1. 引言
地下流体流动预测模型是地下水和油气资源开发,以及场地修复和清理活动的开发和管理的重要一环。当有可靠的模型输入时,基于地下水模型的石油生产和管理是十分有效的。然而,在实践中,地下岩石层的复杂性、地区差异性和不可接近性,给储层油气勘探和开采带来了很大困难。人们通过一定的观测数据,对模型中的未知参数进行估计,进而做出合理的预测用于指导生产。
贝叶斯方法 [1] [2] 是参数估计的一个有效方法,它可以将观测数据中的不确定性和未知参数的先验信息相结合。相比于传统的优化方法,贝叶斯方法给出了参数的后验概率密度而不仅仅是单个的点估计,有利于我们量化参数中的不确定性。然而,正演模型的非线性性或先验信息的非高斯性,使得我们无法获得后验概率密度函数的显式表达式。
蒙特卡洛马尔科夫链(MCMC) [3] [4] 方法通过构造一条或多条以后验概率密度为目标分布的马尔科夫链,可以有效地刻画后验概率分布。由于所谓的维数灾难问题,MCMC算法在高维模型空间中的采样能力严重下降 [5] 。在过去的几十年里,人们提出了许多MCMC方法来缓解这个问题。一系列与参数维数无关的抽样方法 [6] 被提了出来,其中预选概率密度由离散随机微分方程(SDE)构建。当预选概率密度推广到Langevin动力方程的框架下,可以得到Metropolis调整的Langevin算法(MALA) [7] ,这属于Langevin蒙特卡洛(LMC)方法的范畴。这类方法的另一个分支为无调整的Langevin算法(ULA) [7] ,即样本的更新由Langevin动力方程的直接离散获得。由于略过了Metropolis-Hasting方法中是否接受这一步,ULA方法在抽样时是非常高效的。
另一方面,采用适当的方法对未知随机场参数化,降低未知参数的维数,可以降低抽样方法的计算量。一种高效且直接的方法是使用标准正交线性变换。在流行的压缩基中,Karhunen-Loève或主成分分析最广泛地用于基于先验协方差(二阶)信息的参数化和模型约简 [8] [9] [10] 。Sarma等人 [11] 提出了一种用于参数化非高斯通道的非线性方法来保持高阶统计量。Jafarpour和McLaughlin [12] 引入了一种稳定且计算效率高的参数化方法,离散余弦变换DCT,用于参数化。DCT方法的突出的优势是其构造不需要基于未知参数的先验信息,这使它区别于KLT等数据依赖型参数化方法。Sahni和Horne [13] 将另一种基于变换的参数化方法,离散小波变换(DWT),用于历史匹配。
为了合理地估计DCT基函数的稀疏系数和正则化参数,本文采用了贝叶斯方法。我们使用期望最大化变量选择(EMVS)方法 [14] 来识别未知域的稀疏表示。采用“spike-and-slab”高斯混合先验来描述DCT基的稀疏性。不同的方差参数被分配给“spike”分布和“slab”分布。潜在变量的期望等价于在两个先验中选择正则化参数,它避免了正则化参数的人工选择,因为这些参数是由观测数据自然决定的。在期望最大化(EM)方法的最大化步骤中,我们使用Langevin动力学MCMC方法对DCT基函数的系数进行采样,在动态系统中注入的噪声有助于粒子从局部模式中逃逸。此外,我们使用目标函数的逆Hessian作为预处理,以加速马尔可夫链的收敛。
本文的大纲如下,在第二章中,我们着重描述了在EMVS框架下识别DCT系数的具体过程。在第三章中,我们将该方法应用于地下水流模型非高斯源项场的识别,探讨和比较了该方法在不同预处理矩阵下的收敛效果,并在参数样本的基础上对模型输出变量做出了预测。
2. 贝叶斯稀疏识别方法
2.1. 随机场的参数化
通常,信号的大部分能量都用低阶DCT系数表示。因此,这种数学变换可以用于模型压缩,这是通过将基函数项的系数设置为超过某个阈值等于零(截断)来实现的。在这种情况下,与保留的基相关联的系数成为表达信号的参数,而在反问题中,它们是要检索的未知参数。此外,由于其近似能力、数据无关(预构造)基础和计算复杂度低,离散余弦变换已经成功并广泛地应用于信号及图像处理领域。长度为N的离散一维DCT [12] 的形式如下:
其中
被定义为
