1. 引言
一个健康、可持续的高等教育体系的构建与维护对国家的发展意义重大。在体系构建、维护、评估中,相应的关键问题有质量、教育研究水平、资金投入、学位价值以及思想交流等相关问题需要考虑与解决。其他因素还包括制度的一些改进与变革,以及国际化对健康可持续教育系统的发展的意义也在不断的探讨中。因此有必要建立以及构建相应的评估模型,为建立一个持续健康的高等教育体系,给出相应的关键的指导思路与战略方针支持 [1] 。在高等教育质量体系的构建过程中,建立的模型应该考虑相应的一些重要的指标原则,例如基于优良的评估结果以及合理的愿景。为构建健康可持续的高等教育体系,应该分析相应研究目标中以及对象中存在的一些问题和改进的空间,探讨当前体系中存在的障碍以及面临的挑战 [2] 。从当前状态向目标远景状态进行合理过渡。保证模型提出的相应的一些解决方案与实施举措的合理性与有效性 [3] 。同时分析相应的制约因素可以对体系带来的相关影响,并给出相应的一些解决方案,同时兼顾社会大环境中高等教育以及高等教育体系机构所涉及的各方面的利益。
建立高等教育体系评价模型围绕评价类的问题,选择合适的指标对相应的一些关键问题以及数据进行收集,建立可解释、可量化的评估模型 [4] 。基于现有的官方大数据进行相应的探讨分析。对原始的数据,我们从世界各国的教育大数据系统中包括金融机构如世界银行中的网站中获取。然后根据观察已收集到的数据与定性的存在的线性上升或下降的趋势,我们考虑采用如最小二乘法拟合出相应的一次函数来对标缺失的数据,然后基于多方指标计算,包括方差的一些评估得到了反应拟合效果较为良好的一个结果。虚拟化的数据也表明了有一定的可信度。我们的处理过程主要考虑使用主成分分析法,将原来的数据投影保留到前几个主要的成分,大大简化了相应的数量级,并将主成分的特征值与贡献率进行操作运算,计算出最终评估得分,作为决策部门进行相应问题分析与探讨的参考 [5] [6] 。
针对我国高等教育体系相应的问题进行分析。我们采取的定量分析的方法是先基于近几十年的数据模型得出的评分,进行分析发现相应的规律。然后选出相应的有代表性的五个指标。每个指标的确定从全球范围内的一些国家教育数据中的主成分分析以及二维评判矩阵综合计算得到。然后观察我们国家相对于其他国家在相应指标上的优势与差距,根据计算这个矩阵的得分确定一些要素,再合理评估模型构建中的一些权重。这里我们用Critic方法。然后又应用Vikor的方法计算。每一行对应研究对象及国家相应的得分。最后我们针对我国的一些具体的数据给出了相应的一些问题分析的一些参考结果。
2. 高等教育体系模型的建立与求解
2.1. 评价体系指标的选择和量化
2.1.1. 指标的选取
模型指标的选取要对国家层面上高等教育体系的数据进行评估并量化 [7] [8] 。统计进行相应的定性评估首先要选择合适的指标体系。合理的指标的选取的判断的方法要基于相应的几个方面考虑:一个是指标之间的关联程度。也就是要选取的指标与评价对象之间的关联度。第二方面是指标的可量化性。确保选择的指标有直接的数据,或者可以借助相应的经验公式进行间接的量化,从而可以保证较容易地建立模型,并对模型求解得出相应的性能体现。第三是模型的可评价性。结合具体实际数据与实际的理论模型,确保选择本身能够更好的反映评价对象的一些重要的一些特性,做一个模型的可拓展应用与适用的重要条件。第四点方面是相应条件获取的难易程度。指标的获取难易程度直接影响模型构建的一些实际问题。如果指标获取难度较高,可能会使不足量的样本数据造成相应的评估偏差,导致最后数据分析的质量下降。基于上面的这四条方法,我们决定从地方教育公平性、学生与教师的比例、授予学位的占比值、教育投入以及国际化程度这五个方面进行评价评估的指标。
2.1.2. 指标的量化
1) 教育投入占比PEI (Proportion of educational investment)
定义:教育投入占比为每年国家投入教育的经费与当年国内生产总值的比值。
说明:上述公式中,SI表示某年国家投入教育行业的总经费,GDP表示当年的国内生产总值。本指标借助简单的比值关系进行量化,同时数据收集难度不大,可解释性高,能够很好地反映出高等教育体系的特征。
2) 大学学生与教师的比率RCST (Ratio of college students to faculties)
定义:每年国家大学学生的数量与高校教师数量的比值。
说明:CS表示大学学生数量,CF表示高校教师数量。与前两个指标的定义形式一样,同时也符合选取指标的基本要求。数据从世界银行中获取。
