1. 引言
雷雨大风是指平均风力值大于17.2 m/s,且降雨量大于20 mm的一种强对流天气 [1] ,具有突发性强、发生范围小、持续时间短、破坏力强等特点。由于雷雨大风天气的发生极为局促和突然,常常给农业、林业、畜牧业造成巨大的经济损失,严重影响人民群众的正常生活。
目前,国内外已有一些研究工作使用机器学习方法针对雷雨大风进行短临预报。王兴等 [2] 基于深度神经网络天气识别算法,以表征回波移动路径的光流图像和雷达回波图像作为输入,对雷雨大风天气进行识别,降低了误报率。Jiang Y等 [3] 提出了一种基于多源卷积神经网络的预测方法,提升了预测准确率。路志英等 [4] 提出基于物理量参数和深度学习模型DBNs的短时强降水天气识别模型,对于短时强降水的命中率、误警率和临界成功指数,都有着较好的表现。
虽然机器学习方法相较于传统计量模型,能够处理高维度、非线性和复杂的数据集,但由于气象问题具有不确定性和时空差异性,单一的机器学习方法难以适应错综复杂的变化。基于此,本文提出一种基于AutoGluon自动机器学习的雷雨大风预测方法,该方法可以通过一定的策略建立方法集成,不仅能够得到拟合效果更好、精度更高的预测模型,而且无需反复调整参数 [5] 。本文将气象天气中常见的降雨和大风作为研究对象,基于真实的气象数据集,使用AutoGluon方法,完成辽宁地区未来3小时内的多个站点的雷雨大风天气预测,及时地进行预报预警。
2. 气象数据集的构建
本文以辽宁地区的降雨和大风作为研究对象,主要使用以下两类资料作为基础数据:一类是来自美国气象环境预报中心NCEP (National Centers for Environmental Prediction)的历史再分析资料中的数据,其中特征属性包含了与研究对象降雨和大风相关的属性,有位势高度、纬向风速等预报数据;另一类是来自辽宁省地面观测站获取的ECMWF数值预报资料中的历史实况数据,主要包括降水量和大风值等数据资料。
研究历史再分析资料中与雷雨大风有关的特征要素,选取46个相关的属性,接着对其进行解析和预处理等操作;同样,地面实况观测数据资料也要经过数据处理,得到有效的降雨量和大风值数据。这样就生成了两类数据集,因为雷雨大风天气大多集中在夏季,故两类数据集时间均选择2015~2018年中5~9月的数据进行导出构建。除此之外,因两个数据集的时区不同,还需要经过时间的转化。最后,通过经纬度和时间这两个匹配条件(如图1所示),将两类数据集进行匹配合并。

Figure 1. Construction of two types of datasets
图1. 两类数据集的构建
本文将当前时刻地面观测数据与3小时前的NECP历史再分析数据进行匹配,建立了实验所需要的完整的训练样本数据集,用于预测未来3小时辽宁地区的雷雨大风情况。其中,每一条数据包含的50项属性从左至右分别为站点编号(StationNum)、观测时间(ObservTimes)、温度(MaxTemp)、风向(WindDirect)、风速(WindVelocity)、湿度(RelHumidity)、气压(StationPress)、降雨(Precipitation)、大风(MaxWindV)以及其他历史再分析数据属性特征,如HGT1000、RH500、TMP200、UGRD1000、VGRD500、VVEL850等。
3. 雷雨大风预测模型自动化建立
3.1. AutoGluon方法概述
AutoGluon是一种自动机器学习方法,能自动实现数据特征选择并进行模型训练,依赖于融合多个不需要超参数搜索的模型,支持图像、表格、文本等多种格式数据的处理,适用于文本分类、图像分类、对象检测等多种任务类型 [6] 。本文使用AutoGluon中的表格预测功能(AutoGluon-Tabular)实现雷雨大风的预测,完成自动化模型处理、训练。
3.2. AutoGluon模型准备
为了解决前馈神经网络或卷积神经网络架构在处理表格数据方面表现不佳的问题,AutoGluon使用如图2所示的新型神经网络架构 [7] 。
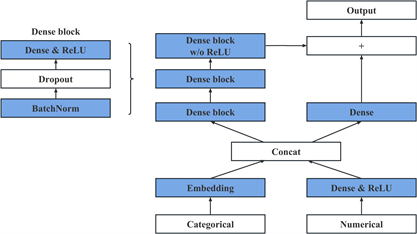