在多维空间中,DCT基由一维基的元素之间的笛卡尔积得到,这允许有效的、可分离的处理多维信号。设一个二维储层离散参数场,在x方向有M个网格,y方向有N个网格。对该参数场进行离散余弦变换为
其中
,
,且
记一维DCT基函数矩阵为
,其元素为
且
,其元素为
则二维DCT基函数可以写为如下矩阵形式
其中
表示张量积。
2.2. EMVS
记
为观测数据,
是待估计的未知参数。我们假设输入的
和数据之间的关系为
其中
是正交矩阵,其列是一组正交压缩基,本文采用离散余弦变化基函数作为压缩基。
为正演模型,
是独立同分布的噪声。那么似然函数可以写成
根据EMVS方法 [14] ,引入一个与回归系数
相同维数的二元潜在向量
来表示每个系数
是“入还是出”。假设二进制向量
上的先验分布为模型空间上的先验分布。给定
的
的先验通常是集中在0附近的正态分布,称为“ spike”先验;给定
的
的先验是平板或扩散分布,称为“slab”先验。利用潜在向量
的后验分布来识别后验概率最高的模型。我们假设参数
遵循“spike-and-slab”高斯混合先验
其中N为正态分布,
是“spike”参数,
是“slab”参数,且
。在参数化目标函数后的DCT域中,尽管有大量的基函数,但通常只有少数基函数与目标函数有真正的联系。因此,我们有理由假设真正的
是稀疏的,即使p在增长,其非零元素始终是有限数量的,我们的目标是识别非零元素。
误差方差
遵循逆伽马先验
,恰当的先验分布可以使得后验分布的显式表达形式。当参数
较小或较大时,引入的二进制潜在变量
等于0或1。另外,
的先验遵循伯努利分布,
,它包含了关于模型中需要包含哪些
的不确定性。这里,
以及
服从
,其中
产生唯一的超先验
。
由此,后验分布有如下形式
潜在的包含指标
被视为“缺失数据”。由于这个函数是不可观察的,它在每次迭代中都被给定观察数据和当前参数估计的条件期望所取代,即所谓的E步。在第k次迭代中,EM算法通过迭代最大化下面的目标函数来间接最大化
,
其中
表示条件期望
。这一步骤也就是我们算法中期望的E步计算。对于上述共轭“spike-and-slab”混合分层先验公式,目标函数可以分离为
其中
如在 [14] 中所讨论的,
可以计算为
其中
函数
中的期望可以计算为
(1)
在M步中,我们分别最大化目标函数
和
,来分别更新
和超参数
。通过在这两个步骤之间迭代,EM算法生成了一系列参数估计。下降搜索方案通常需要前向模型的梯度信息,并会陷入非线性非凸目标函数 [15] 的局部最小值。
2.3. Langevin动力学MCMC
如上一节EMVS方法所介绍的,
的优化目标函数
,通过最大化目标函数可得到
的值,即
其中
为一个对角矩阵
,其对角元素由方程(1)计算。我们借鉴了论文 [16] [17] 的思想,利用朗之万动力学MCMC方法更新目标参数
。动力学被定义为
(2)
其中
是一个任意的对称正定矩阵,
是一个标准的n维布朗运动,它可以帮助粒子
逃离局部域,探索全局域。我们使用Euler-Maruyama格式 [18] 来离散方程(2),构造马尔可夫链
其中,
是时间步长,
。预处理矩阵
被设置为
或者在
点处的局部逆黑森 [19]
,以指导采样过程中的更新方向,其中
超参数
和
分别通过最大化
和
来更新。综上所述,算法1列出了未知数后验的采样。我们在后面的数值例子中讨论了预处理矩阵
的影响。
Algorithm 1. EMVS方法下的DCT系数识别
3. 数值算例
在本节中,我们使用所提出的方法来反演识别未知源项场。我们考虑地下水流模型,它由下面的抛物线方程来描述,
(3)
其中模型求解区域为
,
。我们的目标是反演未知源函数
,我们将边界条件设为齐次Dirichlet边界,初始条件设为
,
。观测数据为T时刻区域边界上的通量,即
,其中
为单位外法向量。
为了进行模拟,我们需要在有限维空间中表示函数
。因此我们沿用前文介绍的离散余弦变化再参数化技术,将源函数投影到由p个DCT基函数跨越的空间上。即在DCT域上,源函数可以表示为
其中
是待反演的未知参数,
是截断的DCT基函数。由于方程(3)的解线性依赖于源函数,我们有以下近似:
其中
为敏感性矩阵,由以下表达式定义:
在这里
表示右端源项为
时,正演模型的相关输出变量,
为矩阵
