的高度和宽度。对于特征图A,R表示特征图维度,C为通道数。
保持特征图B的通道数C不变,加入一元卷积层用来确定通道间的权重分布。然后,在卷积结果上使用sigmoid激活函数得到约束权重向量的值,并使其保持在[0, 1]之间。
是sigmoid激活函数,此过程如下所示:
(2)
最后,将约束值与输入特征图A进行叉乘,得到一个包含更多有用信息的特征图
,其表达式为:
(3)
将可见光特征图像和深度特征图像输出映射按照一定比率输入注意力辅助机制融合语义特征,得到全局特征图。
2.3. 金字塔池化模块
现有的深度卷积神经网络要求尺寸固定的输入图像,这限制了输入图像的纵横比和尺度。当输入图像的尺寸不一致时,大多是通过裁剪或通过扭曲 [14] 将输入图像拟合到固定尺寸。这种尺度变化造成的不必要的内容丢失和失真,会使识别精度降低。此外,如果要求尺寸发生变化时,预设的尺寸可能又要改变,大大的加深了工作量。因此本文方法将从编码器输出的特征图输入至空间金字塔池化层(Spatial Pyramid Pooling, SPP) [15] ,不同大小的目标候选区域的特征图可以被转化为固定大小的特征图,且使用可变尺寸图像进行训练增加了尺度不变性,防止过拟合。
该空间金字塔池化层由3个最大池化层组成 [16] 。对于编码器输入的任意大小的特征图,3个最大池化层分别以大小为4 × 4、2 × 2和1 × 1的网格将特征图分为16、4、1块,然后在每个块上最大池化,提取相应特征。第1个池化层提取16维特征向量,第2个池化层提取4维特征向量,第3个池化层提取1维特征向量,最后将3个池化层提取的特征融合,得到16 + 4 + 1 = 21维特征向量,从而使任意大小特征图都能转化为21维的特征向量,全连接层不再对输入图像的大小有所限制。
2.4. 损失函数
在螺栓图像语义分割中,选择一个合理的损失函数去提高准确度尤为关键,同时也可以减少网络的训练时间,帮助网络更好地训练。本文利用Dice系数损失函数 [17] 对语义分割标注真值Y1和预测的图像语义分割结果Y2进行结合分析,得到两者之间的误差X1,具体公式如下:
(4)
利用Boundary LOSS [18] 损失函数对训练图像的边缘信息真值Y3和预测的图像边缘分割结果Y4进行结合分析,得到两者之间的误差X2,具体公式如下:
(5)
将由两种不同的损失函数所得到的误差相加得到所需图像语义分割网络的总误差,具体公式如下:
(6)
在公式(6)中L表示整个语义分割网络的总误差;X1,X2分别表示所述预测语义结果与所述先验的语义信息之间的误差以及边缘预测结果与边缘信息之间的误差;A1,A2为误差X1,X2在总误差中所占的比例系数,两者的大小因语义信息和边缘信息对语义分割网络的重要性而定。利用所得到的误差,使用随机梯度下降算法去不断的调整参数,使得预测信息和实际数据的误差最小,得到一个准确率高的预测结果。
3. 实验结果及分析
针对实际场景下接地设备相连螺栓图像具有不同的类型情况,本文使用ZED2双目相机拍摄了多种场景下的接地设备相连螺栓图像,并制作数据集。其中,数据集共包含接地设备相连螺栓RGB-D图像1300组。部分RGB-D图像以及人工标注的真值图像如图2所示。训练集与测试集按7:3的比例进行划分。其中训练集包含910组接地设备相连螺栓的RGB-D图像以及真值图像;测试集包含390组接地设备相连螺栓的RGB-D图像以及真值图像。
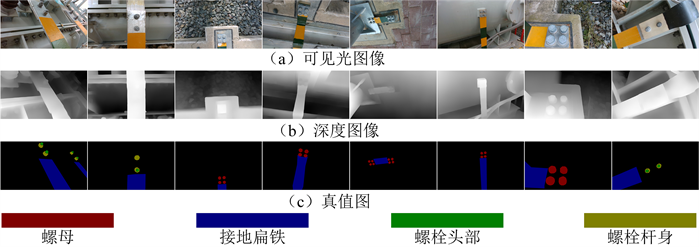
Figure 2. Some RGB-D images and manually marked truth images.