3) 教育公平系数EEC (Educational equity coefficient)
定义:假设原始数据为大小
的矩阵,横向表示m个省投入教育经费的费用,纵向表示年份,则EEC表示为每年各省州教育经费的标准差与均值的比值。
说明:本指标参考了变异系数的含义及公式,可以实现对不同量纲级别的数据进行比较。若计算出的值较大,说明各地区教育经费的不均衡。本指标能够良好地对教育的公平程度进行量化,容易比较,可解释性高。数据的收集有一定难度,本数据通过各国国家统计局和世界银行收集。
4) 25岁学士以上人群占比PBD (Proportion of people above bachelor’s degree)
定义:年龄为25岁及以上的人口中拥有学士学位或更高学历占同龄人总数的比例。
说明:其中BD表示25岁以上人群中学士学位的人数,population表示25岁以上的总人数。本指标同样借助简单的比值形式,指标数据可以直接在世界银行中获取。
5) 留学生数OS (overseas student)
定义:国家每年引进的外国留学生数量。
说明:本指标符合前文指标选取的基本条件,数据从世界银行,国家统计局中获取。
2.1.3. 数据预处理
Step 1:填补缺失数值
在确定所有指标和量化公式后,我们从各大数据源尝试收集了数据。借助于国家统计局,国内的数据基本可以搜集到。而经过各国国家统计局和世界银行的数据搜集后,仍有许多年份的数据存在缺失。对此仔细观察已得数据后发现,大多数数据随年份存在较为明显的上升或下降的线性变化趋势。至此,我们利用matlab编写最小二乘法拟合线性函数的代码,对所有缺失的数据拟合。对拟合的函数计算R方和RMSE进行比对后,可知拟合的效果较为良好,新填补的数据具有一定的可信度。拟合效果如图1所示。
Step 2:处理极小化指标
高等教育体系模型构建选出的5个指标中,前4个指标:大学学生与教师的比率RCST,25岁学士以上人群占比PBD,教育投入比重PEI,留学生数OS均为极大型指标,即数值越大越好。而教育公平系数EEC数值与教育系统的好坏呈负相关,即EEC数值越大,该国某年的高等教育系统得分越低,称此性质的指标为极小型指标,需要进行正向化处理,公式如下:
在应用上述公式后,EEC将被映射到一个值域为[0, 1]的新的空间中,同时映射后的数据集也由极小型转变成了极大型指标,以便应用于之后的综合评价模型中。
2.2. 基于PCA的高等教育体系评价模型
高等教育体系受多个因素的影响与共同作用,本文的分析虽然只选取了五个指标,但是数据中会有存在线性相关的一些指标,尤其是对于问题中大多数数据会随着年份呈现线性的递增或递减趋势。考虑到变量之间存在这种关系,采用PCA算法便能够很好地分析求解到数据的结构和模式,从而提取出主要特征,进一步优化模型。
2.2.1. 主成分分析法(PCA)的原理简介
PCA是一种常用的特征提取方法,旨在运用线性变换对数据操作,将数据中原始特征转化为一组新的相互无关的特征,称为主成分 [6] 。这些主成分的排序按照方差的大小,其中第一个主成分在成分组数据中最大的方差,第二个主成分具有剩余方差中的最大部分,依此类推。通过选择前k个主成分,从而实现数据的降维,同时又能保留大部分原始数据的信息。
2.2.2. 模型的建立
Step 1:构建原始数据矩阵
首先确定原始数据矩阵。对于一个国家高等教育体系进行评价,我们选择近10年的年份作为纵向维度,每一个正向化后的指标作为横向维度构建原始数据矩阵X。下面是以我国相关数据为例进行模型的构建。
Step 2:计算皮尔逊相关系数
基于PCA能够较好地提取线性相关变量之间的重要特征,首先需要计算变量之间的相关系数矩阵,取上三角矩阵进行分析。如果出现变量之间的相关系数接近1或−1,反映了存在变量间的线性关系,则有必要使用PCA对数据特征进行压缩投影。
由以上公式计算出的中国教育指标间的皮尔逊相关系数矩阵,如表1。

Table 1. Pearson correlation coefficient matrix between educational indicators
表1. 教育指标间的皮尔逊相关系数矩阵
指标之间对结果分析存在明显的多重共线性,这意味着多个指标可能在描述相同的信息,至此有必要利用PCA进行数据降维,提取出主要特征。
Step 3:利用PCA提取主要特征
1) 数据中心化处理,消除均值偏移,确保各特征具有相同的重要性;
2) 计算协方差矩阵,得出各指标间的相关性,判断是否存在冗余信息;
分析中国高等教育的数据矩阵,利用matlab的cov函数计算得到协方差矩阵,如表2所示。