的第i列。
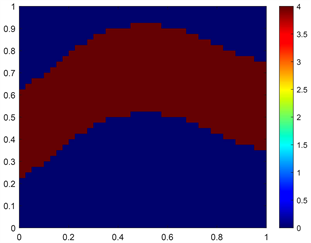
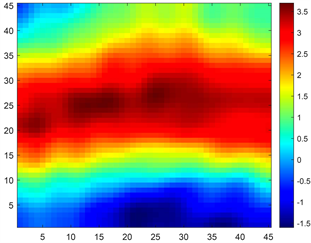
观测数据由真实的
产生,真实的
如图1所示。在生成观测数据时,我们采用的物理网格为45 × 45,时间上的离散步长为
。为了避免出现“反问题陷阱”(inverse crime)这一现象在反演过程中求解正问题所采用的时间步长为
。我们将应用前文提到的贝叶斯方法来反演未知的随机场。
 (a) (b)
(a) (b)
Figure 1. (a) The spatial distribution of the true
and (b) the DCT coefficients of the true
图1. (a)
的真实分布情况,(b) 真实
对应的DCT系数
3.1. 反演识别结果
在本章数值实验中,选择较为低频的二维DCT基函数,参数化基函数数量设为120,即未知参数
的维数为
。EMVS中待求参数初始值设置为
,
,
。“spike and slab”混合分层先验分布参数设定分别为
,
,调整步长
。我们按照算法1,在不同的预处理矩阵条件下,分别抽取了30,000个样本,其结果如图2所示。
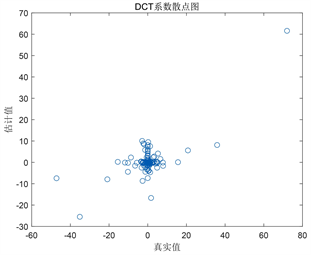
从图中可以看出,经过预处理的Langevin MCMC方法可以得到通道的大致位置及形状,即使是在观测数据有限且聚集在边缘的情况下,而未经过预处理的Langevin MCMC方法的表现不尽如人意。由图2第二列的可以看出,在带预处理的Langevin MCMC方法下,其散点大致分布在
这条线上,绝大多数系数被截断为0,即散点聚集在
的线上。重要的DCT基函数大多在模型中正确保留下来,即相应系数没有被估计为0。未预处理的Langevin MCMC算法,其中一些显著不为0的参数散点同样大致分布在
这条线上,但其模型保留了过多变量,即过多的基函数没有被截断,这些基函数中包含了大量高频的DCT基向量。
 (a) (b)
(a) (b)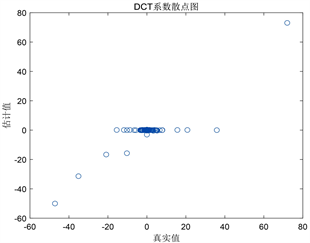
 (c) (d)
(c) (d)
Figure 2. The first row is the results from the unpreconditioned Langevin MCMC method,the second row is the results from the inverse Hessian preconditioned Langevin MCMC method. The first column is the mean of
, while the second column is the comparison between the estimated
and the reference
图2. 第一行为未经预处理的Langevin MCMC获得的结果,第二行为以逆Hessian矩阵为预处理矩阵的Langevin MCMC方法获得的结果。第一列为
的均值,第二列为
的估计值与参考值之间的对比图
3.2. 收敛效果分析
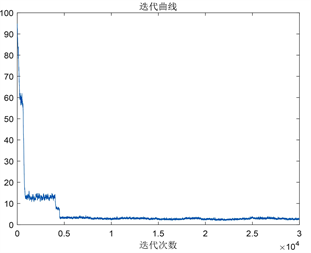
按照算法1的原理和步骤,我们集合每次迭代中代数式
的值来刻画迭代曲线。迭代运算30,000次得到未经过预处理与经过预处理的方法各自相应的反演迭代曲线如图3所示。我们发现无预处理算法的迭代曲线(图3(a))始终没有进入稳定收敛区域,只在迭代初期曲线有明显剧烈下降。经过预处理的Langevin MCMC算法在前5000次迭代中已经急剧下降,并接近迭代最终值,这说明在算法中加入预处理的步骤可以有效提高计算的效率。
 (a) (b)
(a) (b)
Figure 3. The plot of the objective function Q1 against the iteration number, resulted from: (a) the unpreconditioned Langevin MCMC, (b) the Langevin MCMC with the inverse Hessian as the preconditioned matrix