图2. 部分RGB-D图像以及人工标注的真值图像
3.1. 语义分割结果预测实验
本文算法针对不同类型的接地设备相连螺栓图像进行语义分割实验对比,并与深度学习算法SGNet [19] 、ACNet [13] 、FRNet [20] 与ESANet [21] 进行比较,以验证本文所提出的算法的分割效果与精度。对测试集中的100组接地设备相连螺栓的RGB-D图像进行语义分割结果预测实验,不同算法下接地设备相连螺栓的语义分割结果如图3所示,其中图3(a)为根据接地设备相连螺栓的类型以及拍摄角度分为四种情况;图3(b)为原图中经过人工标注的真实接地设备相连螺栓区域,作为各个算法识别效果的参考基准。
图3(c)~(g)分别为SGNet、ACNet、FRNet、ESANet和本文算法对接地设备图像的语义分割结果。SGNet算法使用的空间信息引导在处理具有复杂背景或者细微边缘的图像时,会出现分割不准确的现象,如在处理B组图像,SGNet算法在螺栓边缘分割效果存在“一刀切”的现象,对螺栓细节分割鲁棒性和表征能力较差;对于C组和D组图像,SGNet算法分割结果边缘线条与轮廓模糊,算法精度低。ACNet算法更加注重全局特征而非细节特征,导致在处理颜色相近或边缘模糊的区域时会出现错误分类,如A组和B组图像,ACNet算法在接地扁铁边缘误识别像素点较多,在颜色较为相近之处出现错误分割的问题;对于C组和D组图像,ACNet算法在螺栓与螺栓杆身两区域像素相近时存在部分像素分类的错误,没有精确的分割出螺栓与螺栓杆身,出现了错误的分割。FRNet和ESANet在面对相似纹理和复杂场景下,分割效果较差,存在分割边缘不整齐甚至分割错误的情况,如B组和D组图像。相比之下,本文算法的预测图像最接近真值图像,对复杂背景中的接地设备相连螺栓的识别精度更高。尤其是在螺栓边缘部分,通过最后边缘分支的监督,使得本文算法在接地设备边缘的分割效果要优于其它算法,从而证明了本文算法具有较高的分割性能。此外本文算法从具有较高的鲁棒性,受背景环境之中的噪声,光照变化影响较小,算法稳定性较高。

Figure 3. Semantic segmentation results of grounding equipment images with different algorithms
图3. 不同算法的接地设备图像语义分割结果
3.2. 定量分析
3.2.1. 评价指标
本文选取Acc [22] ,IoU [23] 作为语义分割算法的性能评价指标。实验中各个算法对100组测试图像均做了多次重复实验,结果取平均值。
1) Acc (Accuracy):Acc (准确率)的计算方式如式(7)所示。准确率表示预测正确的样本占所有样本的比例,其中预测正确的可能有正样本也可能有负样本:
(7)
式中TP (True Positive)表示本身是正样本,预测也是正样本;预测正确TN (True Negative)表示本身是负样本,预测也是负样本;预测正确FP (False Positive)表示本身负样本,但是预测为正样本;预测错误FN (False Negative)表示本身是正样本,但是预测为负样本,预测错误。
2) IoU (Intersection Over Union):IoU (交占比)用来表示预测框和真实框之间的重叠率,衡量的是预测框与实际框之间的相近程度。记标记框为A,检测框为B,IOU的计算公式如下:
(8)
式中分子部分表示A框与B框的重叠部分的面积,分母部分表示A框与B框的面积总和。由式可得,IoU的值在[0, 1]之间。因此当IoU越接近1时就说明A框与B框的重合程度越高,模型精确度越高,预测越准确,反之则越差。
3.2.2. 评价指标实验结果
本文算法与SGNet、ACNet、FRNet、ESANet进行了比实验,评价指标如表1所示。相较于其他算法,本文算法在各项评价指标中都表现最优。根据实验结果可知:本文算法的准确度更高,对于接地设备相连螺栓图像的分割效果更加优秀。

Table 1. Quantitative analysis of bolt image segmentation results
表1. 螺栓图像分割结果定量分析
4. 结论
针对传统的接地设备验收方式效率低下,且接地设备之间粘连以及颜色纹理相近等问题,提出了一种基于RGB-D边缘信息融合的接地设备图像语义分割方法,模型输入为可见光图像和深度图像,通过图像预处理增强有用信息,通过双路残差网络提取图像特征,引入注意力辅助模块增强二者的特征融合,采用空间金字塔模块对特征图进行多尺度处理,最后对输出的特征图进行双分支解码,得到语义预测结果和边缘预测结果,并使用边缘预测结果来监督优化语义信息,输出最优的语义分割结果。实验结果表明,本文所提出的方法在变电站接地设备场景语义分割任务中具有较好的表现,能够较好地分割不通的接地设备,对于接地设备的边缘有着较好的分割结果,可以应用于接地设备的安装验收任务中。
致谢
论文作者感谢国网江苏省电力有限公司常州供电分公司对本课题的资助。
基金项目
国网江苏省电力有限公司常州供电分公司科技项目资助。