Table 2. Covariance matrix of data for higher education
表2. 高等教育的数据协方差矩阵
3) 提取特征值和特征向量,其中
为C的特征值,a为C对应于
的特征向量;
利用matlab的Eig函数,计算得特征值和特征向量(降序排序),如表3所示。
Table 3. Eig Function eigenvalues and eigenvector matrix
表3. Eig函数所得特征值与特征向量矩阵
计算累计贡献度,挑选出贡献度在0.95以上的前q个指标(q尽可能小);
由于中国后四个指标多重共线性的影响,将原始指标投影成新的特征之后,排名第一的新特征值就已经占据了几乎所有的权重,故我们保留第一个特征值及其特征向量。究其原因,可能是中国的教育还处于发展之中,并没有达到一个稳定的状态,同时和平年代下外界干扰因素较少,使得各指标的数据能够稳步线性升高或下降,这在一定程度上会导致数据质量的下降,反映出的信息具有重复性。
Step 4:计算综合得分
将前q个特征值与对应的贡献率相乘求和,计算出最终得分;
对于中国高等教育系统,应用本模型计算出的综合得分:
3. 模型参数的求解
3.1. 利用CRITIC求解客观权重
3.1.1. 原理简介
CRITIC法对客观权重的确定综合了指标间的对比强度和冲突性,兼顾了权重的关联性与变异,采用平均差作为改进,能够更加客观全面地提高权重的准确性 [9] [10] 。与同为求客观权重的熵权法比较,本方法的两个优势为,首先CRITIC法通过计算指标之间的相关系数从而捕捉到不同标准之间的相互关联性,能更准确地进行评估,避免了熵权法中仅考虑指标间的独立性的问题。其次,CRITIC由于考虑了指标间的相关性,能使得结果更加的稳定和具有鲁棒性,这避免了熵权法容易受异常数据和噪声的影响。
3.1.2. 模型的构建
Step 1:指标变异
数据的离散程度可通过变异性指标衡量。通过标准差公式来计算变异性,数值越大反映数据内部的差异越大,所包含的信息就越多,应当给予更大的权重占比。
Step 2:指标互斥性
使用皮尔逊相关系数来表示指标间的相关性,若指标间相关性越强,则冲突性越小,所包含相同的信息就越多,应当给予更小的权重占比。
Step 3:计算信息量和权重
越大,第j个评价指标在整个评价指标体系中的作用越大,就应该给其分配更多的权重,由公式可知权重的值域为[0, 1]。
3.2. 利用VIKOR计算得分
3.2.1. 模型原理简述
VIKOR模型方法是一种多指标、多因素的建模以及决策方法。他通过考虑体系整体最优评估值,以及部分个体的一些缺失值,加入相应的主观加权,得到基于一定优先级的折中的解决结果。可以解决其他方法接近理想解的并不是最优解的一些实际问题。其中整体的目标效益值反应体系决策系统决策者要考虑的对事物的一些主观的因素影响。部分个体的一些数据本身的一些不足对问题的一些评估对应一些偏差。由于Vikor这种方法综合了两个相互对立的因素,可以对两种效果的影响进行一种折中处理,可根据这种系数期望求解模型指标数据。
3.2.2. 模型的构建
Step 1:数据规范化
对于决策矩阵
,首先要将指标正向化。对于极小型指标,区间型指标,中间型指标等采用不同的策略,将原始数据映射到相匹配的分数域中。在接下来的模型中由于只出现了极小型指标,我们沿用问题一中处理极小型指标的公式来实现,公式同时也将数据映射到了[0, 1]的值域当中。
对于剩下的极大型指标,采用以下公式将其映射到[0, 1]的值域中:
Step 2:正负理想解
根据规范化后的矩阵确定正理想解
和负理想解
Step 3:群体效益值和个体缺憾值
其中,
为最大群体效用,是
测度;
取小个体遗憾,是
测度;
为各属性权重;
,
,
,
;v为决策机制系数,
。当
时,表示根据最大群体效用的决策机制进行决策;当
时,表示依据决策者经过协商达成共识的决策机制进行决策;当
时,表示根据最小个体遗憾的决策机制进行决策。
Step 4:计算最终得分
VIKOR的决策机制中包含了对群体效益最大化和个体遗憾最小化的权衡考虑,通过设置决策机制系数
来决定评价的偏好。为了同时最大化群体效用值和最小化个体遗憾值,这里决策机制系数取0.5。
将分数正向化的同时映射到区间[0.3679, 1]当中。
3.3. 基于CRITIC-VICOR法的中国高等教育体系的综合评价
3.3.1. 中国近十年的教育发展评价
1) 模型的求解
首先建立中国各正向化后的指标与年份组成的评判矩阵,如下表4所示。
Table 4. Positive data evaluation matrix