图3. 目标函数Q1随迭代次数变化曲线图,结果来自于:(a) 未经预处理的Langevin MCMC方法,(b) 预处理矩阵为逆Hessian矩阵的Langevin MCMC方法
3.3. 模型预测
上一节我们发现经过预处理的Langevin MCMC方法对源函数的反演效果显著优于未经过预处理的Langevin MCMC方法,本节我们针对两种方法分别反演得到的待求参数后验样本,将参数
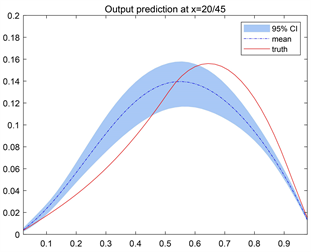
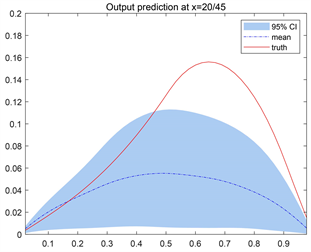
的样本代入到正演模型中,来得到相应的观测
的后验样本并对比。为了显示我们仅依靠网格边缘的部分观测数据,对参数的估计可靠性,尤其是在距离观测位置很远的中部,我们在图的中间位置任意选取2条函数线
和
,分别得到相应的预测输出值,同时与真实值作对比。
 (a) (b)
(a) (b)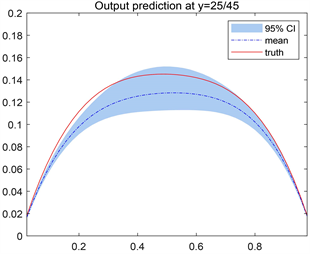
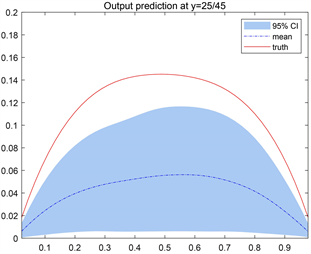 (c) (d)
(c) (d)
Figure 4. Predictions of the outputs for the unpreconditioned and inverse Hessian preconditioned Langevin MCMC method at (a, b)
(c, d)
. The first column is from the unpreconditioned method, while the second column is from the inverse Hessian preconditioned method
图4. 未经预处理和逆Hessian预处理Langevin MCMC方法下的输出变量分别在(a, b)
(c, d)
处的预测情况。第一列为未经预处理方法的结果,第二列为经过预处理的结果
预测结果如图4所示,其中红色实线代表所选取位置上的真实值,蓝色虚线是将所提出方法反演得到的未知参数
的后验样本代入观测方程后得到的相应位置的输出样本均值,红色实线与蓝色虚线越靠近,说明数据预测结果越好。蓝色阴影区域是预测均值的95%置信区间。可以看到,在任何预测位置上,经过预处理Langevin MCMC算法反演的未知参数
得到的预测结果其预测值与真实值都较为吻合,大多数都落在95%置信区间内,因此认为我们的方法反演出来的参数估计结果可以用于模型预测。有预处理的Langevin MCMC方法所求未知参数预测得到的压力值较无预处理的Langevin MCMC方法所求未知参数压力预测值与真值更加接近。利用所提出的方法得到的对源项的反演结果可以用于模型预测,得到的预测值与真实值较吻合,预测精度较高。从预测结果来看,运用有预处理的Langevin MCMC方法所求未知参数求得的预测压力值与真值更加接近,结果精度更高。
4. 总结
本文在贝叶斯框架下,构建了一套地下水流非高斯源项场反演识别研究方法体系,该体系结合了数理方程正反演、离散余弦变化、再参数化、贝叶斯推断、Langevin MCMC、EMVS、预处理技术等多种理论与方法,综合运用理论分析和数值实验相结合的研究方式,针对地下水流非高斯参数场反演识别研究前沿中尚待解决的科学问题开展了系统性研究,丰富和拓展了地下水流非高斯源项场反演识别的理论基础,为实际地下油藏勘探、油气资源开发提供了重要参考。本文研究的假想例子为二维地下水非高斯源项场,条件较为简单。今后研究中,希望在更复杂的条件下进行识别研究:如地下水非线性渗透场,更大的观测误差,更少的观测数据等。
致谢
欧娜感谢国家自然科学基金委11901060,湖南省自然科学基金2021JJ40557以及湖南省教育厅优秀青年项目22B0333的支持;宋晓燕感谢国家自然科学基金委12301551,湖南省自然科学基金2022JJ40125以及湖南省教育厅优秀青年项目22B0635的支持。
NOTES
*通讯作者。