Figure 2. New network architecture of AutoGluon
图2. AutoGluon的新型网络架构
在新型网络架构中,网络为每个类别特征都引入一个嵌入层,其中嵌入维数根据特征中唯一类别的数量按比例选择。类别特征的嵌入与数值特征连接成一个矢量,该矢量既被馈送到3层前馈网络,也通过线性的跳跃连接(skip-connection)直接连接到输出预测。神经网络中的每个密集块包括几个卷积层、池化层、ReLU激活函数层、批归一化(batch normalization)层和随机失活正则化(dropout)。
此外,本文研究的自动机器学习预测模型中,将LightGBM提升树算法、CatBoost、随机森林算法(Random Forest)、极端随机树算法(Extremely Randomized Trees)、k最近邻算法(KNN)、XGBoost以及加权集成模型(WeightedEnsemble_L2)等多种模型作为基础模型。其中XGBoost是对原始版本的GBDT算法的改进,而LightGBM和CatBoost则是在XGBoost基础上做了进一步的优化,在精度和速度上都有各自的优点。
3.3. AutoGluon模型训练
算法采用两大运算策略:多层堆栈(stack)集成、重复k-折交叉装袋(bagging),以此来进一步提高预测准确度和减少过拟合。
(1) 模型构建。堆栈集成,将堆栈器模型输出的预测作为输入,提供给其他更高层堆栈器模型。将其所有基础层模型类型重新用作堆栈器,堆栈模型的最后一层使用集成选择以加权的方式,聚合堆栈模型的预测。
(2) 模型训练。将数据随机划分为k个不相交的块,随机选取一块为验证集,其余部分为测试集。然后使用堆栈模型,训练和测试之前准备的基础模型,在堆栈的所有层对所有模型进行k-折交叉装袋。
(3) 通过重复上述过程,执行多次k-折交叉装袋,得到多层堆栈模型。
(4) 模型测试,确定最佳模型。
本文采取的模型结构如图3所示,图中显示了AutoGluon的多层堆栈策略,这里使用两个堆栈层和n种类型的基础学习器。
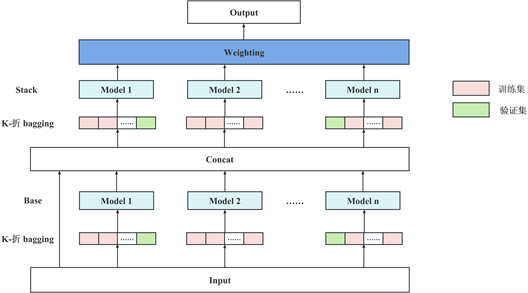
Figure 3. AutoGluon’s multi-layer stack strategy
图3. AutoGluon的多层堆栈策略
图3中,第一层有多个基础模型,其输出被级联,然后被馈送到下一层,而下一层本身由多个堆栈模型组成。然后,这些堆栈器充当附加层的基础模型。
3.4. 评价指标
本文对基于自动机器学习的雷雨大风预测方法的评价指标包括Pearson相关系数(PCCs)、均方根误差(RMSE)、平均绝对误差(MAE)和R2_score等统计误差评估雷雨大风预测情况,具体公式见式(1)~式(4):
(1)
(2)
(3)
(4)
其中,y表示需要预测的降水值或大风值,在式(1)~式(4)中,m表示雷雨大风数据集总条数,
表示真实的y值,
表示模型预测的y值。PCCs取值范围[−1, 1],越接近1,效果越好。其余指标范围参见文献 [8] 。
从气象局提供的参考资料可知,雷雨大风是指平均风力值大于17.2 m/s且降雨量大于20 mm的一种强对流天气。具体判断有无雷雨大风现象的方法如图4。
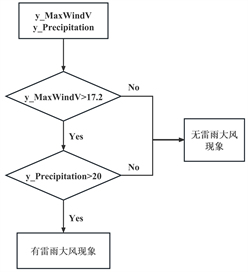
Figure 4. Judging whether there is a thunderstorm or strong wind phenomenon
图4. 判断是否有雷雨大风现象
TS评分(True Skill Statistic)是一种用于评估气象模型预报性能的方法,其取值范围在0到1之间,TS评分越高,表示模型预报的准确性越高 [9] 。此外,权威的检验预测效果的统计量还包括:命中率(POD)、准确率(ACC)、漏报率(FNR)、误报率(FAR)。其中,本文研究使用的各指标代表含义如下:
(1) TP为实际有雷雨大风且预测有雷雨大风;
(2) FP为实际有雷雨大风而预测无雷雨大风;