表4. 正向化数据评判矩阵
利用CRITIC计算出各指标的权重如下:
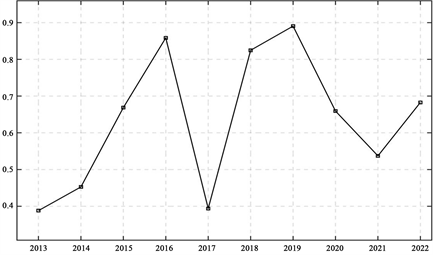
Figure 2. Changes in evaluation of higher education scores in China in the period of past 10 years
图2. 中国高等教育得分近10年评价变化
之后设置决策机制系数
,用VIKOR算法求得中国近十年的得分变化。
2) 结果分析:以上步骤求得中国高等教育在近10年中的变化情况。观察如图2所示结果不难发现,最高点和最低点都呈现上升趋势,数据整体也有向上的趋势,反映了我国教育体系总体上呈现健康上升的态势。然而,我国的教育在进步的过程中也可能会遇到阶段性的困难,例如2017年的得分比前后两年都要低很多。
3.3.2. 中国各项指标的定向分析
1) 教育投入比重PEI
依照PEI指标数据,建立年份与国家组成的评判矩阵,如表5所示。
Table 5. PEI indicator country and year evaluation matrix
表5. PEI指标国家与年份评判矩阵
利用CRITIC-VIKOR计算每个国家的综合得分
2) 25岁学士以上人群占比PBD
依照PBD指标数据,建立年份与国家组成的评判矩阵,如表6所示。
Table 6. PBD indicator data evaluation matrix
表6. PBD指标数据评判矩阵
利用CRITIC-VIKOR计算出每个国家的综合得分
3) 大学学生与教师的比率RCST
依照RCST指标数据,建立年份与国家组成的评判矩阵,如表7所示。
Table 7. RCST indicator data matrix
表7. RCST指标数据评判矩阵
利用CRITIC-VIKOR计算出每个国家的综合得分
4) 留学生数OS
依照OS指标数据,建立年份与国家组成的评判矩阵,如表8所示。
Table 8. OS indicator data evaluation matrix
表8. OS指标数据评判矩阵
利用CRITIC-VIKOR计算出每个国家的综合得分
5) 教育公平系数EEC
依照EEC指标数据,建立年份与国家组成的评判矩阵,如表9所示。
Table 9. EEC indicator data evaluation matrix
表9. EEC指标数据评判矩阵
利用CRITIC-VIKOR计算出每个国家的综合得分
3.4. 对中国高等教育体系的建议和愿景
各国指标得分分析如图3所示。
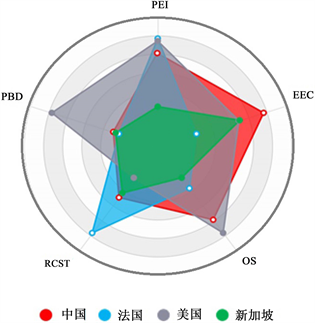
Figure 3. Analysis of indicators in various countries
图3. 各国指标分析
对中国而言,相较于其他三个国家得分最好的是教育公平性EEC。其次是教育投入占比PEI和留学生的数量OS。短板也十分明显,即学生教师比和大学生的占比得分相对较低。因此,有必要投入更多的精力用在培养教师和大学生的数量上。
4. 结论
根据构建的高等教育体系评价模型,得出相应分析求解阶段性的指导思路,为了提高教育质量以满足日益增长的对教育资源的一些需求,模型数据分析表明对体系有效的投入的需要,如加大对师范教育的支持,提供更多的教育经费与教学资源,并且吸引更有潜力的一些师资选择教育专业,同时提供好的培训与进修机会,打造培养更高层次的教师队伍。同时根据模型中相应指标的一些评价,得出需要的教师评聘制度改革问题,公平、合理、透明地选拔合适的人才,加强队伍的管理,健全师资评价提升机制,建设更好的培训与发展计划,提高教育体系人才打造成效。目前国内的大学生占比虽然比较低,但是经过近几十年来的发展,在青年人群体中,大学生的比例已经远超过去。结合我国高教区域、高等教育体系的健康发展要求与相应的评价指标的一些分析,我们得出的结论是应该增加高等教育资源与资源建设的投入,提供更多的资金与设施支持,确保更有才华的学生能接受高等教育。同时加强高等教育的评估与质量监管,建立健全的质量评价体系并对高校进行严格的监督与评估,提高整体的教育机构的教学水平与教学质量,加强在校学生职业导向与实践创新能力培养,与企业、行业以及对应的实习实训单位合作培养学生的实践能力与职业技术水平,适应社会的人才需求,提高人才的综合素质与职业能力,为国家的社会发展与经济建设做出重要贡献。
基金项目
本项工作受国家自然科学基金项目11547024资助。
NOTES
*通讯作者。