(3) FN为实际无雷雨大风而预测有雷雨大风;
(4) TN为实际无雷雨大风且预测也无雷雨大风。
各指标的公式如式(5)~式(9):
(5)
(6)
(7)
(8)
(9)
4. 实验结果与分析
本研究针对于辽宁地区的雷雨大风天气问题,建立了雷雨大风数据集,使用基于多层堆栈集成、重复k-折交叉装袋策略的AutoGluon自动机器学习方法建立雷雨大风预测模型。
AutoGluon以特定选择的顺序(fit_order)训练各个模型。在训练过程中,AutoGluon根据每个模型的性能和复杂度等因素进行评估和比较,以便选择出最优的模型。其主要过程首先是训练性能可靠的模型,如RandomForest模型,然后逐步训练计算成本更高但可靠性较低的模型,如KNN模型,这样可以在特定成本或时间预算下获得最佳精度。同时,在本实验中,堆栈层数没有超过3层,保证了训练效率。
为了验证AutoGluon方法在预测雷雨大风方面的效果,将AutoGluon方法预测的结果与决策树(Decision Tree)、线性模型(Linear)、K-近邻(KNN)、随机森林(RandomForest)、LGBM、XGBoost、支持向量机(SVM)这些常见的机器学习模型进行对比实验,具体结果见表1。

Table 1. Comparison of statistical error indicators between autogluon and other machine learning models
表1. AutoGluon与其他机器学习模型统计误差指标对比
从表1可知,无论是大风值预测还是降水值预测,RMSE和MAE指标结果数值均为最低,R2和PCCs评价指标数值均最接近于1。表明AutoGluon算法构建的雷雨大风预测模型的统计误差指标明显好于其他模型的效果。
接着,使用气象学中常使用的TS评分评价模型。其中,部分实验样本的分析结果如表2所示。
Table 2. Analysis results of part of the experimental samples
表2. 部分实验样本分析结果
在多项评估指标中,除了本文的AutoGluon方法以外,预测效果最好的机器学习模型是决策树模型,其中R2_score和PCCs已经很接近AutoGluon方法,其次是XGBoost方法,该方法在大风预测方面效果良好,但其在降水方面的预测效果不佳。其余方法(如SVM、KNN)均表现效果一般。使用TS评分、POD、ACC、FNR、FAR等描述准确率的指标,将这三种方法作对比实验,具体结果如表3。
Table 3. Comparison of accuracy metrics between AutoGluon and other machine learning models
表3. AutoGluon与其他机器学习模型准确率指标对比
从上表可知,使用AutoGluon方法构建雷雨大风预测模型具有很好的效果。在TS评分方面,该方法比Decision Tree和XGBoost分别高出10.99%和15.53%。同时,AutoGluon方法构建雷雨大风预测模型从各种指标来看,均属于最佳指标。另外,通过多次的AutoGluon方法构建模型,并进行同类型的指标评估,评估效果相差不到1%,说明使用AutoGluon自动机器学习方法构建雷雨大风预测模型,具有很强的鲁棒性。
5. 结论
灾害性天气中的雷雨大风天气,持续困扰和影响人们的正常生活并对社会造成不同程度的危害,但对其进行准确预测亦面临巨大挑战。本文旨在深入探讨提高对此类天气的预测精度。基于真实的气象数据集,研究使用自动机器学习方法构建雷雨大风预测模型,并通过实验验证了研究工作的有效性。实验结果表明,基于AutoGluon自动机器学习的预测方法对辽宁地区未来3个小时的雷雨大风预测具有较好的效果,高于部分主要机器学习模型的预测精度。
基金项目
辽宁省高等学校优秀科技人才支持计划(LR15045);辽宁省教育厅科学研究经费面上项目(LJKZ0139);辽宁省气象台科技项目(201903256, 201803276)。